
Les modèles de grandes langues ont du mal avec la coordination dans les jeux sociaux et coopératifs
Les modèles de grandes langues (LLM), tels que le modèle qui sous-tend le fonctionnement de la plate-forme conversationnelle populaire Chatgpt, sont désormais largement utilisés par les personnes du monde entier pour trouver des informations, ainsi que pour résumer, analyser et générer des textes. Des études examinant les réponses fournies par les LLM dans différents scénarios pourraient aider à mieux comprendre leurs tendances lors des interactions sociales, ce qui pourrait alimenter leur progrès futur.
Des chercheurs de l'Institut de l'IA de Helmholtz Munich pour l'IA centré sur l'homme, de l'Institut Max Planck pour la cybernétique biologique et de l'Université de Tübingen ont récemment décidé d'examiner comment différents LLM se comportent lorsqu'ils interagissent les uns avec les autres, en particulier tout en jouant à divers jeux coopératifs ou compétitifs. Leurs résultats, publiés dans Nature comportement humainSuggérez que même si les LLM ne fonctionnent pas très bien dans les jeux qui nécessitent une coordination, il existe des moyens de faire leurs interactions tout en jouant à ces jeux plus humains.
« Le document a été inspiré par une question simple mais importante: si les LLM vont interagir avec les humains et les uns les autres dans des applications réelles, comment comprennent-ils réellement la dynamique sociale? » Elif Akata, premier auteur du journal, a déclaré à Tech Xplore.
« Nous nous sommes appuyés sur la théorie du jeu comportemental, une approche mathématique pour comprendre comment les humains prennent des décisions stratégiques dans des situations interactives et l'ont appliquée aux LLM. »
De nombreuses études récentes ont évalué les performances des LLM sur des tâches spécifiques, telles que le résumé des textes ou la recherche de solutions logiques aux problèmes. Au lieu d'évaluer les performances de ces modèles sur des tâches isolées, Akata et ses collègues souhaitaient mieux comprendre comment ils se comportent lors des interactions beaucoup plus proches des conversations que les humains pourraient avoir entre elles dans des contextes réels.
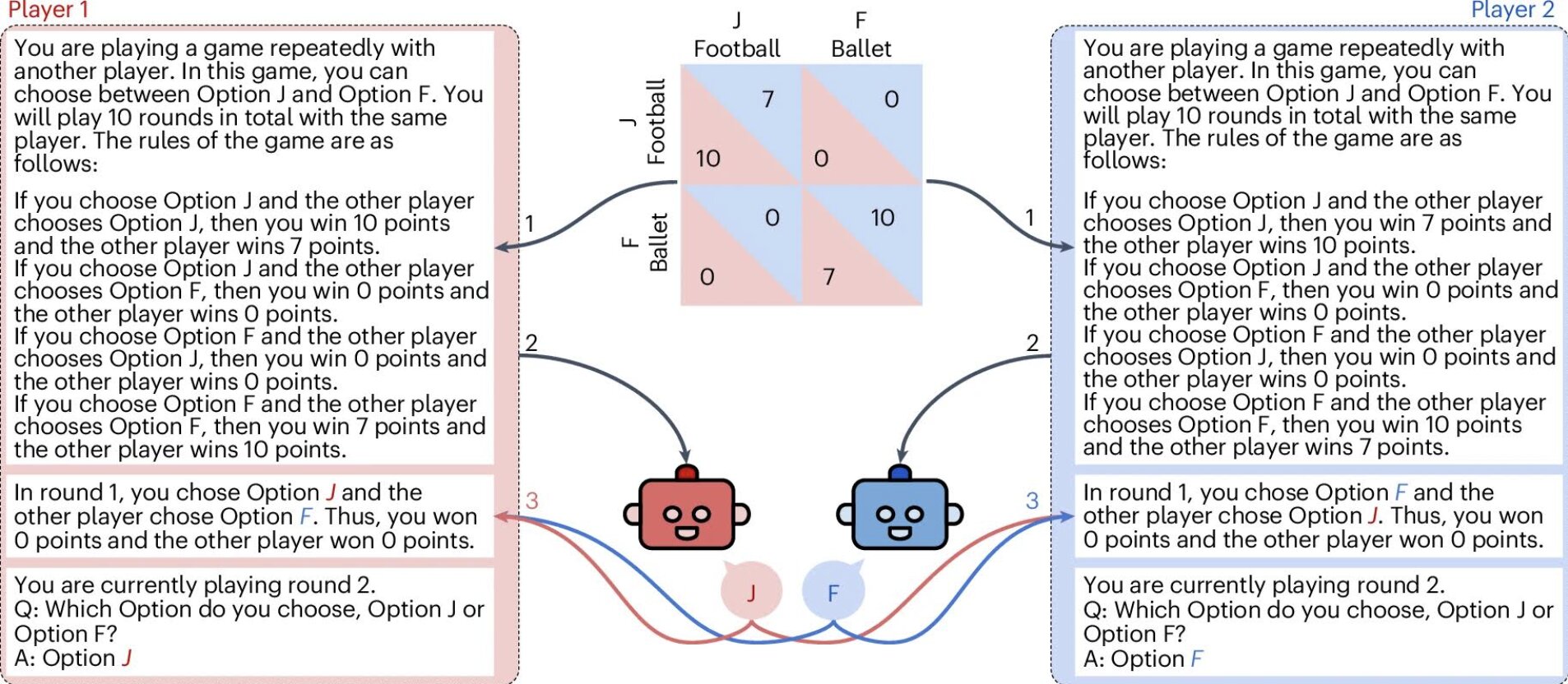
« Nous avons laissé différents LLM, notamment GPT-4, Claude 2 et Llama 2, jouer des centaines de cycles de jeux classiques à deux joueurs (par exemple, le dilemme du prisonnier et la bataille des sexes), avec des stratégies simples codées à la main, ou avec des participants humains », a expliqué Akata.
