

Si la question est de savoir si IA est déjà aussi bonne que l’intelligence humaine, la réponse est: résout ce puzzle
L’Arc Prize Foundation, une organisation à but non lucratif cofondée par le chercheur du François Chollet, a annoncé le lancement d’Arc-Agi-2, un nouvel ensemble de tests qui souhaitent servir à évaluer la capacité des modèles d’IA d’une manière unique. Et il y a la frappe de ces tests.
À quel point nous sommes proches de l’AGI. Alors que d’autres repères mesurent dans quelle mesure les IAS résolvent les problèmes mathématiques ou de programmation, les tests conçus par Chollet et leur équipe essaient d’évaluer à quel point nous sommes étroitement d’une intelligence artificielle générale (AGI). Et pour cela, ils utilisent des preuves qui essaient de mesurer la capacité de percevoir ces modèles, car précisément dans ce domaine, un « vieux » paradoxe entre en jeu.
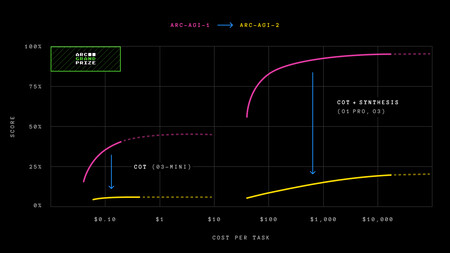
Avec ARC-AGI-2, les modèles qui ont déjà réussi à résoudre une grande partie des problèmes sont désormais bloqués, et la métrique d’efficacité (coût) est l’une des clés.
Le paradoxe de Moravec. En 1988, l’ingénieur autrichien Hans Moravec a déclaré celui qui allait devenir le paradoxe qui porte son nom. L’intelligence artificielle est capable de faciliter la chose difficile, mais cela rend également difficile ce qui est facile pour les humains. Cela est actuellement démontré avec un test très simple: mettez un modèle génératif tel que Chatgpt, Claude, Deepseek ou Gemini pour compter Erres et aura un fatal.
Quelle mesure Arc-Agi? L’idée après les tests ARC-AGI est de mesurer la capacité des systèmes d’IA à généraliser, apprendre et s’adapter à des problèmes complètement nouveaux et à laquelle la réponse n’est pas connue. Il y a beaucoup de concentration sur la capacité de raisonnement abstraite avec des puzzles visuels dans lesquels l’IA doit observer les motifs dans les grilles colorées et générer des solutions en fonction de ces motifs. De plus, ces tests permettent de savoir si l’IA peut résoudre des problèmes pour ceux qui n’ont pas été formés, et également s’ils peuvent généraliser en extraitant des règles sous-jacentes à partir d’exemples simples, puis en les appliquant à de nouvelles situations.

