
Les ingénieurs logiciels développent un moyen d'exécuter des modèles de langage d'IA sans multiplication matricielle
Une équipe d'ingénieurs logiciels de l'Université de Californie, en collaboration avec un collègue de l'Université de Soochow et un autre de LuxiTec, a développé un moyen d'exécuter des modèles de langage d'IA sans recourir à la multiplication matricielle. L'équipe a publié un article sur arXiv serveur de prépublication décrivant leur nouvelle approche et son efficacité lors des tests.
À mesure que la puissance des LLM tels que ChatGPT a augmenté, les ressources informatiques dont ils ont besoin ont également augmenté. Une partie du processus d'exécution des LLM implique d'effectuer une multiplication matricielle (MatMul), où les données sont combinées avec des poids dans des réseaux neuronaux pour fournir probablement les meilleures réponses aux requêtes.
Très tôt, les chercheurs en IA ont découvert que les unités de traitement graphique (GPU) étaient parfaitement adaptées aux applications de réseaux neuronaux, car elles peuvent exécuter plusieurs processus simultanément, dans ce cas, plusieurs MatMuls. Mais désormais, même avec d’énormes clusters de GPU, les MatMuls sont devenus des goulots d’étranglement à mesure que la puissance des LLM augmente avec le nombre de personnes qui les utilisent.
Dans cette nouvelle étude, l’équipe de recherche affirme avoir développé un moyen d’exécuter des modèles linguistiques d’IA sans avoir besoin d’effectuer MatMuls – et de le faire tout aussi efficacement.
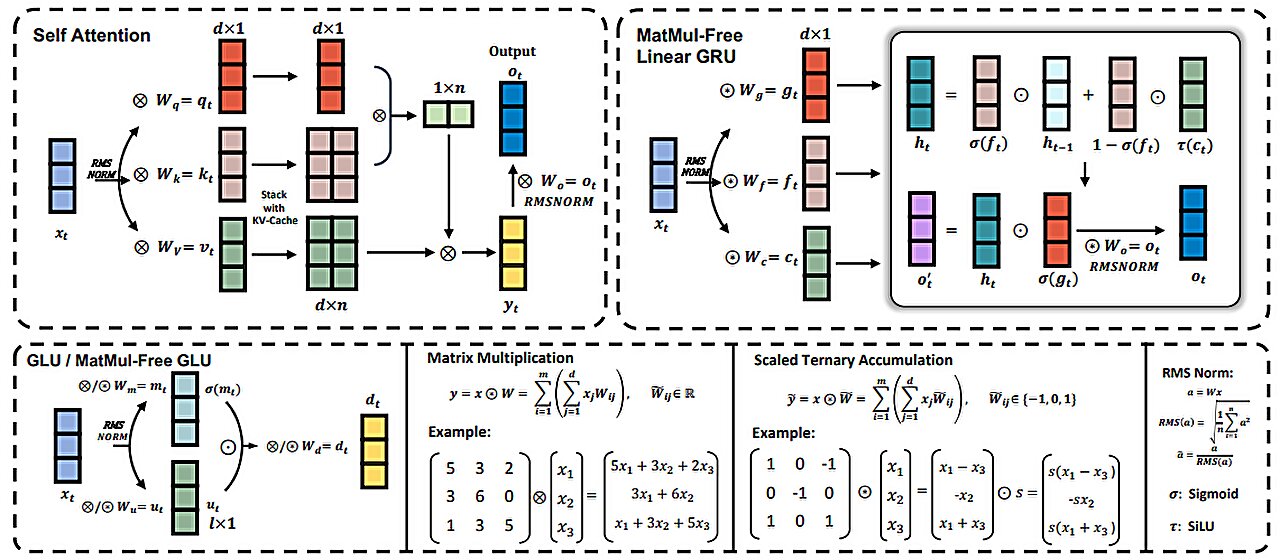
Pour réaliser cet exploit, l'équipe de recherche a adopté une nouvelle approche de la façon dont les données sont pondérées : ils ont remplacé la méthode actuelle qui repose sur des virgules flottantes de 16 bits par une autre qui n'en utilise que trois : {-1, 0, 1} ainsi que de nouvelles fonctions. qui effectuent les mêmes types d’opérations que la méthode précédente.
Ils ont également développé de nouvelles techniques de quantification qui ont contribué à améliorer les performances. Avec moins de poids, moins de traitement est nécessaire, ce qui entraîne un besoin de puissance de calcul moindre. Mais ils ont également radicalement changé la façon dont les LLM sont traités en utilisant ce qu'ils décrivent comme une unité récurrente linéaire sans MatMul (MLGRU) à la place des blocs transformateurs traditionnels.
En testant leurs nouvelles idées, les chercheurs ont découvert qu'un système utilisant leur nouvelle approche atteignait des performances comparables à celles des systèmes de pointe actuellement utilisés. Dans le même temps, ils ont constaté que leur système consommait beaucoup moins de puissance de calcul et d’électricité que ce n’est généralement le cas avec les systèmes traditionnels.