
Les gens ont du mal à distinguer les humains de ChatGPT dans des conversations de chat de cinq minutes, selon des tests
Les grands modèles linguistiques (LLM), tels que le modèle GPT-4 qui sous-tend la plateforme conversationnelle largement utilisée ChatGPT, ont surpris les utilisateurs par leur capacité à comprendre les invites écrites et à générer des réponses appropriées dans différentes langues. Certains d’entre nous peuvent alors se demander : les textes et les réponses générés par ces modèles sont-ils si réalistes qu’ils pourraient être confondus avec ceux écrits par des humains ?
Des chercheurs de l'Université de San Diego ont récemment tenté de répondre à cette question en exécutant un test de Turing, une méthode bien connue du nom de l'informaticien Alan Turing, conçue pour évaluer dans quelle mesure une machine fait preuve d'une intelligence humaine.
Les résultats de ce test, présentés dans un article pré-publié sur le arXiv serveur, suggèrent que les gens ont du mal à faire la distinction entre le modèle GPT-4 et un agent humain lorsqu'ils interagissent avec eux dans le cadre d'une conversation à deux.
« L'idée de cet article est en fait née d'un cours que Ben dirigeait en LLM », a déclaré Cameron Jones, co-auteur de l'article, à Tech Xplore.
« Au cours de la première semaine, nous avons lu des articles classiques sur le test de Turing et nous avons discuté de la question de savoir si un LLM pouvait le réussir et si cela importerait ou non. Pour autant que je sache, personne n'avait essayé à ce stade, alors j'ai J'ai décidé de construire une expérience pour tester cela dans le cadre de mon projet de classe, et nous avons ensuite lancé la première expérience exploratoire publique.
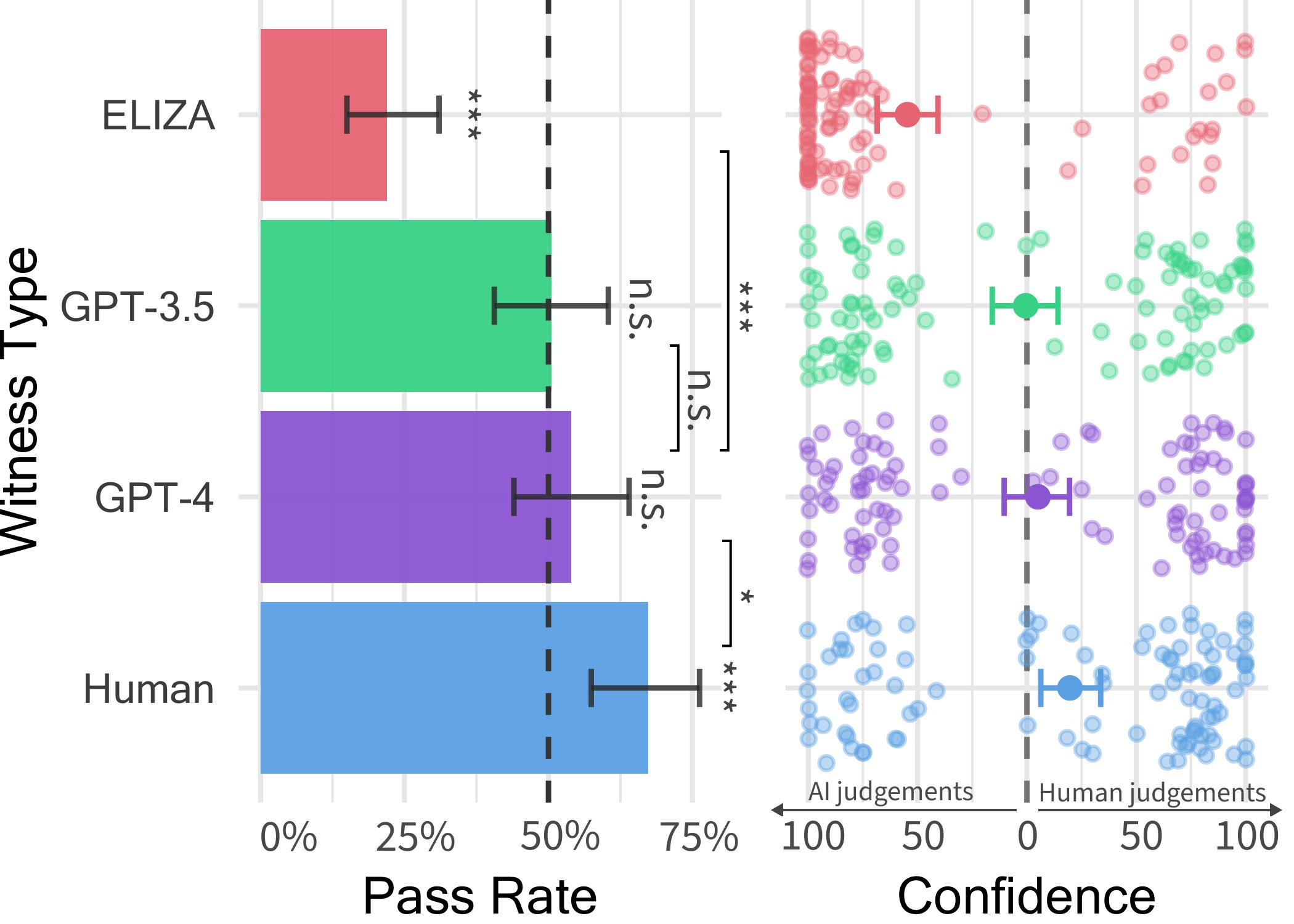
La première étude réalisée par Jones et supervisée par Bergen, professeur de sciences cognitives à l'UC San Diego, a donné des résultats intéressants, suggérant que GPT-4 pourrait passer pour un être humain dans environ 50 % des interactions. Néanmoins, leur expérience exploratoire n'a pas bien contrôlé certaines variables susceptibles d'influencer les résultats. Ils ont donc décidé de mener une deuxième expérience, donnant les résultats présentés dans leur récent article.