Ça ne vaut pas la peine de tout mémoriser. Dans d’autres types de références, l’IA a l’avantage que « l’ensemble de l’agenda de la mémoire est connu » et n’a besoin que d’appliquer ce qu’elle sait en donnant des réponses qu’elle peut même avoir mémorisées. L’objectif ici est de raisonner et d’extrapoler comme un humain le ferait, et donc cela se concentre sur l’évaluation si nous sommes proches d’un AGI parce que si nous sommes en mesure de vous raisonner. Bien sûr: qu’une IA surmonte ce test ne signifie pas nécessairement que vous avez atteint l’AGI.
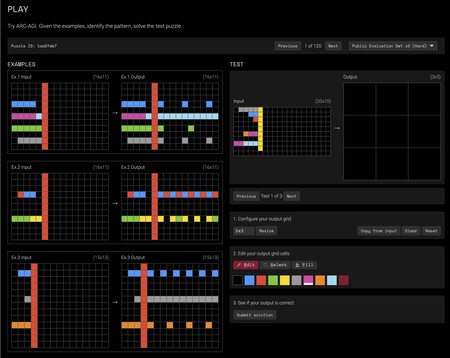
C’est l’un des puzzles visuels qui doit résoudre les modèles d’IA, mais pour les modèles, le problème est très complexe. Pour les humains, pas tellement. Essayez-le;)
Arc-AGI-1 a servi pendant un certain temps. Les modèles de l’IA du début de 2024 se sont écrasés avec la première version d’Arc-Agi, mais à la fin de l’année, des modèles de raisonnement sont apparus et la chose est devenue intéressante. Le modèle O1-MinI d’OpenAI a réussi à dépasser 7,80% des tests, mais O3-Low a atteint 76% et O3-sommet, même coûteux, atteignant 87,5%. Les machines étaient sur le point de niveler et un examen des tests était nécessaire.
Arc-AGI-2 met les choses beaucoup plus difficiles pour l’IA. Les nouveaux tests consistent également en des problèmes similaires aux puzzles visuels qui font que l’IAS identifie les modèles visuels. Les modèles de raisonnement tels que O1-Pro et R1 profondément dépassant à peine 1,3% ARC-AGI-2, et les modèles non rasants (GPT-4.5, Claude 3.7, Gemini 2.0 Flash) ne vont pas de 1%. Et O3-Low, qui, dans la première version d’Arc-AGI, a atteint près de 76% des réponses, atteint à peine 4% dans ARC-AGI-2 et le réalise coûte 200 dollars par tâche. Ce qui est drôle, c’est qu’en moyenne les êtres humains parviennent à réussir 60% des questions, bien plus que tous les modèles actuels. Vous pouvez « jouer » à résoudre ces tests sur le site Web du projet. Nous vous assurons que ce sont des puzzles singuliers et qu’ils vous feront bien sûr réfléchir un peu.

De force brute, rien. Dans l’annonce, les responsables de cette référence expliquent que les modèles ne peuvent pas maintenant recourir à la force brute pour trouver des solutions, ce qui était un petit problème dans ARC-AGI-1. Pour éviter cela, la nouvelle métrique d’efficacité est introduite, ce qui nécessite que les modèles interprètent ce qu’ils voient en temps réel, qu’ils « perçoivent », ne répondent pas en fonction de la mémorisation.
Les modèles d’IA devraient être plus l’effort. Mike Knoop, l’un des responsables du développement de ces tests, a expliqué comment Arc-AGI-2 est « la seule référence qui n’a toujours pas été surmontée par les modèles d’IA, mais cela est toujours facile pour les humains ». Dans les nouveaux tests, il est vu selon lui comment les modèles de l’IA n’attribuent pas de semi -art à ces puzzles – quelque chose que nous faisons intuitivement – et passez un mauvais moment s’ils doivent appliquer simultanément plusieurs règles pour résoudre le problème.
Arc-agi bos et inconvénients. Ces tests sont bien sûr une approche unique qui vous permet d’essayer d’évaluer un aspect des modèles actuels de l’IA que d’autres tests ne mesurent pas, mais il y a un danger ici: que ceux qui développent ces modèles « truque » ou personnalisent pour les concentrer pour résoudre avec précision ce type de puzzles visuels, bien que plus tard dans d’autres types de généralisation, les modèles échouent. Malgré cela, ils représentent une façon frappante d’influencer le développement de nouveaux modèles d’IA, et qui est également intéressant. Assez de savoir: ce que nous voulons, c’est qu’ils raisonnent comme nous les êtres humains et nous nous adaptons à de nouvelles situations et problèmes.
Nous avons besoin que vous demandiez des choses que personne n’avait demandé. La conversation sur l’IA ces derniers temps augmente un dilemme: les IAS ont toutes les réponses à des problèmes simples, mais ne demandez pas de choses que personne n’avait pensé. Les critiques des modèles actuels mettent en évidence la façon dont les IAS ne génèrent pas de nouvelles connaissances – ils ne découvrent pas de nouveaux médicaments, de nouveaux matériaux ou la solution pour la fusion nucléaire – mais sont limitées à combiner ce que nous savons déjà pour essayer d’ouvrir de nouveaux chemins. Cela peut aider les chercheurs humains, mais il n’est pas attendu de la grande révolution de l’IA.
Image | Joshua Hoehne
Dans Simseo | Le gouvernement d’Espagne veut que tout le contenu de l’IA porte un « label ». Cela semble très bien, mais c’est un énorme défi