

Nous avons parlé aux créateurs d’Alia, la 100% espagnole, pour comprendre son avenir
Ce lundi, le lancement des modèles de langue Alia a été annoncé. L’initiative se développe depuis des années et c’est maintenant que les premiers fruits sont toujours modestes, mais prometteurs.
Pour en savoir plus sur Alia, à Simseo nous avons parlé avec Marta Villegas (@Martavillegasm), responsable de l’unité de technologie linguistique du Barcelone Supercomputing Center (BSC). Cela nous a permis de clarifier le statut du projet, ses objectifs et ses défis à venir.
De rivaliser avec chatgpt, rien
La première chose que nous voulions savoir est comment Alia avait été créée, et ici Marta Villegas a précisé que le modèle est basé sur l’architecture de la flamme – le méta-modèle open source – « mais le modèle a été formé à partir de zéro et avec des pesos initiaux à zéro«

Ceci est important car Alia n’est pas un modèle basé sur la flamme qui a été fait un processus de raffinement ou de «réglage fin». Dans ces cas, cet expert a expliqué: « Des parties d’un modèle formé avec d’autres données et des poids initialisés, et vous le faites pour adapter ce modèle à vos besoins, soit parce que vous avez plus de données et que vous voulez qu’elle soit meilleure ou parce que vous pouvez veulent l’adapter à un domaine particulier. «
Mais ici, il nous a dit: « Le vocabulaire (jeu de jetons) est complètement différent. » Dans d’autres modèles, le corpus ou l’ensemble de données de formation peut être principalement en anglais, ce qui rend l’ensemble de jetons autorisé calculé via l’anglais. Cela, dit Villegas, le ferait s’adapter moins efficacement aux autres langues.
C’est précisément ce qui a été recherché avec Alia: réduire la pertinence de l’anglais pour augmenter celle de 35 langues de l’Union européenne et, en particulier, espagnol, catalan, basque et galicien.
Comment Alia s’est formé
Le processus de formation Alia a commencé avec quelques expériences en avril 2024. C’est nécessaire car comme l’a expliqué Villegas, « La formation ne donne pas le bouton Après avoir alimenté les données et il y a déjà « . Il était nécessaire de garder à l’esprit que Marenostrum 5, le supercalculateur situé et géré par le BSC, venait de conclure tout pouvoir et il y avait une forte demande à l’utiliser.

Marenostrum 5
Dans ce processus de formation, le projet Alia a eu une disponibilité progressive de la capacité informatique de Marenostrum 5. Bien que pendant un court laps de temps, ils ont eu accès à 512 des 1 120 nœuds spécialisés du supercalculateur, 256 nœuds ont été utilisés pendant plusieurs mois et depuis septembre, ils sont en utilisant 128 nœuds, « qui sont nombreux », Villegas se démarque.
Pendant le processus de formation, je nous ai dit, il y a des « points de contrôle », dans lesquels il est possible d’évaluer comment se déroule le processus de formation. Ces «pauses» permettent également de mettre à jour certaines données de formation, comme en fait se sont produits dans ce processus dans lequel à un moment donné, ils ont introduit un nouveau corpus avec une grande qualité qui a permis de remplacer certaines données qu’ils avaient.
Ce n’est que le début: c’est « pour » instruire « et » aligner « Alia
Villegas a expliqué qu’Alia est un modèle fondamental: il n’est pas prêt à être une alternative à Chatgpt. Ce dernier est basé sur GPT-4, un modèle fondamental beaucoup plus ambitieux et qui avait beaucoup plus d’investissement.
Ici, vous devez différencier le modèle de fondation des modèles « instruits » et « alignés » avec lesquels nous interagissons habituellement. Comme cet expert l’a indiqué, « Alia-40b est un modèle fondamental qui Il n’est pas instruit ou aligné. Pour faire d’un modèle un chatppt et comprendre la conversation et avoir de la mémoire et être « politiquement correct », le modèle fondateur (qui apprend seulement à dire le jet suivant) va dire beaucoup de textes. «
Malgré cela, l’objectif est d’élever ces options progressivement. « En mars, la version éduquée d’Alia-40b devrait être lancée, avec un premier ensemble d’instructions ouvertes », nous a expliqué Villegas. Ces instructions vont être sous-traitantes – celles qui permettent d’instruire ces modèles – et un million d’euros seront investis dans cet ensemble d’instructions nulles.
Ces données seront également publiées afin qu’elles soient disponibles pour les institutions et les développeurs: s’il a été payé avec de l’argent public, explique Villegas, il est logique que ces données soient également publiques, ce qui ne se produit généralement pas avec d’autres modèles de l’IA Des entreprises privées.

Alors que l’instruction des modèles d’IA permet de fournir des indications sur la façon de répondre et de définir le contexte et le but de ces réponses, l’alignement résout des problèmes tels que celui de Évitez les biais discriminantsempêcher la désinformation ou protéger la vie privée.
Ce manque d’alignement signifie précisément que lors de l’utilisation de ces modèles dans cette phase initiale, des réponses avec des erreurs et des biais qui sont précisément atténués avec cette phase d’alignement peuvent être produites.
Alia et concurrence: il n’est ni un rival de chatpt ni prétend
En fait, Villegas souligne: « L’objectif n’est pas de rivaliser avec Chatgpt, car nous aurions besoin de 5 000 millions de dollars ». Alia-40b « est un bon modèle, et vous pouvez faire un chatbot à l’avenir parce que l’intention est de l’instruction et de l’aligner, mais cela prendra du temps. »

