

Évaluation des agents IA dans l'entreprise : métriques, architecture
L’adoption d’agents d’IA autonomes va au-delà de la logique des chatbots uniquement conversationnels. Un agent combine raisonnement, planification et utilisation d’outils pour accomplir des tâches de bout en bout. Dans l'environnement d'entreprise, cela permet l'automatisation de processus complexes, la réduction de la charge opérationnelle et une aide directe à la décision.
Cependant, l’autonomie elle-même introduit un problème crucial qui est souvent sous-estimé : la fiabilité. Un agent ne peut pas être évalué uniquement sur le résultat final, mais aussi sur le chemin qu'il suit, sur les coûts générés, sur les risques introduits et sur la stabilité de son comportement dans le temps. En l’absence d’un cadre d’évaluation structuré, la décision de passer en production reste basée sur des démonstrations, des tests ponctuels et des évaluations non répétables.
Dans des contextes réglementés ou à fort impact réputationnel cela génère un déficit de confiance qui ralentit l’adoption et l’empêche mise à l'échelle. L'évaluation n'est donc pas une activité accessoire, mais une fonction permettant de décider si un agent est prêt pour la production, avec quelles limites d'autonomie, quels seuils de contrôle et quel rapport entre coût et valeur générée.

Agents IA, les limites des approches actuelles
Dans la plupart des organisations, l’évaluation des agents d’IA découle de pratiques partielles, utiles mais insuffisantes si elles sont adoptées isolément.
Les benchmarks et les ensembles de données génériques permettent des comparaisons de modèles, mais ne représentent pas des cas d'utilisation en entreprise, dans lesquels l'agent est personnalisé, intégré à des données propriétaires, récupérationles politiques internes et les outils d'application. Le risque est d’obtenir des scores élevés sur des benchmarks standards et des performances qui ne sont pas alignées sur les processus réels.
L'approche LLM-en tant que juge accélère l'évaluation automatique, mais introduit deux limites structurelles : le modèle d'évaluateur ne connaît pas le contexte métier et peut juger de manière imprécise les aspects critiques ; cela augmente également le coût de calcul, surtout s'il est appliqué à de grands volumes d'interactions.
La validation manuelle par des experts reste la référence qualitative, mais elle n'est pas évolutive. Cela prend du temps, introduit de la variabilité et ne peut pas maintenir un cycle de contrôle continu.
Cela nécessite un cadre combinant automatisation et examen humain ciblé, avec des mesures observables, des pratiques reproductibles et une intégration dans le cycle de vie de l'agent.
