

La famille Qwen s’agrandit : les performances des nouveaux modèles Alibaba
En quelques jours seulement, le laboratoire Tongyi d’Alibaba a complété la famille Qwen 3.6 avec trois versions couvrant de nombreux scénarios d’adoption concernés.
Le premier est arrivé le 16 avril avec Qwen3.6-35B-A3B, un mélange d’experts à poids ouvert avec 35 milliards de paramètres au total et 3 actifs par jeton.
Qwen3.6-Max-Preview a suivi le 20 avril, le produit phare en version préliminaire et, pour la première fois dans l’histoire de Qwen, distribué exclusivement en service fermé via API.
Le 22 avril, c’était au tour de Qwen3.6-27B, un modèle dense multimodal sorti sous licence Apache 2.0.
La séquence en dit long sur la stratégie d’Alibaba : l’idée est de développer une gamme de produits plus flexible que la concurrence américaine, avec un produit phare propriétaire au sommet et deux variantes open source sur lesquelles développer la communauté des développeurs.

Qwen3.6-Max-Preview : le produit phare du poids fermé
Alibaba décrit Qwen3.6-Max-Preview comme un accès anticipé de la prochaine génération phare. Par rapport à Qwen3.6-Plus, lancé fin mars, les améliorations mesurables se concentrent sur six benchmarks de programmation, pour lesquels Max-Preview revendique la première place au moment de sa sortie : SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench et SciCode.
Les sauts les plus significatifs sont de +10,8 points sur SciCode, +9,9 sur SkillsBench, +5,0 sur NL2Repo et +3,8 sur Terminal-Bench 2.0. Le modèle se démarque également avec un indice d’intelligence analytique artificielle de 52, bien au-dessus de la médiane de 33 dans la même gamme de prix.
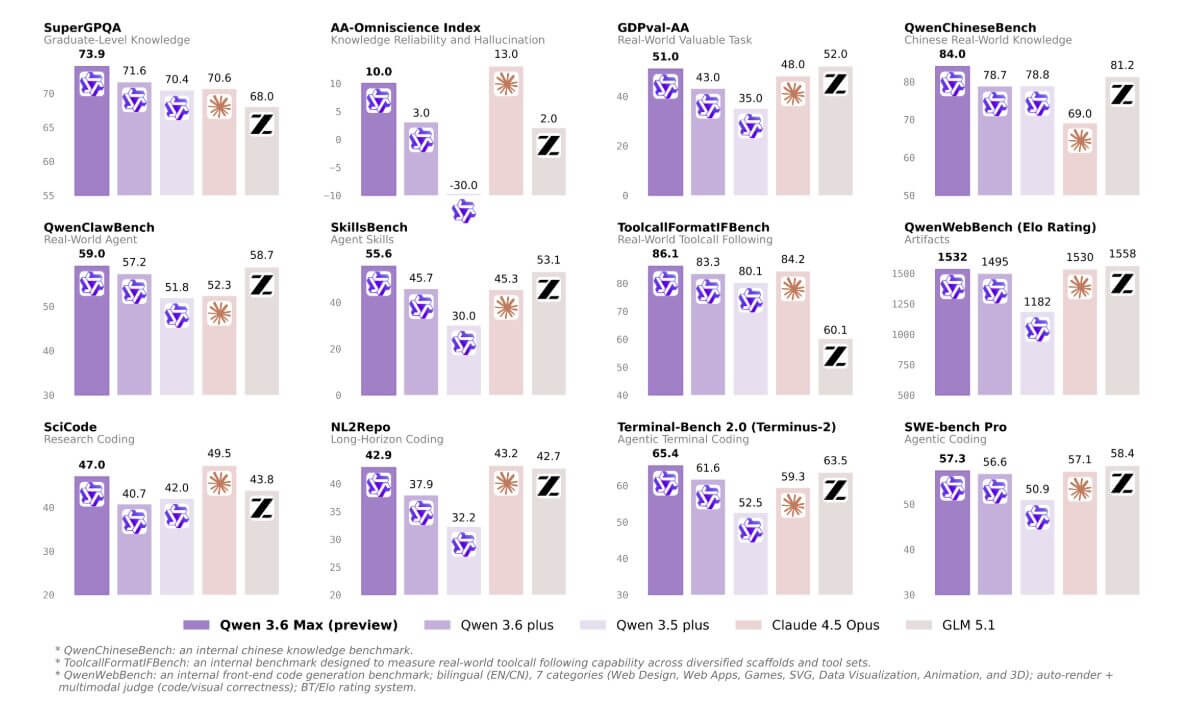
Prix très compétitif
Trois détails clés ont un impact sur la manière dont vous pouvez intégrer Max-Preview dans un flux d’automatisation.