Au sein de la famille Alia, nous avons les modèles Salamandra (2b et 7b), plus petits et plus modestes, mais qui ont déjà instruit les versions. Ses performances et sa capacité ont toujours une marge d’amélioration, mais ce sont de bons points de départ pour l’avenir.
Il était inévitable de se demander comment il a l’intention de rivaliser, puis avec d’autres modèles, à la fois fermés et développés par des sociétés privées et des modèles open source. Pour elle « il existe une demande de modèles intermédiaires que chacun peut ensuite s’adapter à son cas d’utilisation spécifique, tout le monde ne peut pas utiliser Chatgpt pour des raisons telles que la vie privée ou le cas d’utilisation ».
Villegas voulait également souligner comment ces modèles plus petits peuvent avoir des performances exceptionnelles dans des tâches spécifiques, et peuvent fonctionner à des niveaux de sécurité et ne pas partager des données importantes.
L’objectif n’est pas de rivaliser avec Chatgpt, car nous aurions besoin de 5 000 millions de dollars
Non seulement cela, il révèle: « Nous obtenons également celui que nous obtenons en tant que pays, nous avons une distribution de jeunes chercheurs qui ont une grande expérience dans ce domaine, et générer cette carrière de personnes est importante. »
Villegas n’a pas pu nous fournir des données sur les deux premiers projets auxquels Alia sera appliquée. Lors du lancement, il a été question d’un chatbot interne qui promet d’accélérer le travail de l’agence fiscale et une solution pour la médecine de soins primaires qui permettront « un diagnostic précoce et le plus précis de l’insuffisance cardiaque ».
Les prochaines étapes d’Alia
Au fur et à mesure que cet expert avançait, il est prévu que dans deux ou trois mois, nous aurons une version instruite d’Alia pour pouvoir utiliser dans un peu plus de la façon dont nous utilisons Chatgpt maintenant, par exemple.
Pour ce qui reste de l’année à part ce lancement d’instructions pour instruire le modèle, l’objectif est d’avoir une première version d’alignement qui abordera ce que nous avons maintenant avec Chatgpt, Claude ou Gemini, par exemple.
Il est également important d’avoir un modèle de ces caractéristiques car comme l’explique Villegas, cela « permet de générer des données synthétiques pour entraîner des modèles plus petits et très spécifiquesen plus de l’utiliser dans les applications de toutes sortes. «
Il y a une autre curiosité: le « grand » modèle, Alia-40b, peut également être utilisé comme une sorte de « juge » (LLM en tant que juge) qui permet d’évaluer et de juger la qualité et la précision des réponses générées par d’autres modèles d’IA . C’est un moyen d’instruire et d’aligner des modèles plus petits, ce qui rend la pertinence de l’ALIA-40b encore plus claire comme base pour l’avenir.
C’est Alia à l’intérieur
Comme indiqué par les données publiées dans HuggingFace, Alia-40b est une famille de modèles multi-lengtuage pré-crués à partir de zéro. Il a variantes de 2b, 7b et 40b, et est publié avec une licence open source. Plus précisément, avec la licence Apache 2.0. Tous vos scripts de formation, vos fichiers de configuration et vos poids sont disponibles dans le Référentiel GitHub.
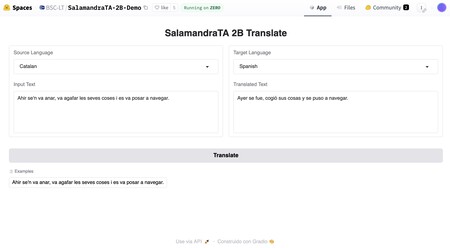
La démo de Salamandra-2b est disponible en face d’étreinte pour les tâches de traduction. C’est un bon moyen de tester cette fonction de ce modèle.
Pour leur formation, 6,9 milliards de jetons de données «très filtrés» avec des textes et du code de 35 langues européennes ont été utilisés. L’ensemble de données de formation est également largement détaillé dans le Alia-Kit Sur le site Web du projet, quelque chose qui remercie particulièrement et offre une transparence totale au projet.
Tous les modèles Ils ont été formés au supercalculateur de Marenostrum 5 Géré par Barcelone Supercomputing Center – National Supercomputing Center (BSC -CNS). Il se compose de 1 120 nœuds, chacun disposant de quatre cartes Nvidia Hopper avec 64 Go de mémoire HBM2, deux processeurs Intel 8460 et Sapphire Rapids, 512 Go de mémoire principale (DDR) et 460 Go de stockage.
Les données pré-formation se sont concentrées sur la donnée d’importance à l’espagnol, au catalan, au galicien et au basque. Les données et le code en anglais ont été réduits de moitié, ceux de ces langues utilisés en Espagne ont été doublés et le reste des langues traitées était la même. Ainsi, l’anglais représente 39,31% de ces données, pour 16,12% des espagnols, 1,97% du catalan, 0,31% du galicien et 0,24% du basque.
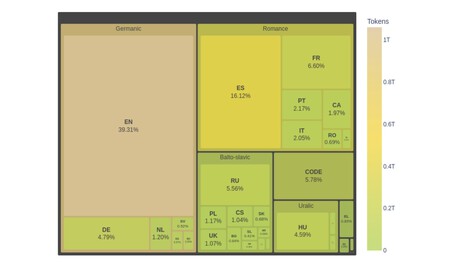
Il s’agit de la structure des langues « Corpus » utilisées pour entraîner Alia.
La principale source de données de formation est un ensemble de données (ensemble de données) appelé Oscar colossal (Open Source Germed a rampé Corpus convenu), qui représente 53% du total des jetons. Il existe de nombreux autres ensembles de données, parmi lesquels sont par exemple Catalogue (le plus grand ensemble de données au monde en catalan) ou Être juridiqueavec les données de la BOE, du Sénat ou du Congrès.
Images | BSC | Alia
Dans Simseo | L’UE veut raccourcir les distances dans la course à l’IA avec 750 millions d’euros. Et ils sont une bonne nouvelle pour Barcelone