

Tout commence par demander une chose à une IA. Lorsque l'IA est demandée pour les autres, le chaos commence
Dans le jeu du « téléphone sournois » (ou cassé, ou cassé), un groupe de personnes transmet un message d'un à un à un groupe secret. Ce qui se passe généralement, c'est que le message d'origine n'a pas grand-chose à voir avec ce que le dernier destinataire reçoit. Et le problème que nous voyons est que quelque chose de similaire peut se produire avec les agents prometteurs de l'IA.
Erreurs accumulées. Toby Ord, chercheur de l'Université d'Oxford, a récemment publié une étude sur les agents de l'IA. J'y ai parlé de la façon dont ces types de systèmes ont le problème d'erreur accumulée ou composée. Un agent AI atteint plusieurs étapes de manière autonome pour essayer de résoudre un problème que nous proposons – par exemple, créez du code pour une certaine tâche – mais si vous faites une erreur en une étape, cette erreur s'accumule et devient plus inquiétant dans la prochaine étape, et plus dans le prochain, et encore plus dans le prochain. La précision de la solution est donc compromise et peut ne pas avoir beaucoup (ou rien) à voir avec celle qui résoudrait vraiment le problème que nous voulions résoudre.
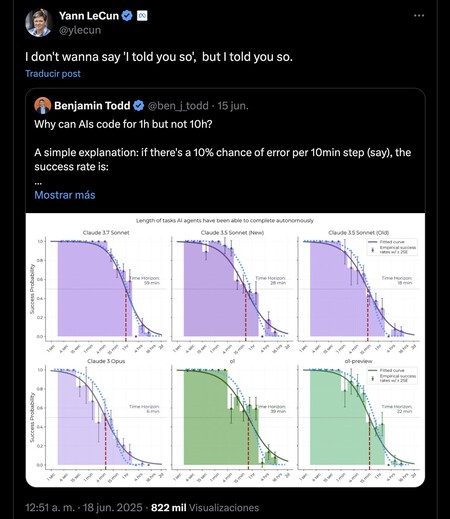
L'IA peut programmer, mais pas pendant longtemps de suite. Ce que cet expert a soulevé, c'est l'introduction de la «demi-vie» si appelée de l'agent d'IA, ce qui aiderait à estimer le taux de réussite en fonction de la durée de la tâche qu'un agent d'IA souhaite résoudre. Par exemple, un agent d'une demi-vie aurait un succès de 50% dans les tâches de deux heures. Le message est écrasant: plus un agent d'IA fonctionne longtemps, plus le taux de réussite diminue probablement. Benjamin Todd, un autre expert en IA, l'a exprimé différemment: une IA peut planifier une heure sans (à peine) d'erreurs, mais pas pendant 10 heures. Ce ne sont pas des chiffres réels ou définitifs, mais expriment le même problème: les agents de l'IA ne peuvent pas – du moins pour le moment – la fonction indéfiniment, car les erreurs accumulées condamnent le taux de réussite.
Les humains sont sauvés. Mais soyez prudent, car quelque chose de très similaire se produit avec les performances humaines dans des tâches prolongées. Dans l'étude ORB, il a été souligné comment le taux de réussite empirique baisse remarquablement: après 15 minutes, il est déjà d'environ 75%, après une heure et demie de 50% et après 16 heures de seulement 20%. Nous pouvons tous faire des erreurs lors de l'exécution de certaines tâches enchaînées, et si nous faisons une erreur dans l'un d'eux, dans la tâche suivante de la chaîne, cette erreur condamne encore plus tout développement ultérieur.
LeCun a déjà averti. Yann LeCun, qui dirige les efforts de recherche de l'IA dans la ligne d'arrivée, notait les problèmes avec les LLM depuis longtemps. En juin 2023, il a indiqué comment les LLMs auto-donnés ne peuvent pas être factuels et éviter les réponses toxiques. Il a expliqué qu'il y a une forte probabilité que le jeton qui génère un modèle nous emmène en dehors du groupe de réponses correctes, et plus la réponse est longue, plus elle est difficile.
C'est pourquoi la correction des erreurs. Pour éviter le problème, nous devons réduire le taux d'erreur des modèles d'IA. Il est très bien connu dans les logiciels Ingería, où il est toujours recommandé d'effectuer une revue de code précoce à la suite d'une stratégie de « Shift Left » pour le cycle de développement des logiciels: la plus tôt une erreur est détectée, le plus facile et plus bon marché est de le corriger. Et tout le contraire ne se produit pas si nous ne le faisons pas: le coût de la correction d'une erreur augmente de façon exponentielle plus tard, il est détecté dans le cycle de vie. D'autres experts suggèrent que l'apprentissage du renforcement (apprentissage par renforcement, RL) pourrait résoudre le problème, et ici LeCun a répondu que cela le ferait si nous avions des données infinies pour polir le comportement du modèle, ce que nous n'avons pas.
Plus que des agents, multi-agents. En anthropique, ils ont récemment démontré comment il existe un moyen d'atténuer encore plus d'erreurs (et des erreurs accumulées ultérieures): utilisez des systèmes multi-agents. Ceci est: que plusieurs agents d'IA fonctionnent en parallèle, puis confrontent leurs résultats et déterminent le chemin ou la solution optimale.
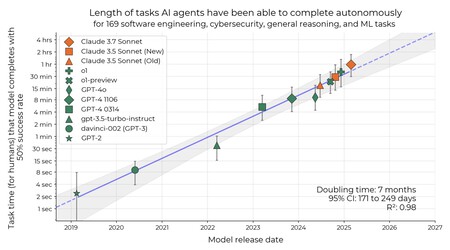
Le graphique montre la longueur des tâches que les agents de l'IA peuvent terminer complètement au cours des dernières années. L'étude révèle que le temps qu'un agent d'IA peut fonctionner pour effectuer des tâches avec un taux de réussite de 50% peut être plié tous les sept mois. Ou quel est le même: les agents s'améliorent dans une voie soutenue (et notable) au fil du temps.
Mais les modèles et les agents n'arrêtent pas de s'améliorer (ou non?). Todd lui-même a visé quelque chose d'important et cela permet d'être optimiste quant à ce problème. « Le taux d'erreur des modèles d'IA est réduit de moitié environ tous les cinq mois », a-t-il expliqué. Et à ce rythme, il est possible que les agents de l'IA puissent accomplir avec succès des dizaines de tâches enchaînées en un an et demi et des centaines en un an et demi plus tard. Dans le New York Times, ils n'étaient pas d'accord et ont récemment souligné que bien que les modèles soient de plus en plus puissants, ils « hallucinent également » plutôt que les générations précédentes. La carte système « O3 et O4-Mini indique précisément qu'il y a un vrai problème avec le taux d'erreur et les » hallucinations « dans les deux modèles.
Dans Simseo | Les hallucinations sont toujours le talon d'Achille de l'IA: les derniers modèles OpenAI inventent davantage le compte