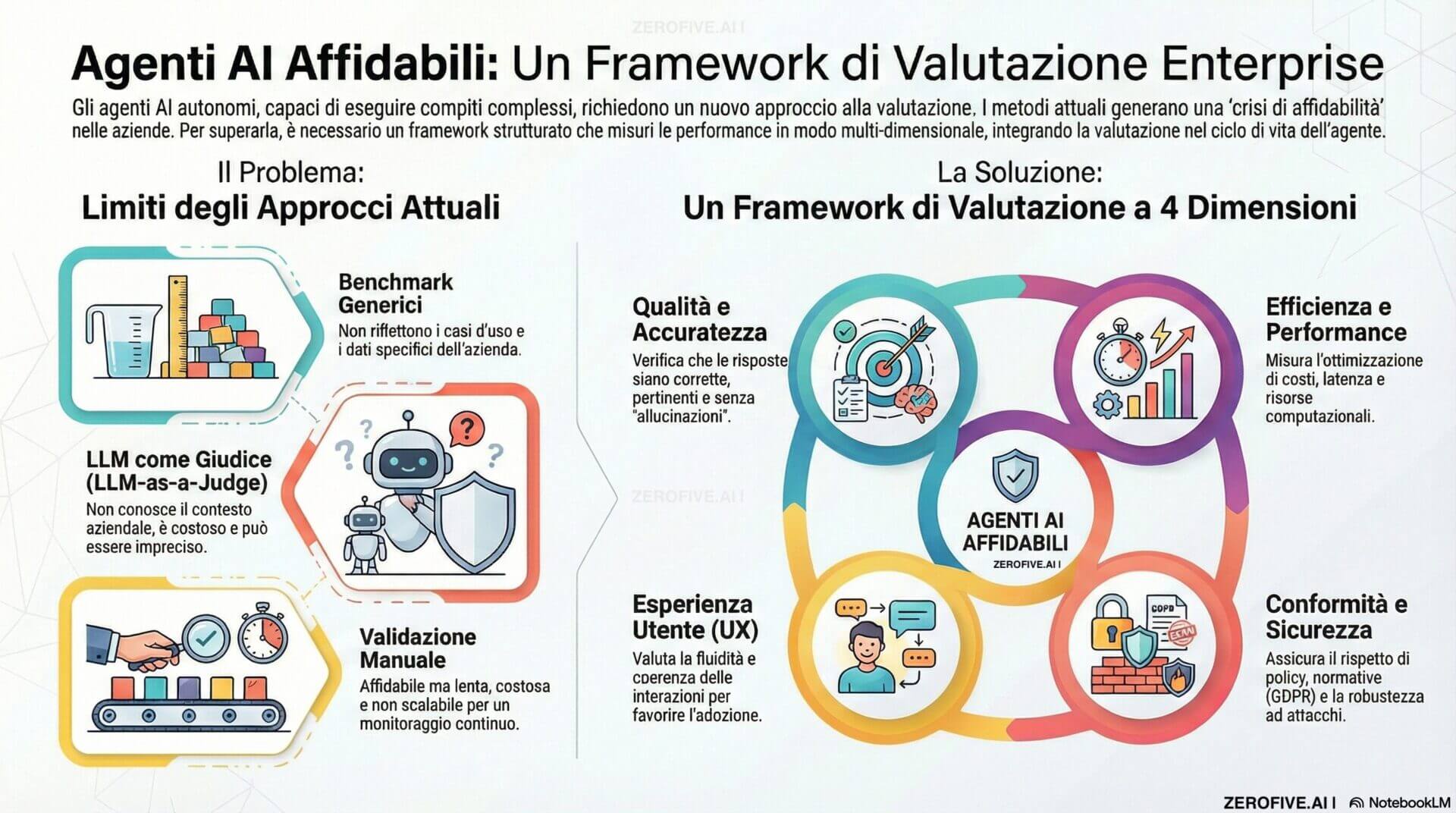
Tableau de bord complet : que mesurer
Un cadre d’évaluation d’entreprise doit couvrir au moins quatre dimensions complémentaires. Un agent peut en effet fonctionner correctement sur une dimension et échouer sur les autres.
Le premier concerne la qualité et la précision. L'exactitude des réponses, la pertinence par rapport à la demande et l'absence d'erreurs factuelles sont mesurées. Un élément clé est le enracinementc'est-à-dire le degré auquel le résultat est ancré dans des sources vérifiables telles que des bases de connaissances, la documentation de l'entreprise ou les données du système.
La deuxième dimension est l’efficacité et la performance. Il ne s'agit pas seulement de latence et d'évolutivité, mais également de l'efficacité du comportement agent : nombre d'étapes nécessaires pour accomplir une tâche, appels d'outils, redondances et coûts d'exécution. Dans le contexte d’une entreprise, la rentabilité est une mesure de produit, et pas seulement une mesure d’infrastructure.
La troisième dimension est l’expérience utilisateur et l’adoption. Cela inclut la cohérence des réponses, la clarté de la communication, la capacité à maintenir le contexte et la stabilité de l’interaction. Un agent techniquement correct mais mal compris ou incohérent augmente les escalades humaines et réduit la confiance.
La quatrième dimension concerne la conformité et la sécurité. Cela inclut le respect des politiques de l’entreprise, les contraintes réglementaires, la protection des données sensibles et la robustesse contre les entrées malveillantes ou les tentatives de forcer un comportement non autorisé.
Métriques opérationnelles : de l'agent aux outils
Pour rendre le cadre applicable, les dimensions doivent être traduites en mesures mesurables et en tests reproductibles. Une distinction opérationnelle utile consiste à distinguer les mesures de comportement des agents et les mesures d’utilisation des outils.
Les mesures de performances des agents incluent :
- la pertinence du raisonnement, c'est-à-dire la capacité à garder chaque étape liée à l'objectif,
- la cohérence logique du flux de décision
- la pertinence de la réponse finale.
Nous évaluons également le enracinement des déclarations, la maîtrise linguistique, l'exhaustivité de la réponse et l'efficacité dans la décomposition de tâches complexes.
D'autres mesures fondamentales sont la robustesse, comprise comme la résilience à des entrées inattendues ou à des pannes d'outils, et la cohérence des actions, c'est-à-dire la capacité à produire des comportements stables sur des entrées similaires, en évitant une volatilité injustifiée.
