
Utiliser des illustrations pour entraîner un système de vision par ordinateur sans image à reconnaître de vraies photos
Vous avez probablement entendu dire qu'une image vaut mille mots, mais un grand modèle de langage (LLM) peut-il donner une idée s'il n'a jamais vu d'images auparavant ?
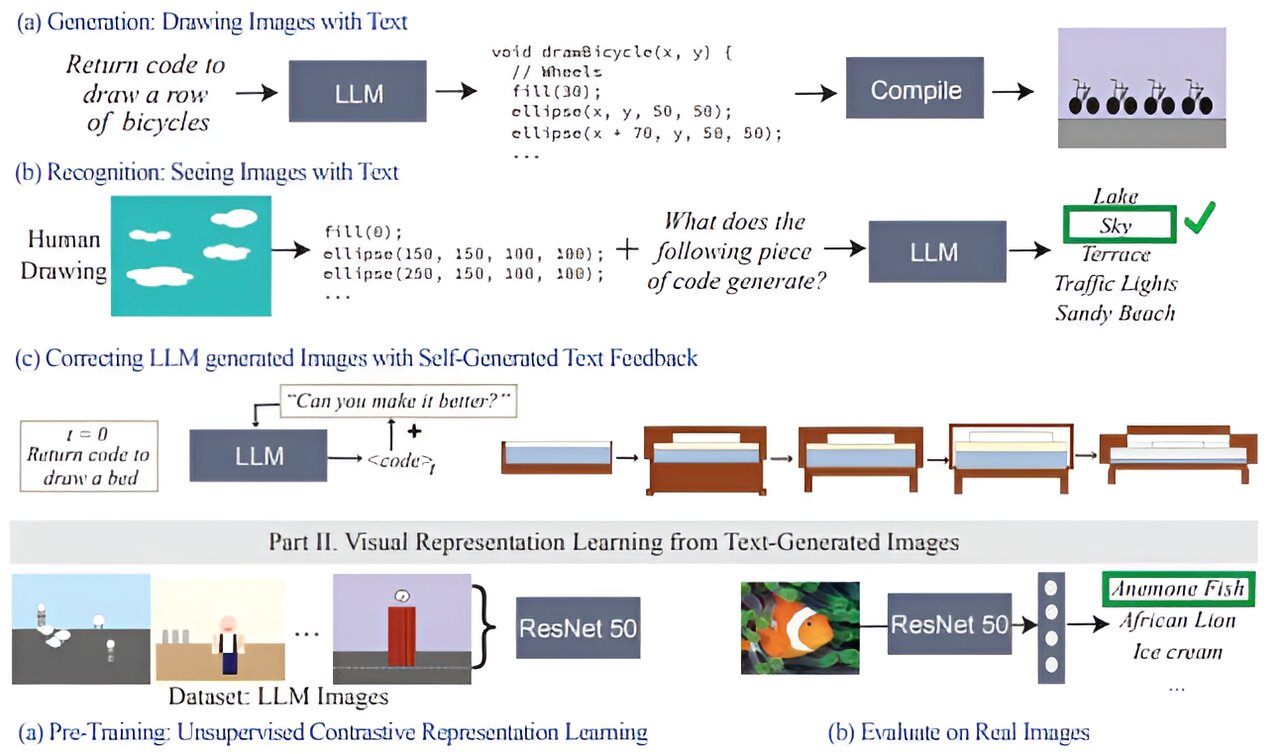
Il s’avère que les modèles linguistiques formés uniquement sur le texte ont une solide compréhension du monde visuel. Ils peuvent écrire du code de rendu d'images pour générer des scènes complexes avec des objets et des compositions intrigantes. Et même lorsque ces connaissances ne sont pas utilisées correctement, les LLM peuvent affiner leurs images. Des chercheurs du laboratoire d'informatique et d'intelligence artificielle (CSAIL) du MIT ont observé cela en invitant les modèles de langage à auto-corriger leur code pour différentes images, les systèmes améliorant ainsi leurs simples dessins clipart à chaque requête.
La connaissance visuelle de ces modèles de langage provient de la façon dont des concepts tels que les formes et les couleurs sont décrits sur Internet, que ce soit dans le langage ou dans le code. Lorsqu'on leur donne une direction telle que « dessiner un perroquet dans la jungle », les utilisateurs parcourent le LLM pour réfléchir à ce qu'il a lu dans les descriptions précédentes.
Pour évaluer le niveau de connaissances visuelles des LLM, l'équipe CSAIL a construit un « bilan de vision » pour les LLM : à l'aide de leur « ensemble de données sur l'aptitude visuelle », ils ont testé les capacités des modèles à dessiner, reconnaître et auto-corriger ces concepts. En collectant chaque version finale de ces illustrations, les chercheurs ont formé un système de vision par ordinateur qui identifie le contenu de vraies photos.
Leurs travaux sont publiés sur arXiv serveur de préimpression.