Tout d’abord, les poids sont fermés : pas de releases sur Hugging Face. Il s’agit d’une démarche qui suit les stratégies d’OpenAI et d’Anthropic, orientées vers une approche API-first de monétisation et de protection de l’avantage concurrentiel obtenu lors de la phase de formation. De plus, le modèle est uniquement en texte, sans prise en charge de la saisie d’images ou de vidéos.
Enfin, la vitesse de génération est plutôt réduite : des tests indépendants indiquent une consommation d’environ 34 tokens par seconde et un TTFT (Time To First Token) de 3,3 secondes, des valeurs inférieures à la médiane pour des modèles de raisonnement de même gamme.
Le prix est très compétitif et les points de terminaison sont compatibles avec les formats OpenAI et Anthropic ; amener des systèmes déjà développés chez Alibaba devient ainsi une opération très rapide et quasiment gratuite.

Qwen3.6-27B : l’open source dense à la poursuite des frontières
Qwen3.6-27B est la version qui fait le plus de bruit dans la communauté open source. Il s’agit d’un modèle multimodal dense de 27 milliards de paramètres, 64 couches pour le texte, les images et la vidéo, distribué sous la licence Apache 2.0 sur Hugging Face et ModelScope. Le fichier pèse environ 56 Go. Le contexte natif est de 262 144 jetons, extensible jusqu’à plus d’un million.
L’architecture continue sur la voie hybride inaugurée par Qwen 3.6-Plus. Les 64 couches sont organisées en blocs alternés DeltaNet fermé (attention linéaire) e Attention fermée avec Attention aux requêtes groupées. Là attention linéaire réduit la croissance du coût de calcul : pour ceux qui gèrent un budget GPU, travailler sur des documents longs devient considérablement moins coûteux en termes de calcul, d’énergie et de temps de réponse.
Les repères
Les benchmarks rapportés par Alibaba méritent les titres qui leur sont dédiés.
Sur le banc SWE Verified, Qwen3.6-27B obtient un score de 77,2 contre 80,9 pour Claude 4.5 Opus, restant dans une marge de 3,7 points bien qu’il soit dix fois plus petit en paramètres totaux.
Sur Terminal-Bench 2.0, le modèle obtient le même score que le Claude 4.5 Opus, 59,3.
Sur SkillsBench, il surpasse la concurrence américaine, 48,2 contre 45,3, et sur GPQA Diamond, il obtient un score de 87,8 contre 87,0.
