
Meta a construit un jumeau numérique du cerveau humain
Imaginez 720 personnes. Chacun couché dans une voiture IRMfimmobile, les yeux ouverts sur un écran. Ils regardent des films. Ils écoutent des podcasts. Ils regardent des images. Ce faisant, la machine enregistre en temps réel l’évolution de l’activité cérébrale, des millions de personnes voxelsdes milliers de mesures par seconde, pendant des heures. En fin de compte, plus de 1 000 heures de données neuronales brutes s’accumulent : une bibliothèque silencieuse sur la façon dont le cerveau humain réagit au monde.
Ce laboratoire existe vraiment. Il s’appelle Courtois NeuroMod, il est basé à Montréal, et Meta FAIR l’a utilisé comme ensemble de données de base pour construire quelque chose qui, jusqu’à il y a quelques années, aurait ressemblé à de la science-fiction : un modèle d’intelligence artificielle capable de prédire avec une grande précision comment n’importe quel cerveau humain réagit à n’importe quel stimulus audiovisuel, même un cerveau que le modèle n’a jamais « vu » auparavant.
Cela s’appelle Tribe v2.
Le problème que personne ne t’a dit
Pour comprendre pourquoi cette publication est vraiment importante, il faut partir d’un fait inconfortable que le journal officiel met noir sur blanc à partir du résumé : les neurosciences cognitives sont un domaine fragmenté.
Ce n’est pas une autocritique polie. C’est un diagnostic précis. Des décennies de recherche sur le cerveau ont produit des milliers de modèles spécialisés, un pour la vision, un pour le traitement du langage, un pour la réponse auditive et un pour la mémoire de travail. Chacun fonctionne bien dans son propre domaine, chacun construit autour de paradigmes expérimentaux spécifiques. Le problème est que le cerveau humain ne fonctionne pas ainsi. Le cerveau intègre tout simultanément : il voit, entend, interprète, se souvient, anticipe, tout à la fois, tout le temps.
La fragmentation des neurosciences n’est pas un défaut des chercheurs. C’est une conséquence de la complexité du problème. Construire des modèles unifiés de la cognition humaine est l’un des problèmes scientifiques les plus difficiles. Et c’est exactement le problème que Tribe v2 tente d’attaquer.
La déclaration qui clôt le résumé de l’article est, à cet égard, l’une des phrases les plus ambitieuses que Meta ait jamais publiées dans un contexte scientifique :
« Ces résultats établissent l’intelligence artificielle comme cadre unificateur pour explorer l’organisation fonctionnelle du cerveau humain. »
L’intelligence artificielle comme cadre fédérateur pour les neurosciences. Pas comme outil. Comme cadre. Comme un langage commun que les différents silos de la recherche sur le cerveau peuvent enfin partager. Il ne s’agit pas d’une mise à jour du modèle. C’est une proposition de paradigme.
Ce que Tribe v2 fait spécifiquement
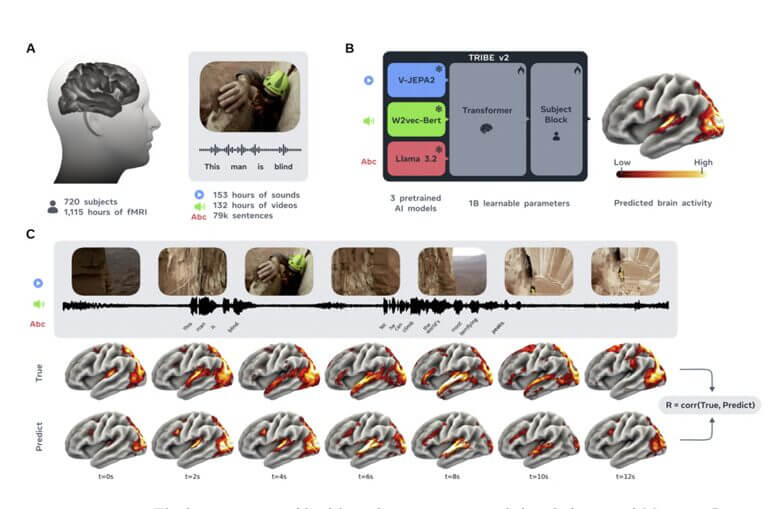
Tribu est l’acronyme de Encodeur cérébral trimodal. Trimodal signifie qu’il traite trois types d’entrée simultanément et de manière intégrée : vidéo, audio, langue. Pas en séquence, pas en parallèle puis concaténés, mais fusionnés en une représentation unifiée qui est ensuite utilisée pour prédire l’activité cérébrale.
Pour construire cette fusion, Meta a combiné trois de ses modèles fondamentaux : Llama 3.2 pour le texte, Wav2Vec2-BERT pour l’audio, V-JEPA 2 pour la vidéo. Trois systèmes qui, à eux seuls, comptent parmi les meilleurs dans leur domaine, connectés via une architecture de transformateur qui apprend à corréler les représentations sensorielles avec les modèles d’activité IRMf enregistrés chez des sujets réels.