« Au fur et à mesure que nous menions les études, nous avons découvert que d'autres personnes faisaient également un excellent travail dans ce domaine, y compris le jeu 'humain ou non' de Jannai et al », a déclaré Jones. « Nous avons créé une version en ligne du jeu à 2 joueurs dans laquelle les participants humains seraient confrontés soit à un autre humain, soit à un modèle d'IA. »
Au cours de chaque essai du jeu à deux joueurs utilisé par Jones et ses collègues, un interrogateur humain interagit avec un « témoin », qui peut être soit un humain, soit un agent de l'IA. L'interrogateur pose au témoin une série de questions pour tenter de déterminer s'il est humain ou non.
 et des témoins (gris). L’une de ces quatre conversations a lieu avec un témoin humain, les autres ont lieu avec l’IA. Les verdicts des interrogateurs et les identités de la vérité terrain sont ci-dessous (pour permettre aux lecteurs de participer indirectement). [A) Verdict: Human (100% confidence) Took a while to Google Addis Ababa. Ground Truth: GPT-4; B) Verdict: AI (100% confidence) Long time for responses, wouldn't tell me a specific place they grew up. Ground Truth: Human; C) Verdict: Human (100% confidence) He seems very down to earth and speaks naturally. Ground Truth: GPT-3.5; D) Verdict: AI (67% confidence), Did not put forth any effort to convince me they were human and the responses were odd, Ground Truth: ELIZA.] Crédit : Jones et Bergen.")
« Les conversations ont duré jusqu'à cinq minutes et à la fin, l'interrogateur a déterminé s'il pensait que le témoin était un humain ou une IA », a expliqué Jones. « En cinq minutes, les participants pouvaient parler de tout ce qu'ils voulaient (sauf dire des choses injurieuses, que nous avons utilisé un filtre pour éviter). »
Dans ce jeu informatique à deux joueurs, les chercheurs ont déployé trois LLM différents comme témoins potentiels, à savoir les modèles GPT-4, GPT 3.5 et ELIZA. Ils ont constaté que même si les utilisateurs pouvaient souvent déterminer que les modèles ELIZA et GPT-3.5 étaient des machines, leur capacité à déterminer si GPT-4 était un humain ou une machine n'était pas meilleure que la probabilité qu'ils réussissent s'ils choisissaient au hasard (c'est-à-dire, par chance).
« Bien que les vrais humains aient eu plus de succès, persuadant les interrogateurs qu'ils étaient humains deux tiers du temps, nos résultats suggèrent que dans le monde réel, les gens pourraient ne pas être en mesure de dire de manière fiable s'ils parlent à un humain ou à un système d'IA. « , a déclaré Jones.
« En fait, dans le monde réel, les gens pourraient être moins conscients de la possibilité qu'ils parlent à un système d'IA, donc le taux de tromperie pourrait être encore plus élevé. Je pense que cela pourrait avoir des implications sur le genre de choses que l'IA peut faire. les systèmes seront utilisés, qu'il s'agisse d'automatiser les tâches en contact avec les clients, ou d'être utilisés à des fins de fraude ou de désinformation.
Les résultats du test de Turing réalisé par Jones et Bergen suggèrent que les LLM, en particulier le GPT-4, se distinguent à peine des humains lors de brèves conversations. Ces observations suggèrent que les gens pourraient bientôt devenir de plus en plus méfiants à l’égard des autres personnes avec lesquelles ils interagissent en ligne, car ils pourraient ne plus savoir s’il s’agit d’humains ou de robots.
Les chercheurs prévoient désormais de mettre à jour et de rouvrir le test public de Turing qu'ils ont conçu pour cette étude, afin de tester certaines hypothèses supplémentaires. Leurs travaux futurs pourraient recueillir d’autres informations intéressantes sur la mesure dans laquelle les gens peuvent faire la distinction entre les humains et les LLM.
« Nous souhaitons proposer une version du jeu à trois personnes, dans laquelle l'interrogateur parle simultanément à un humain et à un système d'IA et doit déterminer qui est qui », a ajouté Jones.
« Nous souhaitons également tester d'autres types de configurations d'IA, par exemple en donnant aux agents un accès aux actualités et à la météo en direct, ou un « bloc-notes » où ils peuvent prendre des notes avant de répondre. Enfin, nous souhaitons tester si l'IA est convaincante. Les capacités s'étendent à d'autres domaines, comme convaincre les gens de croire à des mensonges, de voter pour des politiques spécifiques ou de donner de l'argent à une cause.