
Meta dévoile Llama 2 Long
Presque silencieusement, bien qu’il en ait eu l’occasion lors de l’événement Meta Connect, Métaplateformes a publié un article sur le site Web non évalué par les pairs arXiv.org dans lequel il présente Lama 2 Longun nouveau modèle d’IA basé sur le logiciel open source Llama 2 de Meta, qui a été soumis à « un pré-entraînement continu par Llama 2 avec des séquences d’entraînement plus longues et sur un ensemble de données où les textes longs sont suréchantillonnés », selon les chercheurs-auteurs du document « Effective Long -Context Scaling of Foundation Models » du 27 septembre 2023.
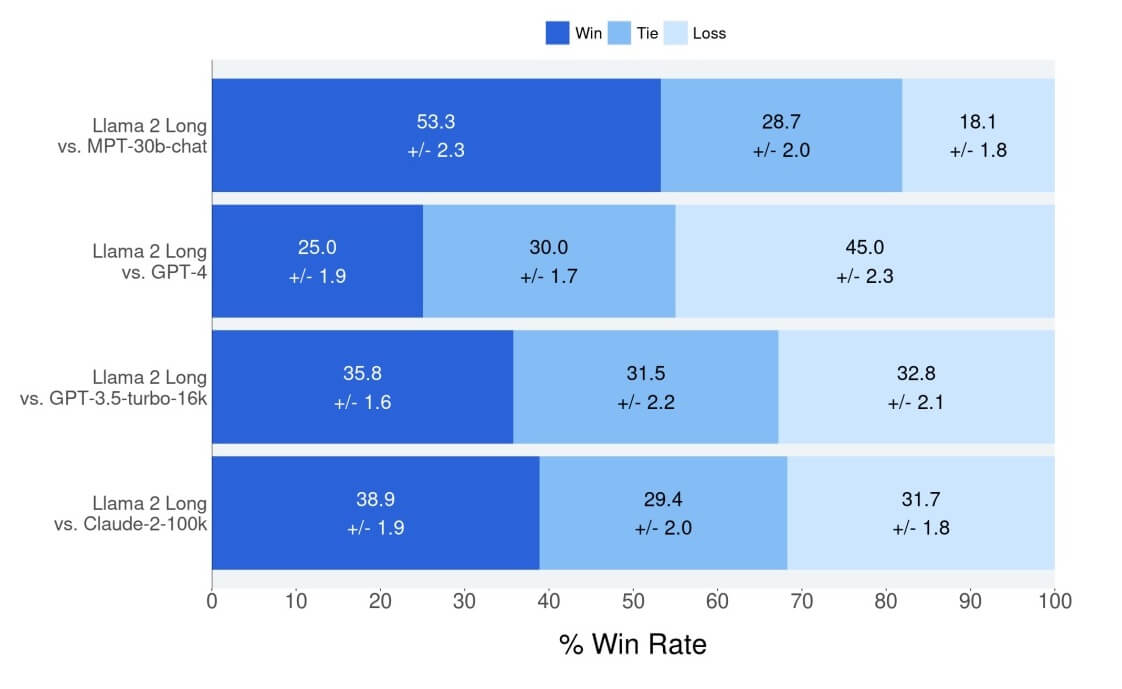
En conséquence, le nouveau modèle de intelligence artificielle étendue par Meta surpasse certains de ses principaux concurrents en générant des réponses aux requêtes longues (nombre de caractères plus élevé) des utilisateurs, notamment GPT-3.5 Turbo d’OpenAI avec une fenêtre contextuelle de 16 000 caractères et Claude 2 avec une fenêtre contextuelle de 100 000 caractères.
Comment est né LLama 2 Long
Les méta-chercheurs ont pris le Llama 2 original disponible dans ses différentes tailles de paramètres d’entraînement – les données et les valeurs d’informations que l’algorithme peut modifier lui-même pendant l’apprentissage, qui dans le cas de Llama 2 sont disponibles en 7 milliards, 13 milliards, 34 milliards. et 70 milliards de variantes – et ils comprenaient des sources de données textuelles plus longues que l’ensemble de données d’entraînement original de Llama 2. Pour être exact, 400 milliards de jetons supplémentaires.
Ensuite, les chercheurs ont conservé l’architecture du Llama 2 original inchangée, en apportant un seul « changement nécessaire au codage de position qui est fondamental pour que le modèle puisse durer plus longtemps ».
Le changement concerne le codage RoPE (Rotary Positional Embedding), une méthode de programmation de modèle de transformateur sous-jacente aux LLM tels que Llama 2 (et LLama 2 Long), qui mappe essentiellement les intégrations de jetons (les nombres utilisés pour représenter des mots, des concepts et des idées) sur un graphique 3D. montrant leurs positions par rapport aux autres jetons, même en cas de rotation. Cela permet au modèle de produire des réponses précises et utiles, avec moins d’informations (et donc moins de mémoire informatique) que d’autres approches.
Les méta-chercheurs ont « réduit l’angle de rotation » de son codage RoPE de Llama 2 à Llama 2 Long, ce qui a permis de garantir que les « jetons plus éloignés », ceux qui se produisent plus rarement ou ont moins de relations avec d’autres informations, étaient toujours inclus dans le modèle. base de connaissances.
En utilisant l’apprentissage par renforcement à partir du feedback humain (RLHF), une méthode courante de formation de modèles d’IA dans laquelle l’IA est récompensée pour ses réponses correctes sous la supervision d’un humain pour les surveiller, et des données synthétiques générées à partir du chat Llama 2 lui-même, les chercheurs ont pu pour améliorer ses performances sur les tâches courantes de LLM, notamment le codage, les mathématiques, la compréhension du langage, le raisonnement de bon sens et la réponse aux questions posées par un utilisateur humain.

Conclusions
Avec des résultats aussi impressionnants par rapport à Llama 2 normale qu’un Claude2 par Anthropic e GPT-3.5 Turbo d’OpenAI, il n’est pas étonnant que la communauté d’IA open source sur Reddit, Twitter et Hacker News ont exprimé leur admiration et leur enthousiasme pour Llama 2 après la publication du document : c’est une grande confirmation de l’approche « open source » de Meta envers l’IA générative et indique que l’open source peut rivaliser avec les modèles fermés et « payants pour jouer » proposés par des startups bien financées.