

Futur LLM : des modèles plus efficaces et durables
Les laboratoires de recherche et les entreprises technologiques continuent de travailler pour un avenir dans lequel les LLM (grands modèles de langage) seront plus fonctionnels qu’aujourd’hui. L’objectif est de surmonter les limites qui réduisent actuellement son utilité et son applicabilité. Nous nous dirigeons vers une nouvelle génération de modèles linguistiques plus efficaces, moins coûteux et plus adaptés pour travailler sur des problèmes longs et complexes.
Nous avons besoin de systèmes capables de lire de très grandes bases de documents, de raisonner sur plusieurs étapes, d’utiliser des outils externes, de rester cohérents plus longtemps et ce avec des coûts d’inférence durables. C’est là que la recherche ouvre de nouvelles frontières, certaines déjà visibles dans les feuilles de route industrielles, d’autres encore expérimentales mais avec des implications très concrètes pour le marché des entreprises.
La prochaine génération de LLM sera de moins en moins évaluée sur la seule base de benchmarks et de plus en plus sur la relation entre qualité, latence, consommation de calcul et capacité à gérer des tâches complexes dans des environnements réels.
L’avenir des LLM : pourquoi le marché privilégie l’efficacité avant l’échelle
Dans la première phase d’adoption générative, l’avantage concurrentiel semblait correspondre à la taille du modèle. Aujourd’hui, l’accent change : un LLM qui coûte trop cher en production, qui ne peut pas gérer de longues tâches ou qui nécessite trop d’orchestration manuelle devient difficile à maintenir même lorsqu’il fonctionne bien lors des tests.
Pour cette raison, les recherches évoluent selon plusieurs axes : architectures plus légères, meilleure gestion du contexte, nouvelles façons de représenter le texte, utilisation dynamique du calcul dans les techniques d’inférence et de vérification des réponses.
Mélange d’experts et de modèles plus frugaux
L’une des trajectoires les plus concrètes est celle des modèles Mixture-of-Experts (MoE). Au lieu d’activer à chaque fois l’intégralité du réseau neuronal, ces approches ne font appel qu’à une partie des « experts » internes en fonction de la tâche.
Le cas DeepSeek-V3
Le cas le plus connu est DeepSeek-V3, qui revendique 671 milliards de paramètres au total mais 37 milliards d’actifs par jeton. L’objectif est d’augmenter la capacité sans exploser les coûts d’exploitation.

Ce qui change pour le marché
Si un modèle maintient des performances élevées en réduisant le calcul nécessaire pour chaque requête, les cas d’utilisation à grand volume tels que le support client, la recherche interne, l’automatisation des documents, les copilotes des développeurs et l’analyse de la base de connaissances deviennent plus durables.
L’avantage concurrentiel se déplace ainsi du modèle « le plus grand » vers le modèle « le plus adapté à la tâche effectuée ».
Architectures hybrides au-delà du pur transformateur
Une autre frontière concerne la tentative de surmonter certaines limites du transformateur traditionnel sans l’abandonner complètement.
La tendance Transformer-Mamba
Le papier Montanta propose une combinaison de blocs Transformer, de composants Mamba et d’un mélange d’experts. L’étude empirique de Nvidia sur les modèles Mamba suggère que les architectures hybrides peuvent maintenir de bonnes performances même dans des contextes longs et, dans certaines configurations, être jusqu’à 8 fois plus rapides en génération que des transformateurs comparables.