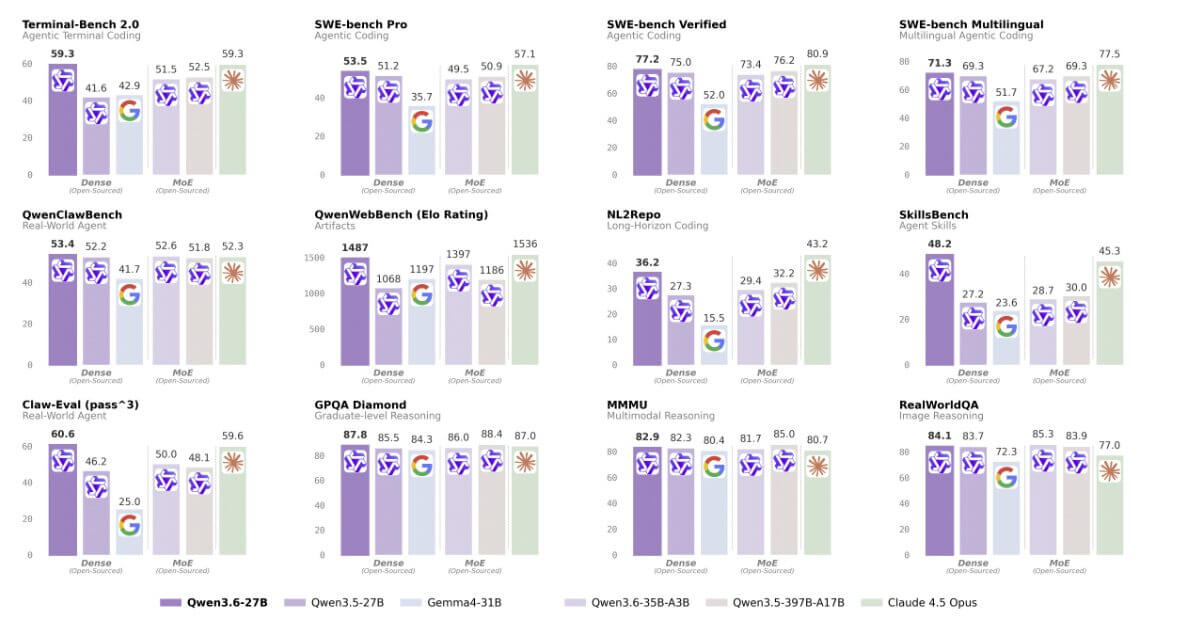
Pour un modèle dense de 27 milliards de paramètres, déployables localement, ce sont des chiffres extrêmement intéressants. Le 27B hérite également de sa fonction de la famille préserver la penséel’option qui maintient le raisonnement interne généré lors des tours précédents pour réduire les boucles et stabiliser le comportement des agents.

Qwen3.6-35B-A3B : le MoE pour des déploiements efficaces
Qwen3.6-35B-A3B est un mélange d’experts (MoE) clairsemé avec 35 milliards de paramètres au total et seulement 3 milliards actifs pour chaque jeton. Le ratio de spread de 12 pour 1 est parmi les plus agressifs jamais rendus publics. Le résultat pratique est une capacité d’inférence à des coûts comparables à un modèle 3B, tandis que les connaissances acquises restent celles d’un modèle 35B.
La vitesse de génération, mesurée sur l’API Alibaba, s’élève à environ 215 jetons par seconde, soit plus de six fois celle de Max-Preview.
Sur les critères de codage des agents, le 35B-A3B rivalise avec des repaires nettement plus grands.
Sur le banc SWE Vérifié, il obtient un score de 73,4.
Sur Terminal-Bench 2.0, il atteint 51,5, soit près de neuf points au-dessus de Gemma 4-31B, qui active tous ses 31 milliards de paramètres à chaque inférence.
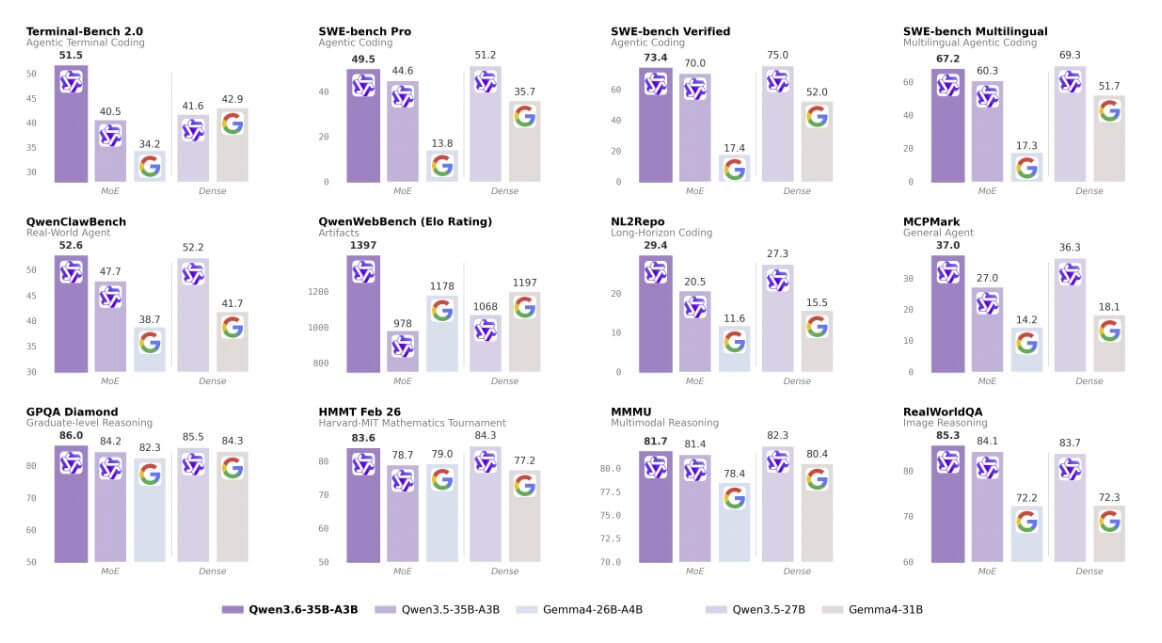
Le modèle a été publié sous la licence Apache 2.0 et convient au déploiement sur site sur des postes de travail haut de gamme. C’est probablement le choix le plus intéressant aujourd’hui pour ceux qui recherchent un assistant de développement local doté de bonnes capacités multimodales et de frais de licence nuls.
Applications des nouveaux modèles de la famille Qwen
Pour ceux qui gèrent une fonction informatique en Europe, la famille Qwen 3.6 ouvre de nouvelles options architecturales intéressantes. Trois profils de déploiement peuvent être mis en production en parallèle.
La première est l’API gérée pour Max-Preview, à utiliser pour les cas d’utilisation qui nécessitent une capacité de raisonnement maximale et qui peuvent tolérer le flux de données vers Alibaba Cloud.
