

TPU 8 Google : nouvelles puces IA pour le cloud et les supercalculateurs
Google accélère la construction de l’infrastructure pour l’intelligence artificielle et présente la huitième génération de son Tensor Processing Unit (TPU). L’annonce intervient pendant l’événement Google Cloud suivant ‘26, avec deux nouvelles architectures distinctes :
- TPU 8t, conçu pour la formation de modèles,
- TPU 8i, conçu pour l’inférence.
C’est le résultat de plus de dix années de développement. L’objectif est de soutenir une nouvelle phase de l’intelligence artificielle, caractérisée par des agents autonomes capables d’effectuer des tâches complexes, de raisonner et d’apprendre en continu.
Une réponse à la croissance de l’intelligence artificielle
Ces dernières années, les modèles d’IA ont nécessité de plus en plus de puissance de calcul. L’évolution vers des systèmes agentiques – capables de planifier, d’exécuter des actions et de s’améliorer au fil du temps – a introduit de nouvelles exigences infrastructurelles.
Selon Google, les modèles de nouvelle génération ne se contentent plus de répondre aux requêtes, mais gèrent des workflows complexes et itératifs. Cela implique une augmentation de la demande tant en phase de formation qu’en phase d’utilisation opérationnelle.
Des TPU de huitième génération ont été créés pour répondre à ce double besoin, en séparant les fonctions entre deux puces spécialisées.
Deux architectures pour des fonctions différentes
Google a choisi de développer deux processeurs distincts au lieu d’une solution unique.
Le TPU 8t est optimisé pour la formation de modèles à grande échelle, où une puissance de calcul maximale est nécessaire.
Le TPU 8i, quant à lui, est conçu pour l’inférence, c’est-à-dire pour l’utilisation de modèles en temps réel, avec une attention particulière à la latence et à la gestion des requêtes.
Cette répartition reflète une évolution de la demande du marché. Ces dernières années, à mesure que les entreprises sont passées de l’expérimentation à la production, elles ont davantage recours à l’inférence à grande échelle.
TPU 8t : accélère le développement de modèles
Le TPU 8t vise à réduire le temps de développement des modèles les plus avancés, passant de plusieurs mois à quelques semaines.
Le système offre presque trois fois plus de performances informatiques que la génération précédente. Tout va bien « superpode » peut avoir jusqu’à 9 600 puces et deux pétaoctets de mémoire partagée à haut débit.
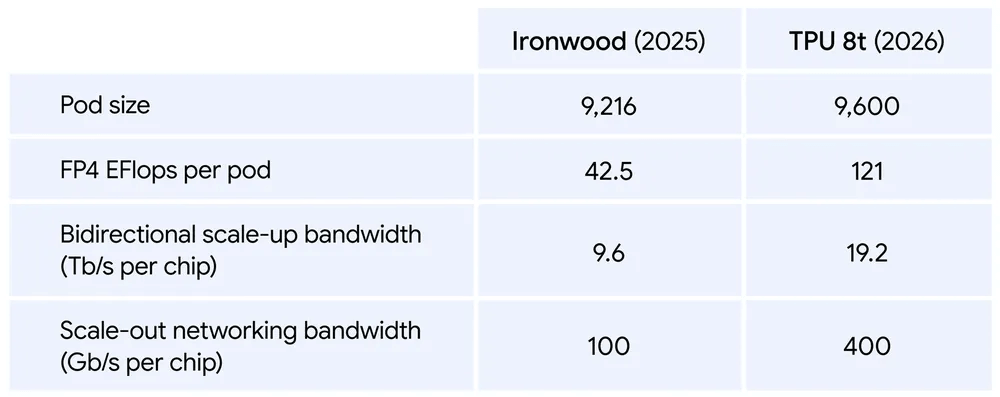
La capacité globale atteint 121 ExaFlops, un niveau qui permet de former des modèles extrêmement complexes à l’aide d’une seule infrastructure intégrée.
