
L'efficacité des grands modèles linguistiques dans le micro-ciblage politique évaluée dans une nouvelle étude
Les progrès récents dans les grands modèles linguistiques (LLM) ont soulevé la perspective d’un microciblage politique évolutif, automatisé et précis à une échelle jamais vue auparavant. Par exemple, lorsqu'ils sont intégrés aux bases de données existantes de données personnelles, les LLM pourraient adapter les messages pour faire appel aux vulnérabilités et aux valeurs d'individus spécifiques, de sorte qu'une femme libérale de 28 ans, non religieuse et titulaire d'un diplôme universitaire, reçoive un message très différent. qu'un homme religieux et conservateur de 61 ans qui vient seulement d'obtenir son diplôme d'études secondaires.
Dans leur nouvel article, « Évaluer l'influence persuasive du micro-ciblage politique avec de grands modèles linguistiques », publié dans PNASle doctorant Kobi Hackenburg de l'OII et le professeur Helen Margetts abordent cette possibilité, en étudiant dans quelle mesure l'accès à ces données individuelles augmente l'influence persuasive du modèle GPT-4 d'OpenAI.
En créant une application Web personnalisée capable d'intégrer des données démographiques et politiques en temps réel dans les invites GPT-4, les chercheurs de l'OII ont généré des milliers de messages uniques adaptés pour convaincre les utilisateurs individuels.
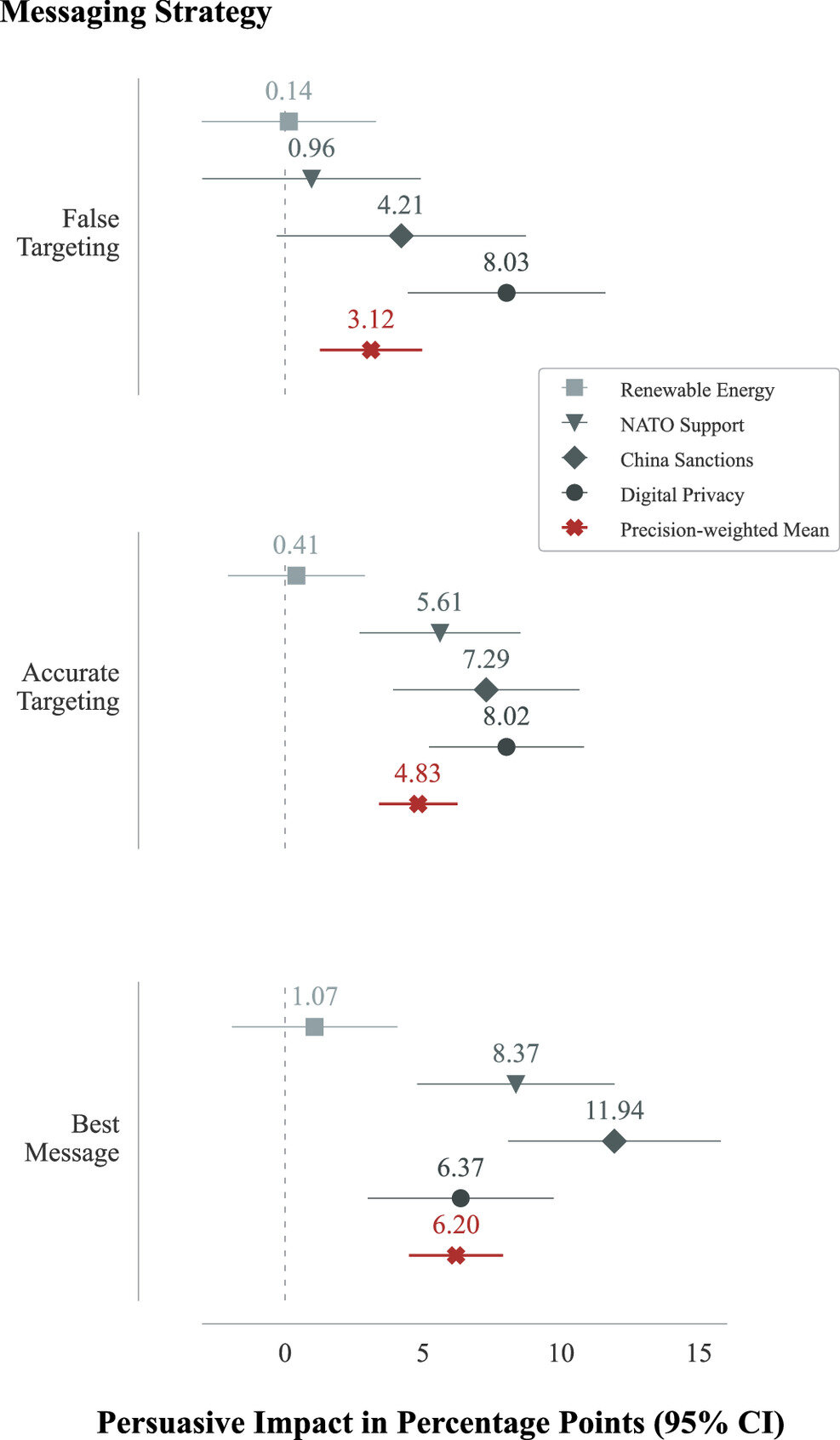
En déployant cette application dans le cadre d’une expérience de contrôle randomisée préenregistrée, ils ont constaté que les messages générés par GPT-4 étaient largement convaincants. Mais surtout, dans l’ensemble, l’impact persuasif des messages micro-ciblés n’était pas statistiquement différent de celui des messages non micro-ciblés.
Cela suggère – contrairement à une spéculation largement répandue – que l’influence des LLM actuels ne réside peut-être pas dans leur capacité à adapter les messages aux individus, mais plutôt dans le pouvoir de persuasion de leurs messages génériques et non ciblés.
Kobi Hackenburg a déclaré : « Il y a en réalité deux explications plausibles à ce résultat : soit le micro-ciblage basé sur du texte n'est pas en lui-même une stratégie de messagerie très efficace, soit GPT-4 est tout simplement incapable de micro-cibler efficacement lorsqu'il est déployé d'une manière similaire à notre conception expérimentale.
« Nous savons déjà, par exemple, que même les programmes de maîtrise en droit actuels ne peuvent pas toujours refléter de manière fiable la distribution des opinions de groupes démographiques précis ; une capacité qui semblerait nécessaire pour un microciblage précis. »
La professeure Helen Margetts a ajouté : « Cette découverte est importante car les dirigeants des grandes entreprises technologiques ont fait de grandes déclarations sur le pouvoir de persuasion du microciblage par des LLM comme GPT. Cette recherche a quelque peu remis en question ces affirmations. En revanche, elle met en évidence le pouvoir de persuasion du « meilleur message » de GPT sur des questions politiques spécifiques, sans ciblage. »