Le modèle dense 27B peut être auto-hébergé sur une machine dotée d’un GPU haut de gamme, pour les charges de travail ayant des exigences de confidentialité ou de résidence des données.
Le petit modèle MoE est le meilleur choix pour les pipelines par lots à haut débit, où le taux de jetons par seconde compte autant que la qualité de la sortie individuelle.
Les questions qui s’appliquent à tout modèle chinois demeurent : la conformité au RGPD doit être vérifiée au cas par cas ; les politiques de traitement des données nécessitent une attention particulière, en particulier pour Max-Preview.
Les filtres appliqués à certaines catégories de contenu politiquement sensibles du point de vue du gouvernement chinois sont documentés et devraient être pris en compte pour certains cas d’utilisation.
La trajectoire du marché
Les trois versions, prises ensemble, tracent une trajectoire claire. Alibaba passe de la publication de modèles phares individuels à une approche par famille de produits, avec un poids fermé en haut et des poids ouverts de différentes tailles couvrant les cas d’utilisation sous-jacents. Le schéma ressemble à celui de Mistral. La spécificité de Qwen réside dans l’offre open source dans les coupes intermédiaires, un choix qui continue d’exercer une pression concurrentielle sur la grille tarifaire américaine.
La convergence technique est désormais évidente. Tous les modèles Frontier prennent en charge des contextes de jetons de 256 000 à 1 million, le raisonnement en chaîne de pensée, les appels de fonctions natifs et les capacités multimodales. Les différences s’orientent vers trois dimensions opérationnelles :
- fiabilité en production,
- l’intégration avec les écosystèmes de développement,
- relation entre coût et qualité sur des charges réelles.
Pour construire des pipelines solides, le choix le plus pratique reste d’utiliser une abstraction interne qui permet d’acheminer les charges de travail vers le modèle le mieux adapté à chaque cas d’utilisation, gardant ouverte la possibilité de remplacer les modèles et les fournisseurs sans réécrire le code de l’application. Des frameworks comme LiteLLM, OpenRouter et des bibliothèques natives de divers fournisseurs offrent ce niveau de découplage.
TITRE SEO :
MÉTADESCRIPTION :
CONTRIBUTIONS IA : 0-30 %