

Tencent Lancia Hunyuan Turbo S, modèle « pensée rapide »
TExercer – L’une des plus grandes sociétés technologiques chinoises, fondées en novembre 1998 par Ma Huateng et Zhang Zhidong, basée à Shenzhen – récemment révélée Hunyuan Turbo Sun modèle de pensée rapide Nouvelle génération qui marque un progrès important dans vitesse de réponse et dans l’optimisation des performances Grands modèles linguistiques.
Hunyuan Turbo S, les principales caractéristiques
Contrairement aux modèles de pensée lente traditionnel comme Deepseek R1 E Hunyuan T1Hunyuan Turbo S offre des « réponses instantanées », améliorant considérablement la vitesse de sortie, a doublé la vitesse de sortie des mots et réduisant la latence du premier mot de 44%. Cette innovation permet au modèle d’exceller dans plusieurs domaines tels que les connaissances, les mathématiques et la création, fournissant une nouvelle solution pour la capacité de réponse rapide des grands modèles.
Hunyuan Turbo S, Capacité d’inspiration et de résolution des problèmes
L’inspiration pour Hunyuan Turbo S dérive du modèle de pensée rapide, sur lequel les êtres humains dépendent de 90% des décisions quotidiennes basées sur l’intuition. Combiné avec le modèle de réflexion lent de l’analyse rationnelle, il offre la capacité de LLM à résoudre les problèmes les plus intelligents et les plus efficaces. À travers la fusion de Chaînes de raisonnement longues et courtesle modèle maintient non seulement une expérience rapide sur les problèmes humanistes, mais améliore également considérablement ses compétences de raisonnement scientifique, entraînant une amélioration globale considérable des performances.
Dans divers tests de référence publics largement utilisés, Hunyuan Turbo S démontre des performances comparables aux principaux modèles tels que Deepseek V3, GPT-4O et Claude.
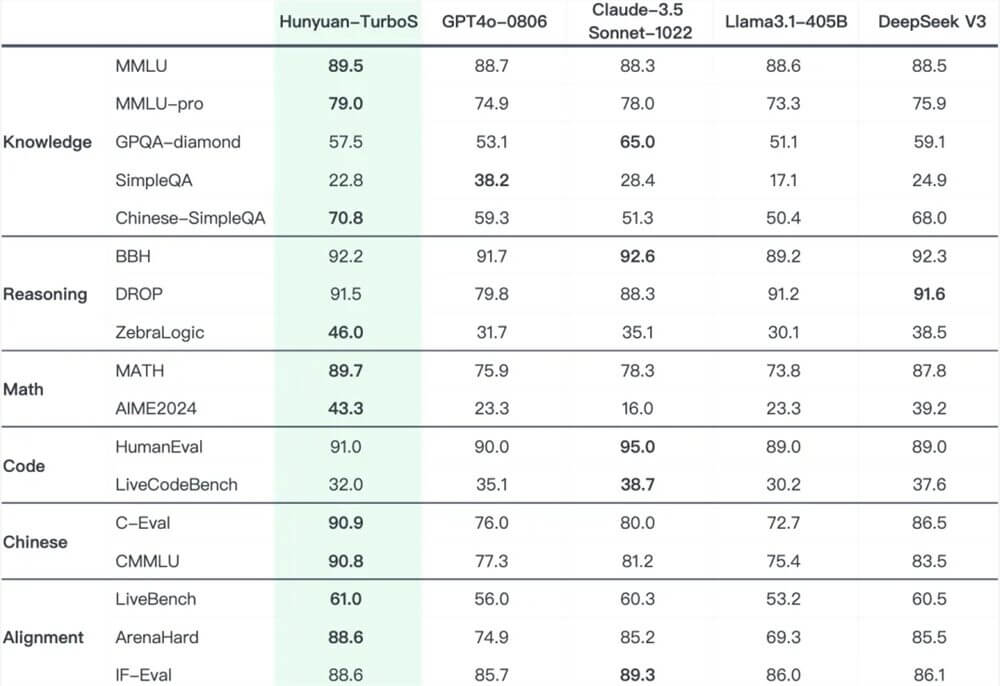
Hunyuan Turbo S, innovation architecturale
En termes d’innovation architecturale, Hunyuan Turbo S adopte un mode de fusion Transformateur hybrideréduisant efficacement la complexité informatique et l’occupation du cache KV-Cache de l’architecture transformateur traditionnelle, réduisant considérablement les coûts de formation et d’inférence. Cette architecture hybride dépasse les défis des coûts élevés de formation et d’inférence associés aux modèles traditionnels de grande taille pour des textes longs, exploitant les avantages de l’architecture Mamba dans la gestion des longues séquences tout en maintenant la capacité du transformateur à capturer des contextes complexes.
Cela marque la première application réussie de l’architecture Mamba aux modèles MOE Ultra-Grandi dans le secteur sans perte de performances.
Hunyuan Turbo S, Disponibilité et prix
En tant que base centrale de la série Hunyuan de Tencent, Hunyuan Turbo S fournira une capacité de base pour les dérivés dans les dérivés d’inférence, les textes longs et le code à l’avenir. Sur la base de Turbo S, Tencent a également lancé le modèle d’inférence T1 avec une capacité de pensée profonde. Ce modèle a été entièrement lancé sur Tencent Yuanbao et sera bientôt disponible via l’accès à l’API.
Actuellement, les développeurs et les utilisateurs de l’entreprise peuvent accéder à Hunyuan Turbo S via API sur le site Web de Tencent Cloud et profiter d’un essai gratuit d’une semaine. Le prix est de 0,8 yuan / million de jeton par entrée Et 2 Yuan / Million Token pour les sortiesune réduction significative par rapport à la génération précédente du modèle turbo Hunyuan. De plus, Hunyuan Turbo S sera progressivement lancé sur Tencent Yuanbao, où les utilisateurs peuvent sélectionner le modèle « Hunyuan ».
Cliquez pour participer à l’essai