
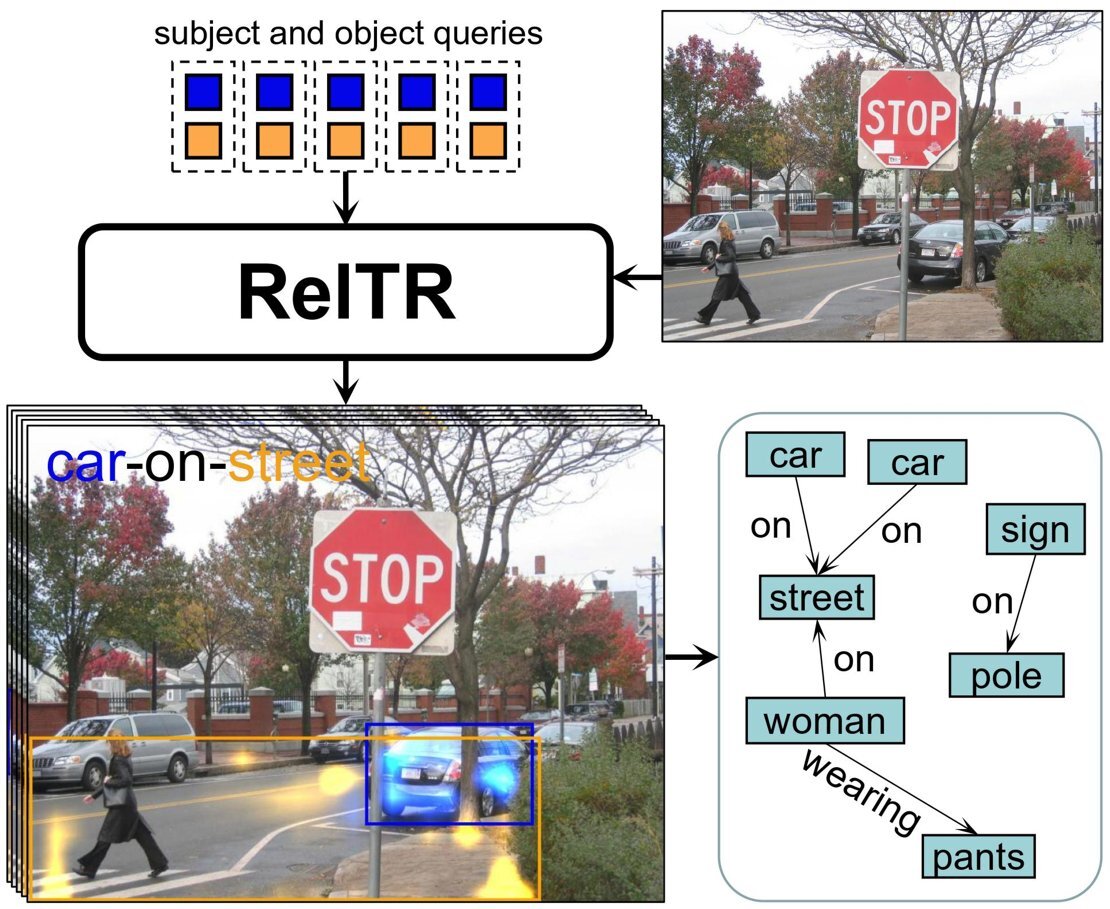
Nouvelle méthode d’IA pour représenter graphiquement des scènes à partir d’images
Crédit : Université de Twente
Les programmes d’IA générative peuvent générer des images à partir d’invites textuelles. Ces modèles fonctionnent mieux lorsqu’ils génèrent des images d’objets uniques. Créer des scènes complètes est toujours difficile. Michael Ying Yang, chercheur à l’UT de la faculté de l’ITC, a récemment mis au point une nouvelle méthode permettant de représenter graphiquement des scènes à partir d’images pouvant servir de modèle pour générer des images réalistes et cohérentes. Lui et son équipe ont récemment publié leurs découvertes dans la revue Transactions IEEE sur l’analyse de modèles et l’intelligence artificielle.
Les humains sont excellents pour définir les relations entre les objets. « Nous pouvons voir qu’une chaise est posée sur le sol et qu’un chien marche dans la rue. Les modèles d’IA trouvent cela difficile », explique Yang, professeur adjoint au Scene Understanding Group de la Faculté des sciences de la géo-information et de l’observation de la Terre ( ITC). L’amélioration de la capacité d’un ordinateur à détecter et à comprendre les relations visuelles est nécessaire pour la génération d’images, mais pourrait également aider à la perception des véhicules et des robots autonomes.
Du bi-étagé au mono-étagé
Actuellement, des méthodes existent pour représenter graphiquement une compréhension sémantique d’une image, mais elles sont lentes. Ces méthodes utilisent une approche en deux étapes. Au début, ils cartographient tous les objets d’une scène. Dans la deuxième étape, un réseau de neurones spécifique passe par toutes les différentes connexions possibles, puis les étiquette avec la relation correcte.
Le nombre de connexions que cette méthode doit traverser augmente de manière exponentielle avec le nombre d’objets. « Notre modèle ne prend qu’une seule étape. Il prédit automatiquement les sujets, les objets et leurs relations en même temps », explique Yang.
Détecter les relations
Pour cette méthode en une étape, le modèle examine les caractéristiques visuelles des objets de la scène et se concentre sur les détails les plus pertinents pour déterminer les relations. Il met en évidence les domaines importants où les objets interagissent ou se rapportent les uns aux autres. Ces techniques et relativement peu de données de formation suffisent pour identifier les relations les plus importantes entre différents objets. La seule chose qui reste à faire est de générer une description de la façon dont ils sont connectés.
« Le modèle détecte que, dans un exemple d’image, l’homme est très susceptible d’interagir avec la batte de baseball. Il est ensuite formé pour décrire la relation la plus probable : » homme-balance-batte de baseball « », explique Yang.