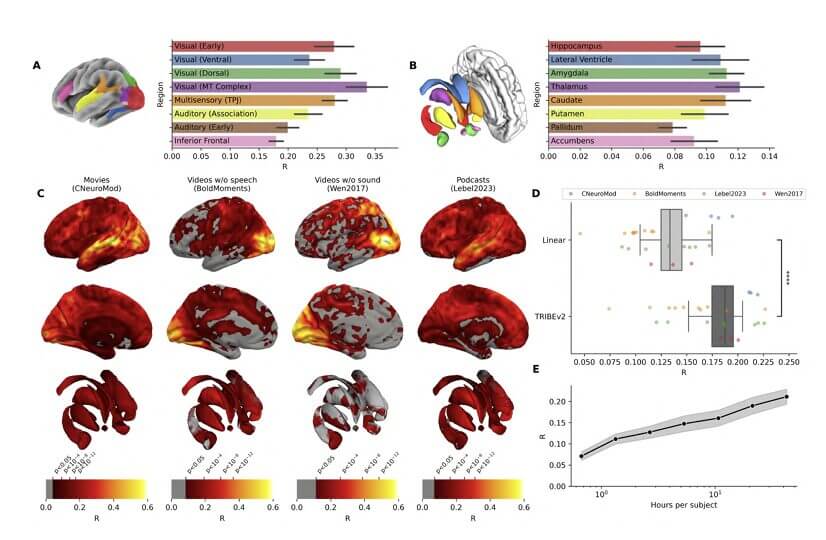
Le résultat est un modèle qui, étant donné un contenu audiovisuel, génère une prédiction de la façon dont le cerveau humain le traiterait, région par région, avec une résolution spatiale 70 fois supérieure à celle de ses modèles précédents et avec une capacité de généralisation que les systèmes précédents n’avaient pas.
Cette capacité à généraliser est le point technique le plus pertinent. Les modèles de codage cérébral plus anciens étaient essentiellement des systèmes de mémoire sophistiqués : ils apprenaient à prédire les réponses d’individus spécifiques à des types spécifiques de stimuli. En dehors de ce périmètre, les performances se sont effondrées.
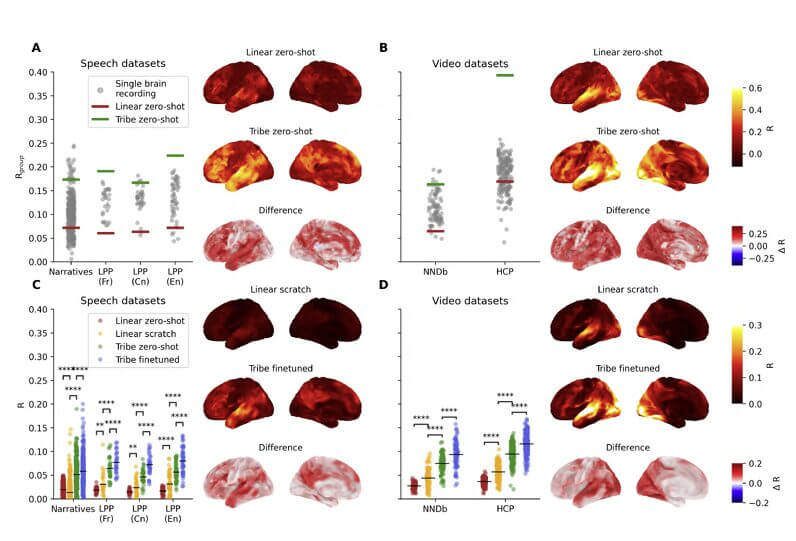
Tribe v2 fonctionne cependant en mode tir nul: exposé à un nouveau sujet, à une nouvelle langue, à un type de stimulus jamais vu en formation, maintient des performances constantes. Il ne récupère pas les modèles stockés. Il généralise une compréhension.
L’amélioration quantitative est presque 2 à 3 fois par rapport aux méthodes précédentes. Mais le saut qualitatif est encore plus grand : pour la première fois, il existe un système qui peut être utilisé comme un outil de recherche général, et non comme un modèle construit ad hoc pour une expérience spécifique.
Le mot qui vaut à lui seul un paragraphe : in silico
Il y a un terme technique dans le titre de l’article qui mérite d’être extrait et expliqué, car il contient les informations pratiques les plus pertinentes de toute la publication : neurosciences in silico.
In vivo signifie sur les organismes vivants. In vitro signifie en laboratoire, sur cultures cellulaires. In silico signifie dans l’ordinateur, simulé numériquement, sans impliquer aucun sujet biologique.
Ce que Tribe v2 permet, c’est la possibilité de faire des neurosciences in silico. Un chercheur qui veut tester comment le cerveau humain réagit à une séquence visuelle spécifique, à un montage, à une variation du rythme narratif, à une combinaison de stimuli sonores et visuels, n’a plus besoin de recruter des sujets, d’obtenir le consentement, de réserver des heures d’IRMf, d’attendre des mois pour collecter suffisamment de données.
Il peut le faire. En quelques minutes.
