

DeepSeek vient de sortir un modèle concurrent de l’Opus 4.6. Il coûte sept fois moins cher et fonctionne avec des puces chinoises
484 jours se sont écoulés depuis ce « moment DeepSeek », mais l’attente semble en valoir la peine, car nous avons le nouveau DeepSeek V4 avec nous. Nous sommes confrontés à un modèle de pondération ouvert absolument gigantesque qui promet une fois de plus de briser les fondations des modèles fondateurs propriétaires d’Anthropic, d’OpenAI ou de Google. C’est émouvant, messieurs.
Gigantesque et ouvert. DeepSeek v4 est un modèle Open Source et se décline en deux versions. Le premier est le Pro, avec 1,6 billion de paramètres (1,6T), dont 49 milliards actifs. Le second est Flash, avec 248 milliards de paramètres (248B, énorme pour un modèle « Flash ») dont 13 000 actifs.
Plus efficace que jamais. Les deux versions utilisent une architecture Mixture-of-Experts (MoE), ce qui signifie que seule une fraction des paramètres est activée dans chaque inférence. Cela permet de réduire considérablement le coût de calcul. Les deux versions prennent en charge une fenêtre contextuelle d’un million de jetons (pour inclure des romans et des romans à la fois en entrée) alors que dans la v3, elle était de 128 000 jetons. De plus, ce modèle est bien plus efficace que son prédécesseur en calcul par token : il ne nécessite que 27 % des opérations par token et 10 % du cache KV par rapport à DeepSeek v3.2.
Les benchmarks sont prometteurs. Les tests internes de DeepSeek révèlent que le v4 Pro-Max (le meilleur modèle avec la capacité de raisonnement la plus élevée) surpasse ou est à égalité avec Claude Opus 4.6 Max, GPT-5.4 xHigh, Gemini 3.1 Pro High, Kimi K2.6 et GLM 5.1. Les résultats ne sont cependant pas vérifiés de manière indépendante, ce qui signifie que nous devons les prendre avec prudence.
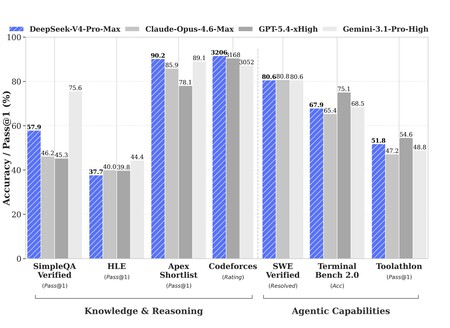
Les chiffres sont toujours frappants : dans LiveCodeBench, un test de programmation, DeepSeek v4-Pro-Max obtient un score de 93,5% contre 88,8 pour Opus 4.6 et 91,7% pour Gemini 3.1 Pro. Dans d’autres tests, il y a plus de variabilité, mais au moins sur le papier, DeepSeek v4 Pro semble aussi bon que Opus 4.7, qui était jusqu’à présent la référence absolue.

Beaucoup moins cher. Mais comme pour la version précédente, la différence de prix avec les modèles des entreprises américaines est étonnante. Comme le souligne l’analyste Simon Willinson, les prix officiels de DeepSeek v4 Pro sont de 1,74 $ par million de jetons d’entrée et de 3,48 $ par million de jetons de sortie, soit près de sept fois inférieurs à ceux de l’Opus 4.7 et près de 9 fois inférieurs à ceux du nouveau GPT-5.5. Avec DeepSeek v4 Flash, le coût est de 0,14/0,28 dollars par million de jetons d’entrée/sortie, alors que GPT-5.4 Mini coûte jusqu’à 16 fois plus. La conclusion est évidente : s’il fait réellement ce qu’il prétend faire, le prix est une véritable aubaine. C’est précisément le défi : que l’expérience réelle confirme ce que disent les critères.
Le mystère du matériel. DeepSeek n’a pas révélé quel matériel a été utilisé pour entraîner cette version de son modèle fondateur. Dans le passé, ils ont admis avoir utilisé des H800 de NVIDIA. Ce que l’on sait, c’est que le modèle a été développé pour fonctionner à la fois sur les puces NVIDIA et Huawei Ascend. Ce dernier a confirmé sur Baidu que ses clusters Ascend Supernode basés sur l’Ascend 950 supporteraient pleinement les versions DeepSeek v4.
Le soutien de Huawei est une « horrible » nouvelle pour les États-Unis. Dans The Information, ils ont déjà commenté que l’une des raisons du « retard » dans l’apparition de ce modèle était de l’adapter pour qu’il fonctionne sans problème avec les puces Huawei. Selon Jensen Huang, ce support est une « horrible » nouvelle pour les Etats-Unis, car cela signifie que la dépendance à l’égard des puces NVIDIA n’existe plus ou du moins est réduite au minimum.
Mais. Ce lancement intervient à un moment difficile pour l’entreprise. Guo Daya, l’un des responsables des modèles v1 et v3, a signé pour ByteDance pour travailler sur les agents IA. Luo Fuli, qui a dirigé le développement de la v2, a rejoint Xiaomi l’année dernière. Ce lancement coïncide également avec la première recherche de financement externe par DeepSeek. Ils devraient lever environ 300 millions de dollars et obtenir une valorisation d’environ 20 milliards de dollars selon le Wall Street Journal.
De l’effet de surprise à l’effet de continuité. Le lancement de DeepSeek R1 en janvier 2025 a été surprenant car il a démontré que la Chine pouvait former des modèles compétitifs pour une fraction du coût des modèles occidentaux. Avec DeepSeek v4, cet effet de surprise disparaît pour laisser place à l’effet de continuité. Ce modèle semble conserver précisément ce qui a fait la renommée du modèle précédent : une puissance extraordinaire à un coût très faible.
Mauvaise nouvelle pour Anthropic. Des prix aussi bas sont une terrible nouvelle pour Anthropic, qui a été contraint ces dernières semaines de procéder à une sorte de « réduction » de ses nouveaux modèles, qui ne sont pas plus chers mais consomment beaucoup plus de jetons. Nous devrons voir si DeepSeek v4 Pro est aussi bon que la société le promet, mais si c’est le cas, nous aurons un autre « moment DeepSeek » devant nous. Peut-être pas aussi remarquable que celui de l’année dernière, mais tout aussi pertinent.
À Simseo | DeepSeek leur a promis le bonheur en tant que grande IA chinoise. Je ne comptais pas sur un petit détail : Kimi