
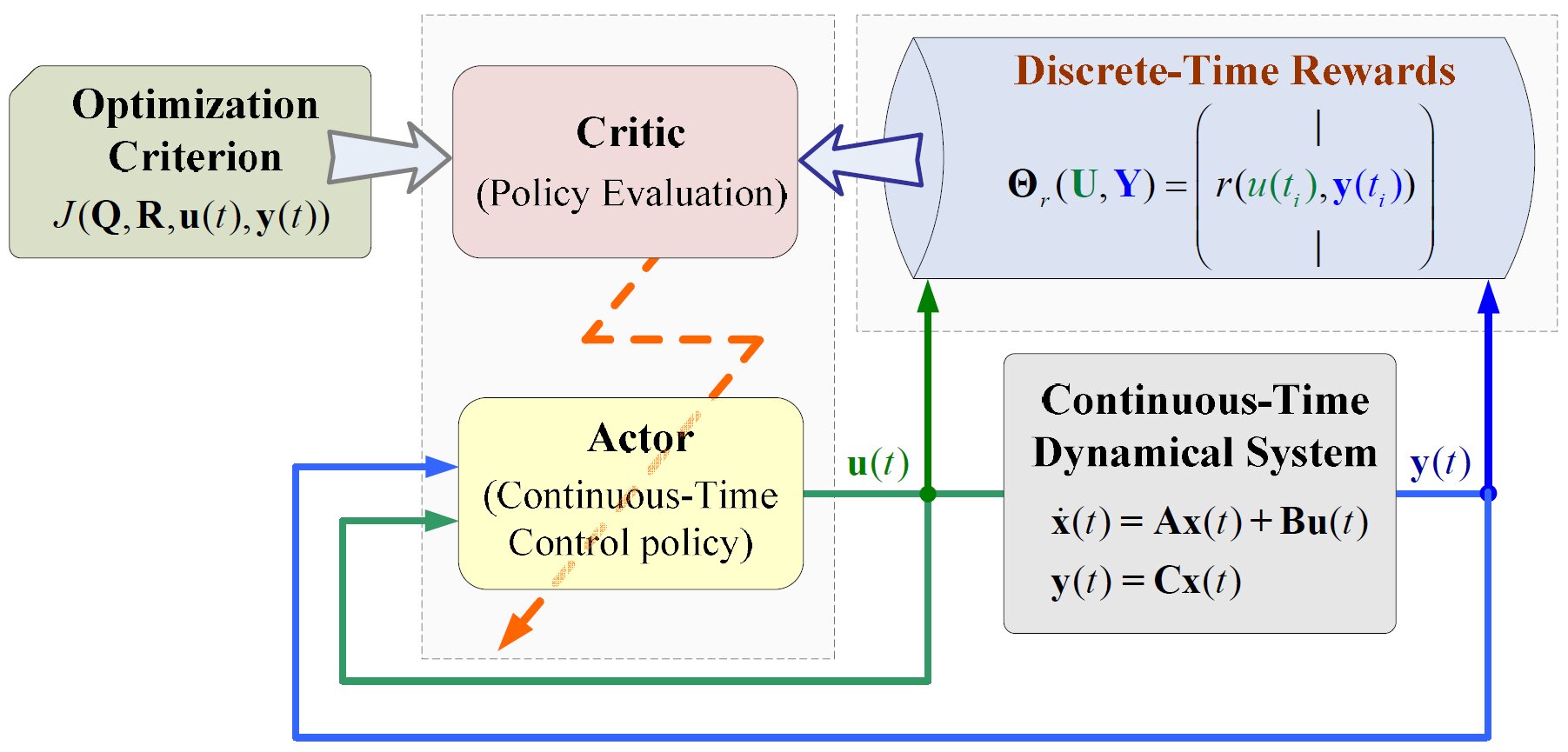
Les récompenses en temps discret guident efficacement l'extraction de la politique de contrôle optimale en temps continu à partir des données du système
Le concept de récompense est au cœur de l'apprentissage par renforcement et est également largement utilisé dans les sciences naturelles, l'ingénierie et les sciences sociales. Les organismes apprennent un comportement en interagissant avec leur environnement et en observant les stimuli gratifiants qui en résultent. L'expression des récompenses représente en grande partie la perception du système et définit l'état comportemental du système dynamique. Dans l'apprentissage par renforcement, trouver des récompenses qui expliquent les décisions comportementales des systèmes dynamiques est un défi ouvert.
L'objectif de ce travail est de proposer des algorithmes d'apprentissage par renforcement utilisant des récompenses à temps discret à la fois dans le temps continu et dans l'espace d'action, où l'espace continu correspond aux phénomènes ou comportements d'un système décrit par les lois de la physique. L'approche consistant à réintroduire les dérivées d'état dans le processus d'apprentissage a conduit au développement d'un cadre analytique pour l'apprentissage par renforcement basé sur des récompenses à temps discret, qui est essentiellement différent des cadres d'apprentissage par renforcement intégral existants.
« Lorsque l'idée de réinjecter la dérivée dans le processus d'apprentissage est apparue, cela a semblé comme un éclair. Et devinez quoi ? Cela est mathématiquement lié à l'apprentissage politique basé sur les récompenses en temps discret », explique le Dr Ci Chen, se souvenant de son moment Eurêka.
Sous la direction d'une récompense en temps discret, le processus de recherche de la loi de décision comportementale est divisé en deux étapes : l'apprentissage du signal par anticipation et l'apprentissage du gain par rétroaction. Dans leur étude, il a été constaté que la loi de décision optimale pour les systèmes dynamiques en temps continu peut être recherchée à partir des données en temps réel des systèmes dynamiques en utilisant la technique basée sur les récompenses en temps discret.

La méthode ci-dessus a été appliquée à la régulation de l’état du système électrique afin d’obtenir une conception optimale de la rétroaction de sortie. Ce processus élimine l'étape intermédiaire d'identification des modèles dynamiques et améliore considérablement l'efficacité du calcul en supprimant l'opérateur intégrateur de récompense du cadre d'apprentissage par renforcement intégral existant.
Cette recherche utilise un guidage par récompense à temps discret pour découvrir des stratégies d'optimisation pour les systèmes dynamiques à temps continu et construit un outil informatique pour comprendre et améliorer les systèmes dynamiques. Ce résultat peut jouer un rôle important dans les sciences naturelles, l'ingénierie et les sciences sociales.
L'ouvrage est publié dans la revue Ouverture nationale des sciences.
Cette étude est dirigée par une équipe internationale de scientifiques comprenant le Dr Chen (École d'automatisation, Université de technologie du Guangdong, Chine), le Dr Lihua Xie (École d'ingénierie électrique et électronique, Université technologique de Nanyang, Singapour) et le Dr Shengli Xie (Laboratoire conjoint Guangdong-HongKong-Macao pour la fabrication discrète intelligente, Laboratoire clé du Guangdong pour les technologies de l'information IoT, Chine), co-contribués par le Dr Yilu Liu (Département de génie électrique et d'informatique, Université du Tennessee, États-Unis) et le Dr Frank L. Lewis (UTA Research Institute, Université du Texas à Arlington, États-Unis).