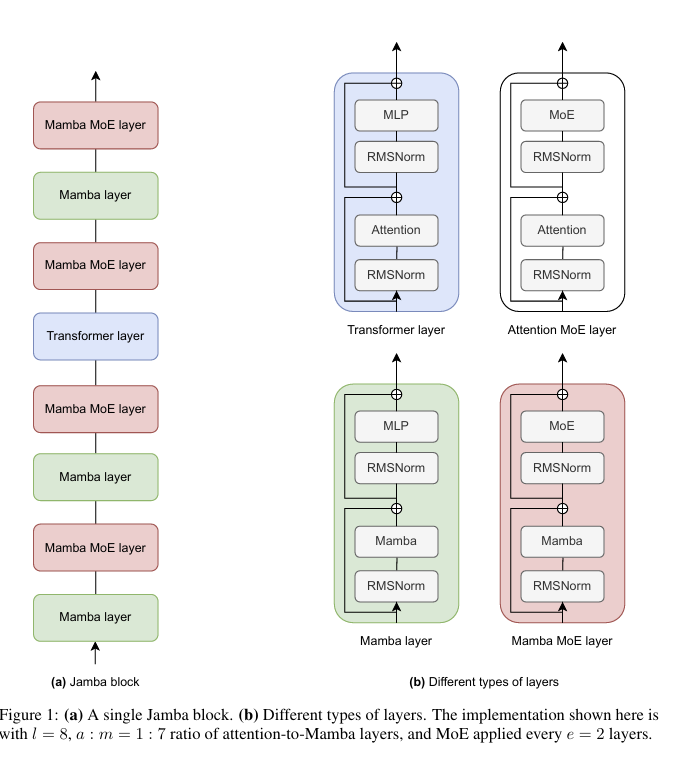
Les implications pour les entreprises et les fournisseurs
Si cette ligne se consolide, le marché ne s’organisera plus seulement autour du contraste entre modèles ouverts et fermés, mais aussi entre différentes familles architecturales. Cela peut avoir un impact direct sur les déploiements privés, en périphérie ou sur site, où la mémoire, le débit et la puissance comptent autant que la qualité du modèle.
Les modèles de langage de diffusion entrent dans le débat
Les modèles de diffusion, jusqu’à présent principalement associés aux images et aux vidéos, commencent également à être étudiés pour le langage.
Vers où pointe la recherche
Le travail Bloquer la diffusion de 2025 tente de combiner les avantages des modèles autorégressifs et diffusifs, dans le but d’obtenir une génération plus parallélisable, une longueur flexible et une meilleure efficacité d’inférence.
Pourquoi les entreprises devraient les suivre
Nous ne sommes pas encore confrontés à un standard industriel alternatif aux LLM classiques, mais la direction mérite qu’on s’y arrête. Si ces modèles arrivent à maturité, ils pourraient devenir intéressants dans des cas d’usage où la latence, le contrôle de sortie et la transformation structurée du contenu sont plus importants que la simple maîtrise linguistique.
Contexte long : le problème n’est pas seulement de lire davantage, mais de rester cohérent
Agrandir la fenêtre contextuelle ne suffit pas. Plus le nombre de tokens augmente, plus le modèle risque de perdre son fil, de perdre son attention ou de commettre des erreurs sur des relations réparties sur de très longs documents.
La proposition de modèles de langage récursifs
Dans ce domaine, l’article Recursive Language Model du MIT CSAIL propose une approche différente : au lieu de traiter l’ensemble du contexte comme un seul bloc, le modèle décompose la tâche, rappelle des copies de lui-même et fonctionne en plusieurs parties. Les auteurs affirment que ce schéma permet de gérer des entrées jusqu’à deux ordres de grandeur au-delà de la fenêtre contextuelle du modèle de base.
L’impact sur les cas d’utilisation en entreprise
Si cette approche se confirme, le bénéfice pour les entreprises sera direct dans des domaines tels que la due diligence, l’audit documentaire, l’analyse contractuelle, le support technique sur les référentiels étendus, la conformité et la recherche réglementaire.
Le point clé est que la valeur ne viendra pas seulement de fenêtres contextuelles plus grandes, mais de la capacité à décomposer correctement le problème.
Nouvelles unités de représentation : pas seulement des jetons
Une partie importante de la recherche remet en question l’idée selon laquelle le jeton reste l’unité optimale pour tout type de traitement linguistique.
Octets, correctifs et représentations alternatives
Le papier Transformateur latent d’octets propose de travailler sur des octets et des patchs dynamiques au lieu des tokens classiques, dans le but d’améliorer l’efficacité et la robustesse.
Le cas DeepSeek-OCR et la compression visuelle
Plus radical, et très intéressant pour les entreprises, est le cas DeepSeek-OCR, qui représente un contenu textuel long via une compression visuelle. Dans l’article, les auteurs montrent que le modèle surpasse GOT-OCR2.0 en utilisant 100 jetons de vision par page et fait mieux que MinerU2.0 avec moins de 800 jetons de vision.