Un élément central est l’optimisation de l’utilisation des ressources. L’accès au stockage a été accéléré jusqu’à dix fois, tandis que le système TPUDirect vous permet de transférer des données directement vers le processeur, réduisant ainsi les temps d’arrêt.
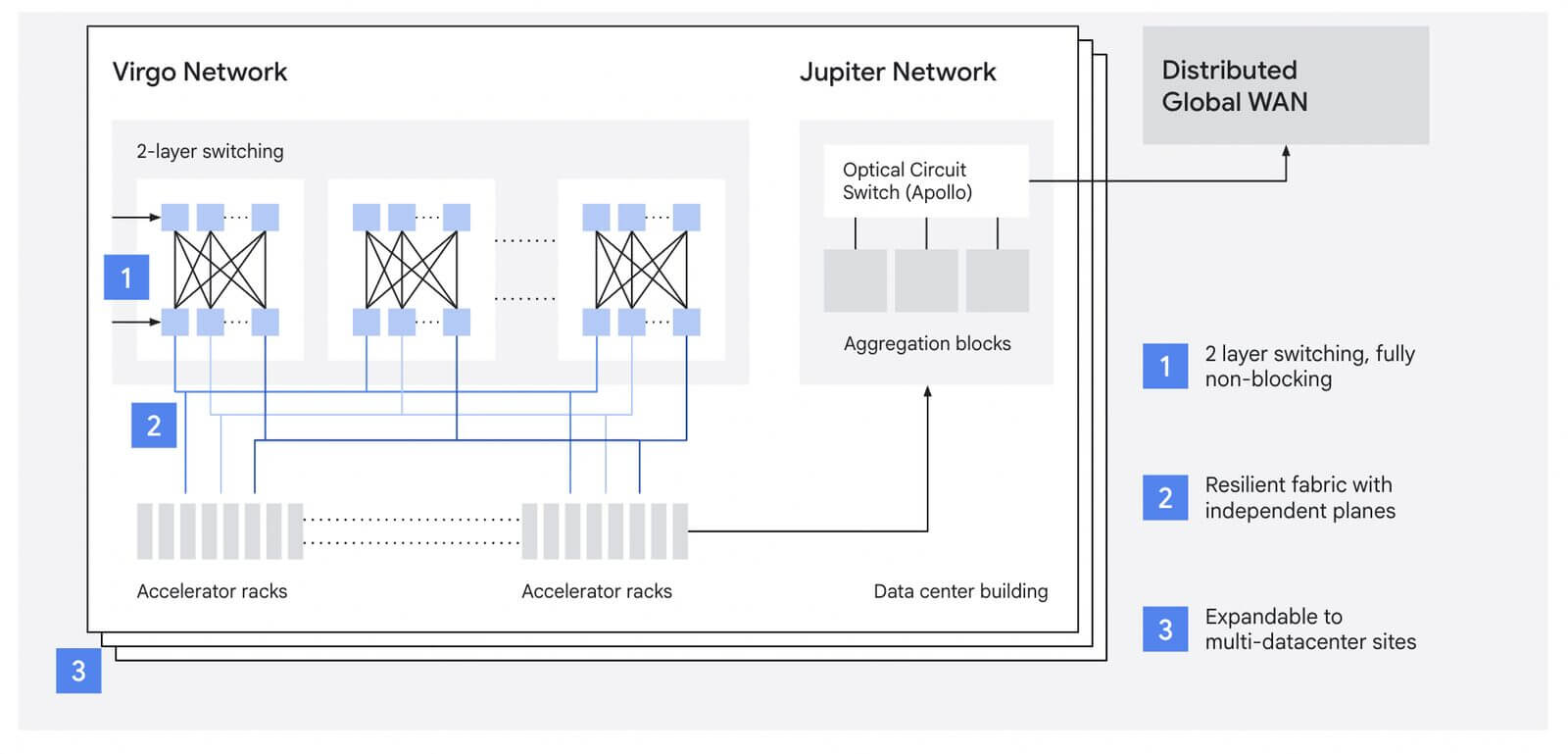
Google présente également un nouveau réseau, appelé Réseau Viergequi permet une évolutivité quasi linéaire jusqu’à un million de puces dans un seul cluster logique.