« Nous entraînons essentiellement un système de vision sans utiliser directement de données visuelles », explique Tamar Rott Shaham, co-auteur principal de l'étude et postdoctorant en génie électrique et informatique (EECS) au MIT au CSAIL. « Notre équipe a interrogé des modèles de langage pour écrire des codes de rendu d'images afin de générer des données pour nous, puis a formé le système de vision pour évaluer les images naturelles. Nous avons été inspirés par la question de savoir comment les concepts visuels sont représentés à travers d'autres supports, comme le texte. Pour exprimer leur connaissances visuelles, les LLM peuvent utiliser le code comme terrain d'entente entre le texte et la vision.
Pour créer cet ensemble de données, les chercheurs ont d’abord interrogé les modèles afin de générer du code pour différentes formes, objets et scènes. Ensuite, ils ont compilé ce code pour restituer des illustrations numériques simples, comme une rangée de vélos, montrant que les LLM comprennent suffisamment bien les relations spatiales pour dessiner les deux-roues dans une rangée horizontale. Comme autre exemple, le modèle a généré un gâteau en forme de voiture, combinant deux concepts aléatoires. Le modèle de langage a également produit une ampoule lumineuse, indiquant sa capacité à créer des effets visuels.
« Notre travail montre que lorsque vous interrogez un LLM (sans pré-formation multimodale) pour créer une image, il en sait beaucoup plus qu'il n'y paraît », explique le co-auteur principal, Ph.D. EECS. étudiant et membre du CSAIL, Pratyusha Sharma. « Disons que vous lui avez demandé de dessiner une chaise. Le modèle connaît d'autres choses sur ce meuble qu'il n'a peut-être pas immédiatement rendues. Les utilisateurs peuvent donc interroger le modèle pour améliorer le visuel qu'il produit à chaque itération. Étonnamment, le modèle peut enrichir le dessin de manière itérative en améliorant considérablement le code de rendu. »
Les chercheurs ont rassemblé ces illustrations, qui ont ensuite été utilisées pour former un système de vision par ordinateur capable de reconnaître des objets dans de vraies photos (même s’ils n’en avaient jamais vu auparavant). Avec ces données synthétiques générées par texte comme seul point de référence, le système surpasse les autres ensembles de données d'images générés de manière procédurale et formés avec des photos authentiques.
L’équipe CSAIL estime que combiner les connaissances visuelles cachées des LLM avec les capacités artistiques d’autres outils d’IA tels que les modèles de diffusion pourrait également être bénéfique. Des systèmes comme Midjourney manquent parfois du savoir-faire nécessaire pour peaufiner systématiquement les détails les plus fins d'une image, ce qui rend difficile le traitement de demandes telles que la réduction du nombre de voitures photographiées ou le placement d'un objet derrière un autre. Si un LLM avait esquissé au préalable le changement demandé pour le modèle de diffusion, la modification résultante pourrait être plus satisfaisante.
L’ironie, comme le reconnaissent Rott Shaham et Sharma, est que les LLM ne parviennent parfois pas à reconnaître les mêmes concepts qu’ils peuvent dessiner. Cela est devenu évident lorsque les modèles ont identifié de manière incorrecte les recréations humaines d’images dans l’ensemble de données. Des représentations aussi diverses du monde visuel ont probablement déclenché des idées fausses sur les modèles de langage.
Alors que les modèles avaient du mal à percevoir ces représentations abstraites, ils ont fait preuve de créativité pour dessiner les mêmes concepts différemment à chaque fois. Lorsque les chercheurs ont demandé à plusieurs reprises aux LLM de dessiner des concepts tels que des fraises et des arcades, ils ont produit des images sous différents angles avec des formes et des couleurs variées, laissant entendre que les modèles pourraient avoir une véritable imagerie mentale de concepts visuels (plutôt que de réciter des exemples qu'ils avaient vus auparavant).
L’équipe CSAIL estime que cette procédure pourrait constituer une base de référence pour évaluer dans quelle mesure un modèle d’IA générative peut entraîner un système de vision par ordinateur. De plus, les chercheurs cherchent à étendre les tâches sur lesquelles ils contestent les modèles de langage. Quant à leur étude récente, le groupe du MIT note qu'ils n'ont pas accès à l'ensemble de formation des LLM qu'ils ont utilisés, ce qui rend difficile l'étude plus approfondie de l'origine de leurs connaissances visuelles. À l’avenir, ils ont l’intention d’explorer la formation d’un modèle de vision encore meilleur en laissant le LLM travailler directement avec celui-ci.
Sharma et Rott Shaham sont rejoints sur le journal par Stephanie Fu, ancienne affiliée du CSAIL, et Ph.D. EECS. les étudiants Manel Baradad, Adrián Rodríguez-Muñoz et Shivam Duggal, tous affiliés au CSAIL ; ainsi que le professeur agrégé du MIT Phillip Isola et le professeur Antonio Torralba.
Ils présentent leur article cette semaine à la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes.
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche, de l'innovation et de l'enseignement du MIT.