Pourquoi cette frontière est importante pour l’IA documentaire
Pour ceux qui travaillent avec des PDF, des formulaires, des factures, des manuels, des tableaux techniques et des captures d’écran, cet axe de recherche peut avoir un impact significatif sur les coûts. Si le contenu des documents pouvait être compressé et traité plus efficacement avant la phase de raisonnement, l’IA documentaire pourrait devenir moins lourde et plus évolutive dans les processus à grand volume.
Calcul au moment du test : le modèle utilise davantage de calcul uniquement lorsque cela est nécessaire
Une autre frontière très pertinente est celle du calcul au moment du test, c’est-à-dire la possibilité d’allouer davantage de calculs dans la phase d’inférence uniquement à des tâches véritablement complexes.
Ce qui ressort des études
Le papier Augmenter le calcul au moment du test avec raisonnement latent explore des formes de raisonnement latent qui ne dépendent pas uniquement de la production de davantage de jetons. Une autre étude, Mise à l’échelle du calcul au moment du test pour les agents LLMmontre que l’augmentation du calcul dans l’inférence peut également améliorer les agents, en particulier lorsqu’ils combinent l’échantillonnage, l’examen, la vérification et la fusion des résultats.
L’effet sur les modèles de tarification et la gouvernance
Pour le marché, cela signifie que l’IA aura tendance à être tarifée et régie moins par le volume de texte que par l’intensité du travail cognitif requis. Pour les entreprises, cela signifie introduire de nouvelles politiques : quand est-il préférable de faire « réfléchir » davantage le modèle, quand l’arrêter en premier, sur quelles tâches autoriser des coûts plus élevés et où imposer des seuils de confinement.
Auto-vérification : la qualité dépend aussi de la capacité à se contrôler
Une ligne de recherche de plus en plus observée concerne la capacité du modèle à vérifier ses propres réponses.
Les études les plus récentes
Deux ouvrages récents, Inciter les LLM à auto-vérifier leurs réponses et apprendre à s’auto-vérifier rend les modèles de langage de meilleurs raisonneursmontrent que l’entraînement du modèle à l’auto-vérification peut améliorer non seulement le contrôle des erreurs, mais également la qualité du raisonnement.
Les implications dans des contextes réglementés
Cela n’élimine pas le problème des hallucinations, mais cela fait évoluer la recherche dans une direction plus utile pour les entreprises : non seulement générer des réponses, mais également évaluer leur exactitude. Pour les banques, les assurances, la santé, l’administration publique et les secteurs réglementés, cet aspect peut faire la différence entre un assistant intéressant et un système réellement intégrable dans les processus.
La prochaine phase du marché ne récompensera pas seulement ceux qui possèdent le modèle le plus puissant. Il récompensera ceux qui sauront combiner au mieux architecture, orchestration, mémoire, outils externes, vérification et coût opérationnel.
Les trois conséquences pour les entreprises
La première est que le choix du modèle ne peut plus être séparé du type de charge de travail : le chat, le codage, l’intelligence documentaire, les agents et la récupération d’entreprise suivront des trajectoires différentes.
La deuxième est que l’efficacité deviendra un facteur de compétitivité aussi important que la qualité. Réduire le coût par tâche utile signifie augmenter immédiatement le nombre de cas d’utilisation durables.
La troisième est que la fiabilité ne viendra pas d’une seule innovation, mais de l’intégration de plusieurs niveaux : gestion du contexte, mémoire externe, utilisation d’outils, vérification et allocation dynamique du calcul.
Une phase moins spectaculaire, mais plus importante pour l’entreprise
L’avenir proche ne semble pas être celui de modèles totalement nouveaux qui mettent les LLM à la retraite. Il semble plutôt que les LLM deviennent des marchandises : plus modestes en coûts, plus longs en portée, plus modulaires, plus multimodaux et, dans certains cas, plus capables de s’autocontrôler.
Mais c’est précisément au cours de cette maturation technique que se produira une véritable adoption par les entreprises.