
Une nouvelle technique améliore la capacité de l'IA à cartographier l'espace 3D avec des caméras 2D
Les chercheurs ont développé une technique qui permet aux programmes d’intelligence artificielle (IA) de mieux cartographier les espaces tridimensionnels à l’aide d’images bidimensionnelles capturées par plusieurs caméras. Parce que la technique fonctionne efficacement avec des ressources informatiques limitées, elle est prometteuse pour améliorer la navigation des véhicules autonomes.
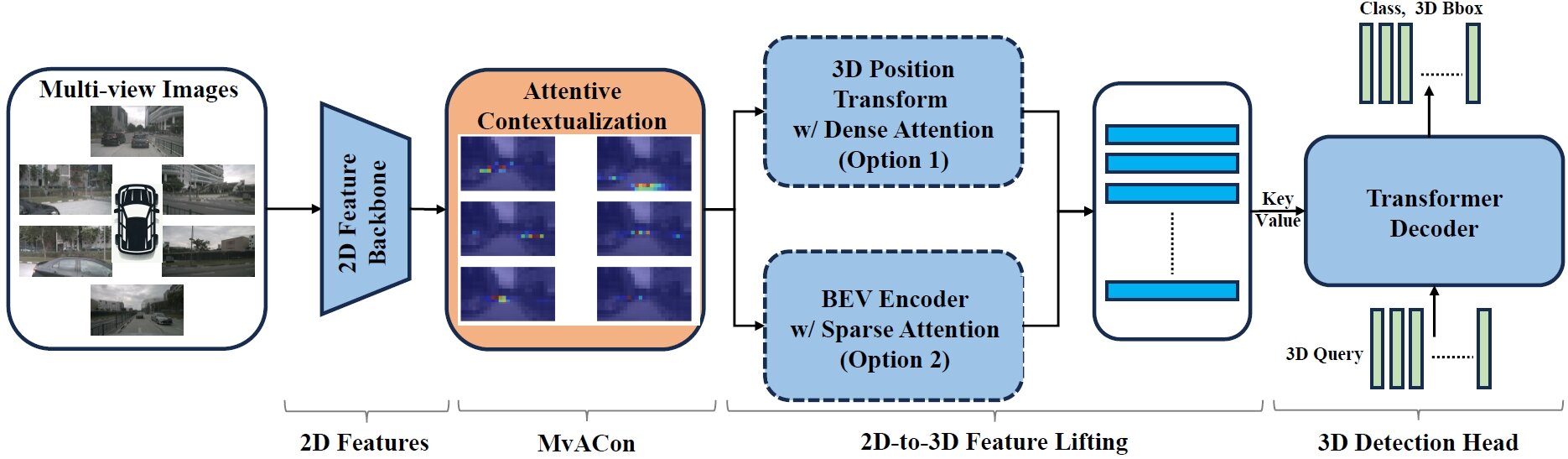
« La plupart des véhicules autonomes utilisent de puissants programmes d'IA appelés transformateurs de vision pour prendre des images 2D à partir de plusieurs caméras et créer une représentation de l'espace 3D autour du véhicule », explique Tianfu Wu, auteur correspondant d'un article sur ces travaux et professeur agrégé d'électricité et de technologie. génie informatique à la North Carolina State University. « Cependant, même si chacun de ces programmes d'IA adopte une approche différente, il reste encore beaucoup à faire.
« Notre technique, appelée Multi-View Attentive Contextualization (MvACon), est un complément plug-and-play qui peut être utilisé conjointement avec ces IA de transformateur de vision existantes pour améliorer leur capacité à cartographier des espaces 3D », explique Wu. « Les transformateurs de vision ne reçoivent aucune donnée supplémentaire de leurs caméras, ils sont simplement capables de mieux utiliser les données. »
MvACon fonctionne efficacement en modifiant une approche appelée Patch-to-Cluster attention (PaCa), que Wu et ses collaborateurs ont publiée l'année dernière. PaCa permet aux IA de transformateur d'identifier plus efficacement les objets dans une image.
« La principale avancée ici consiste à appliquer ce que nous avons démontré avec PaCa au défi de la cartographie de l'espace 3D à l'aide de plusieurs caméras », explique Wu.
Pour tester les performances de MvACon, les chercheurs l'ont utilisé en conjonction avec trois principaux transformateurs de vision : BEVFormer, la variante BEVFormer DFA3D et PETR. Dans chaque cas, les transformateurs de vision collectaient des images 2D provenant de six caméras différentes. Dans les trois cas, MvACon a considérablement amélioré les performances de chaque transformateur de vision.
« Les performances ont été particulièrement améliorées en matière de localisation d'objets, ainsi que de vitesse et d'orientation de ces objets », explique Wu. « Et l'augmentation de la demande de calcul liée à l'ajout de MvACon aux transformateurs de vision était presque négligeable.
« Nos prochaines étapes incluent le test de MvACon par rapport à des ensembles de données de référence supplémentaires, ainsi que par rapport à l'entrée vidéo réelle de véhicules autonomes. Si MvACon continue de surpasser les transformateurs de vision existants, nous sommes optimistes qu'il sera adopté pour une utilisation généralisée.
L'article, « Multi-View Attentive Contextualization for Multi-View 3D Object Detection », sera présenté le 20 juin lors de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes, qui se tiendra à Seattle, Washington.
Le premier auteur de l'article est Xianpeng Liu, un récent doctorant. diplômé de NC State. L'article a été co-écrit par Ce Zheng et Chen Chen de l'Université de Floride centrale ; Ming Qian et Nan Xue du groupe Ant ; et Zhebin Zhang et Chen Li du centre de recherche OPPO US.