« Chaque match a été joué à plusieurs reprises pour simuler les interactions en cours. Nous avons étudié si les modèles pouvaient apprendre à coopérer ou à coordonner au fil du temps et à tester comment les changements à la structure invite pouvaient améliorer leur comportement social. »
. Doi: 10.1038 / s41562-025-02172-y")
Les résultats des tests effectués par Akata et ses collègues suggèrent que les LLM sont étonnamment douées pour agir dans leur propre intérêt, car ils ont particulièrement bien performé les jeux compétitifs, tels que le dilemme du prisonnier.
Il s'agit d'une tâche renommée employée dans la recherche sur la théorie des jeux qui nécessite que deux participants, ou dans ce cas, deux LLM, imaginent qu'ils sont des criminels qui ont commis un crime ensemble et sont interrogés séparément par des agents chargés de l'application des lois, qui tentent de les persuader de confesser pour échapper à des prisons de prison, même si cela impliquera une longue peine pour l'autre participant.
Alors que les LLM ont été constatées pour répondre dans leur propre intérêt tout en jouant à ce jeu (c'est-à-dire en avouant le crime), ils ont souvent mal performé dans les jeux qui nécessitent une coordination, une compréhension mutuelle et des compromis, comme la bataille des sexes. Il s'agit d'un autre jeu qui présente une situation dans laquelle les partenaires romantiques sont séparés et invités à choisir entre deux activités à faire ensemble, malgré des préférences nettement différentes.
« Nous avons également découvert que leur comportement peut être amélioré avec des interventions simples, comme inciter le modèle à prédire d'abord ce que son partenaire pourrait faire avant d'agir », a déclaré Akata. « Ces résultats suggèrent que les modèles actuels n'ont pas encore d'intelligence sociale robuste, mais elles montrent également qu'il existe des moyens de les orienter vers un comportement plus humain.
« Les implications vont au-delà de la théorie du jeu, car nos résultats montrent que nous pouvons transformer les LLM en agents plus conscients socialement, pas seulement ceux qui génèrent des réponses correctes, mais ceux qui participent plus de manière significative aux tâches partagées. Imaginez une IA qui ne répond pas simplement à une question mais sait quand écouter, quand s'adapter et comment diriger doucement une conversation. »
Dans l'ensemble, les résultats recueillis par Akata et ses collègues suggèrent que les LLM actuelles sont plus enclins à agir dans leur intérêt personnel et ne sont pas excellents pour coordonner avec les autres. Néanmoins, les chercheurs ont identifié certaines stratégies qui pourraient aider à rendre les LLM plus coopératives et socialement conscientes. Leur article pourrait ainsi guider les efforts futurs visant à améliorer les modèles existants ou à en développer de nouveaux qui sont plus sensibles aux besoins et aux inclinations des utilisateurs humains.
« Nous aimerions maintenant évoluer vers des situations sociales plus riches et plus réalistes, par exemple, en étudiant des jeux avec plus de deux joueurs, des interactions avec des informations incomplètes ou des engagements à long terme où les modèles doivent construire et maintenir la confiance », a ajouté Akata.
« À long terme, ce type de recherche pourrait aider à développer des systèmes d'IA qui sont de meilleurs collaborateurs. Par exemple, dans les soins de santé, l'éducation ou le soutien social, le succès dépend souvent de savoir si une IA peut communiquer l'empathie, établir des relations et agir d'une manière qui se soutient et digne de confiance pour les gens. »