Les métriques d'utilisation des outils mesurent plutôt la précision de la sélection du bon outil, l'efficacité de l'utilisation en évitant les appels redondants, la précision des paramètres transmis dans les invocations et le taux de réussite des appels.
Ces métriques vous permettent de définir des seuils minimaux et des critères de qualité de pré-production, ainsi que des KPI à surveiller pendant l'exploitation.
Architecture technique pour mettre en œuvre l’évaluation
L’évaluation doit être effectuée, pas seulement définie. En entreprise, deux méthodes complémentaires sont nécessaires.
L'évaluation hors ligne analyse rétrospectivement les journaux et les traces des agents : invites, réponses, appels d'outils et erreurs. Il est non intrusif et n’introduit pas de latence d’exécution. Il convient aux audits, aux tests de régression et aux analyses périodiques, mais ne fournit pas de retour d'information immédiat.
L'évaluation en temps réel introduit des contrôles pendant l'exécution. L'agent ou l'orchestrateur invoque un service d'évaluation pour vérifier les aspects critiques et appliquer des garde-fous ou des solutions de repli si un indicateur tombe en dessous du seuil. Il est efficace pour les cas à risque élevé, mais doit être utilisé avec parcimonie pour limiter la complexité et la latence.
Une architecture de référence fournit un service centralisé d'évaluation des agents avec quatre phases opérationnelles :
- déclencheur d'évaluation,
- récupération des interactions depuis les systèmes de journalisation,
- moteur de calcul de métriques
- publication des résultats via des rapports et des tableaux de bord.
Le i est fondamentalinstrumentation: sans journaux structurés sur les étapes, les appels d'outils et le contexte, de nombreuses métriques ne sont pas calculables.
Implications organisationnelles et opérationnelles
L’évaluation des agents d’IA est également une question de processus et de gouvernance.
Il doit être intégré dans le cycle de vie du produit, en définissant des métriques dès la phase de conception, en introduisant porte de qualité dans les pipelines de versions et en fournissant des examens périodiques après le déploiement.
Nécessite des rôles dédiés ou clairement attribués : les chiffres de l'IA assurance qualitéimplication d'experts du domaine pour les critères d'exactitude et rôles d'opérations d'IA pour le suivi de la production et la gestion des alertes.
La gestion des risques en production impose des garde-fous concrets : réduction de l'autonomie ou arrêt de l'agent en cas d'écarts, mécanismes de rollback et contrôles spécifiques répartis dans les différents composants de l'architecture.
Enfin, les mesures et les seuils doivent évoluer au fil du temps. La stratégie de évaluation il doit être révisé périodiquement, en capitalisant sur l'expérience accumulée pour maintenir des normes élevées même avec les nouveaux agents.
Étude de cas : Agent de commerce électronique axé sur la personne
Prenons l'exemple d'un agent IA qui assiste les clients dans un contexte de commerce électronique, en adaptant l'interaction à des profils tels que « soucieux du prix », « premium » ou « explorateur ». La comparaison s'effectue entre une version de base non personnalisée et une version adaptée à la personne.
Les mesures générales incluent l'achèvement des tâches d'achat et la réussite des tâches clés telles que la recherche de produits, la comparaison des alternatives et le traitement des objections.
Du point de vue de l'efficacité, le nombre d'étapes pour parvenir à l'achat, les appels au catalogue et aux systèmes de recommandation ainsi que la durée globale de la session sont analysés.
Les mesures de personnalisation mesurent la pertinence des recommandations par rapport au profil, la cohérence du comportement au fil des sessions et leur comparaison directe avec la référence en termes de conversion et de satisfaction.
Le framework vous permet de lire clairement les compromis entre vitesse et personnalisation, coûts de calcul et valeur générée, en identifiant les domaines d'optimisation sans renoncer aux principaux avantages.
Liste de contrôle de décision
- Définir les objectifs et les limites de l'autonomie de l'agent.
- Identifiez les scénarios critiques et créez des tests reproductibles.
- Sélectionnez un ensemble limité de mesures de base avec des seuils clairs.
- Mettre en œuvre enregistrement suivi des appels structuré et outillé.
- Introduire porte de qualité et un examen humain ciblé.
- Définir une alerte, retomber et procédures restauration.
- Planifiez des examens et des mises à jour périodiques des métriques.
L’évaluation des agents d’IA devient ainsi une pratique récurrente de mesure, de décision et de contrôle. C’est la condition préalable pour faire évoluer les agents d’IA dans l’entreprise sans dépendre de démonstrations ou de perceptions, transformant ainsi l’adoption en un processus gouverné.