Fiabilité et continuité opérationnelle
En calcul intensif, même de petites interruptions peuvent avoir un impact sur les temps de formation.
C’est pourquoi le TPU 8t est conçu pour atteindre plus de 97 % de «bon put« , c’est-à-dire le temps effectivement consacré au calcul utile. Le système intègre des fonctions avancées de surveillance et de gestion automatique des défauts.
Celles-ci incluent la télémétrie en temps réel sur des dizaines de milliers de puces, la capacité de contourner automatiquement les connexions défectueuses et les systèmes de reconfiguration matérielle sans intervention humaine.
Chaque pourcentage d’amélioration, à grande échelle, peut se traduire par des jours de formation économisés.
TPU 8i : inférence et agents intelligents
Si le TPU 8t est conçu pour construire des modèles, le TPU 8i est conçu pour les utiliser.
L’objectif est de gérer des systèmes composés de nombreux agents d’IA fonctionnant en parallèle, collaborant entre eux pour résoudre des problèmes complexes. Dans ces scénarios, même de petits retards peuvent être amplifiés.
Pour cette raison, Google a repensé l’architecture pour réduire la latence et améliorer l’efficacité.
Dépasser la limite de mémoire
L’un des principaux goulots d’étranglement des systèmes d’IA est ce qu’on appelle «mur de mémoire», c’est-à-dire la difficulté d’alimenter le processeur en données à la vitesse nécessaire.
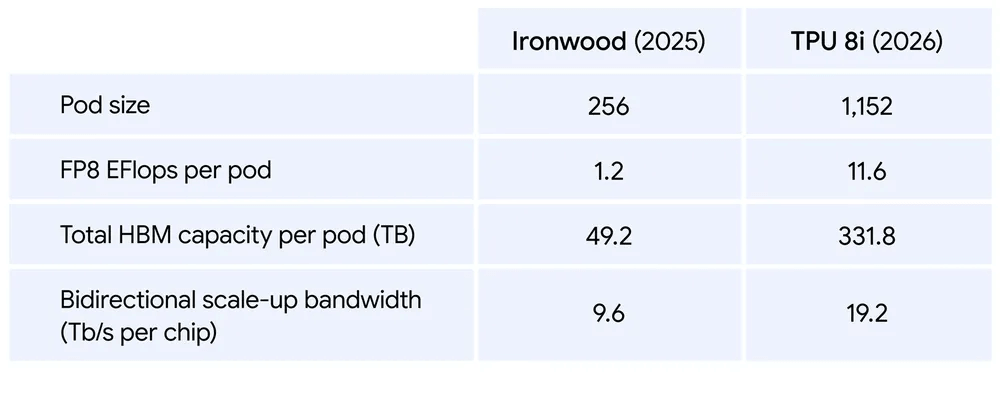
Le TPU 8i résout ce problème en combinant 288 Go de mémoire à large bande passante avec 384 Mo de mémoire SRAM sur puce, soit trois fois plus que la génération précédente.
Cela permet de conserver les données les plus utilisées directement sur la puce, réduisant ainsi les temps d’accès.
Nouveaux processeurs et architectures réseau
Google a également introduit des processeurs propriétaires basés sur l’architecture Arm, appelés Axion. Le nombre d’hôtes par serveur a été doublé, améliorant ainsi la gestion globale du système.
Pour les modèles Mixture of Experts (MoE), de plus en plus populaires, la bande passante d’interconnexion a été augmentée à 19,2 térabits par seconde.
La nouvelle topologie du réseau, appelée Vol de plancheréduit la distance maximale entre les nœuds de plus de 50 %, améliorant ainsi la vitesse de communication.
Réduire la latence des opérations
Une autre innovation concerne la gestion des opérations collectives entre puces.
TPU 8i intègre un moteur dédié, appelé Moteur d’Accélération des Collectifsqui décharge le processeur principal et réduit la latence jusqu’à cinq fois.
Le résultat est une amélioration de 80 % du rapport performances/coût par rapport à la génération précédente.
Selon Google, cela lui permet de servir presque le double du nombre d’utilisateurs pour la même dépense.
Co-conception avec des modèles d’IA
Les nouveaux TPU ont été développés en parallèle avec des modèles d’intelligence artificielle, notamment ceux de Google DeepMind.
Certains choix de conception reflètent les besoins spécifiques des modèles les plus avancés. La capacité de la mémoire SRAM, par exemple, est calibrée pour gérer les caches de modèles de raisonnement.
De même, le réseau Virgo est adapté aux exigences de parallélisme des modèles comportant des milliards de paramètres.
Pour la première fois, l’ensemble du système – du processeur au processeur hôte – est conçu en interne, permettant un contrôle plus précis des performances.
Compatibilité et ouverture aux développeurs
Google se concentre également sur l’adoption par la communauté des développeurs.
Les nouveaux TPU prennent en charge des frameworks populaires tels que JAX, PyTorch et d’autres outils utilisés pour la formation et l’inférence.
Un accès direct au matériel est également fourni (métal nu), sans couches de virtualisation, pour réduire les frais généraux et améliorer les performances.
Parmi les projets open source, Google mentionne MaxText et Tunix, conçu pour faciliter la transition de la recherche à la production.
Le nœud énergétique des centres de données
L’une des principales contraintes au développement de l’intelligence artificielle est la consommation d’énergie.
Selon Google, aujourd’hui, dans les centres de données, la limite n’est pas seulement la disponibilité des puces, mais aussi la capacité d’alimentation électrique.
Les TPU 8t et 8i sont conçus pour améliorer l’efficacité énergétique jusqu’à doubler par rapport à la génération précédente.
Ceci est réalisé grâce à une gestion dynamique de l’énergie et à une conception matérielle et logicielle intégrée.
Refroidissement et infrastructure
Les nouveaux TPU utilisent des systèmes de refroidissement liquide de quatrième génération, capables de prendre en charge des densités de calcul plus élevées que le refroidissement par air.
Google a également travaillé sur l’architecture des centres de données, multipliant par six la puissance de calcul par unité d’énergie au cours des cinq dernières années.

L’intégration entre puce, réseau et infrastructure physique est l’un des éléments distinctifs de la stratégie de l’entreprise.
Le rôle dans le cloud et le supercalcul
TPU 8t et TPU 8i seront disponibles dans l’offre Google Cloud plus tard cette année.
Les puces feront partie de la plateforme AI Hypercomputer, qui combine du matériel, des logiciels et des outils de gestion en un seul système.
L’objectif est d’offrir aux entreprises une infrastructure complète pour développer et déployer des applications d’IA à grande échelle.
Implications pour le marché
L’introduction de deux puces distinctes signale un changement dans la concurrence entre les fournisseurs d’infrastructures d’IA.
La séparation entre formation et inférence reflète la maturation de l’industrie, où l’utilisation opérationnelle des modèles devient aussi centrale que leur création.
Des entreprises comme Titres de la Citadellecités par Google parmi ses clients, utilisent déjà ces technologies pour des applications avancées.
Conclusion
Avec TPU 8t et TPU 8i, Google renforce le contrôle sur l’ensemble de la chaîne d’approvisionnement de l’intelligence artificielle, du silicium aux centres de données.
La stratégie se concentre sur la spécialisation, l’efficacité énergétique et l’intégration verticale. L’objectif est d’accompagner une phase dans laquelle les agents d’IA deviennent des outils opérationnels, avec des impacts directs sur les métiers et les services.
La disponibilité à grande échelle des nouvelles puces constituera un test pour voir dans quelle mesure ces innovations pourront se traduire en avantages concrets pour le marché.