L’article le démontre sur un test particulièrement significatif : Tribe v2 a été testé sur des paradigmes expérimentaux classiques en neurosciences, des expériences qui ont nécessité des décennies de travail empirique pour être établies, et il a répliqué les résultats de manière autonome, sans que personne ne lui ait fourni ces données. Le modèle, ayant appris la logique sous-jacente du fonctionnement cérébral, « trouve » par lui-même les résultats que la communauté scientifique a construits au cours de soixante années de recherche.
Cela ne veut pas dire que les tests sur les humains deviennent obsolètes. Cela signifie que le cycle de recherche peut s’accélérer radicalement : les hypothèses sont d’abord filtrées in silico, et seules les plus prometteuses sont amenées au laboratoire. Le goulot d’étranglement des neurosciences, le coût énorme de chaque expérimentation sur des sujets réels, se creuse.
Jusqu’à présent, la science. Maintenant l’analyse.
Meta FAIR, la branche de recherche fondamentale de Meta, produit un véritable travail scientifique de classe mondiale. Il n’y a aucune raison d’en douter. Mais Meta est également l’une des plus grandes machines publicitaires de l’histoire, entièrement construite sur la capacité de capter et de maintenir l’attention humaine grâce au contenu audiovisuel.
Il serait naïf de séparer ces deux faits.
Le premier point est technique, et il convient de le souligner : les trois modèles qui composent TRIBE v2, Llama, Wav2Vec-BERT, V-JEPA, n’ont pas été choisis parce qu’ils étaient les meilleurs absolus du marché. Ils ont été choisis car ce sont les modèles de Meta. Tribe v2 est entièrement construit sur l’infrastructure technologique de Meta. Et cette même infrastructure alimente Instagram, Reels, Facebook, WhatsApp.
Le document énonce explicitement l’un des objectifs du projet : utiliser les connaissances du cerveau humain pour construire de meilleurs systèmes d’intelligence artificielle. C’est écrit sans ambiguïté dans le blog d’annonce : « appliquer les connaissances du cerveau pour créer de meilleurs systèmes d’IA ». La boucle est claire : l’IA étudie le fonctionnement du cerveau, et ce qu’elle apprend retourne dans l’IA pour la rendre plus efficace.
Plus efficace pour faire quoi ? Cela dépend de qui l’utilise. Pour un médecin qui travaille sur des troubles neurologiques, cela signifie un diagnostic plus précis. Pour un chercheur, cela signifie des expériences plus rapides. Pour un système de recommandation de contenu, cela signifie mieux comprendre quel stimulus audiovisuel génère quelle réponse cérébrale et optimiser en conséquence.
Personne n’accuse Meta de quoi que ce soit. La recherche est publique, le code est publié sous licence CC BY-NC, l’article est sur ArXiv. Tout est transparent. Mais la question structurelle demeure, et il serait malhonnête de ne pas la poser : l’entreprise qui possède la plus grande plateforme de distribution de contenus audiovisuels au monde vient de construire le modèle le plus avancé qui existe pour prédire la façon dont le cerveau humain réagit aux contenus audiovisuels. Est-ce une coïncidence ? Ou est-ce une direction ?
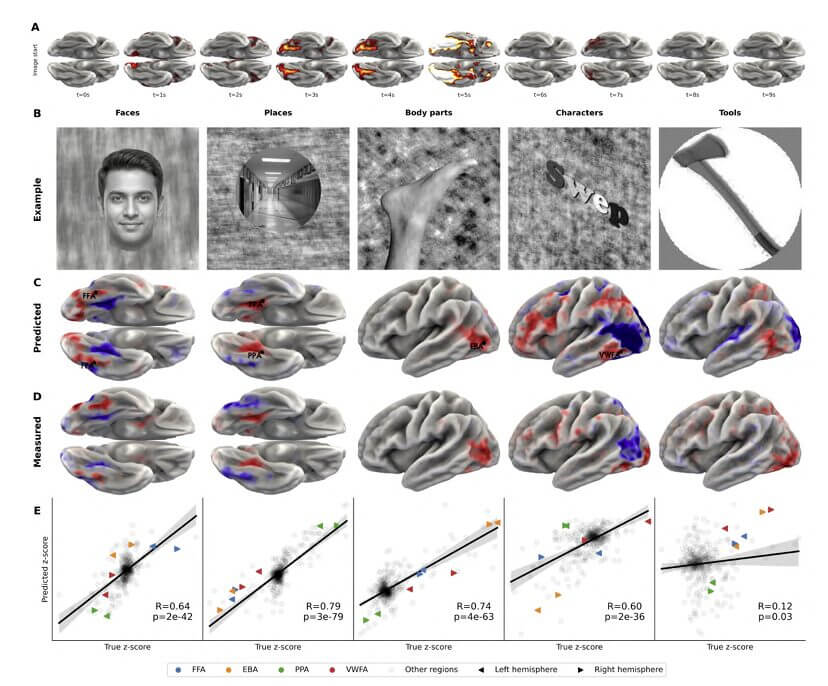
La découverte que personne n’avait prévue
Il y a dans le document un détail que j’ai trouvé le plus fascinant de tous et qui a presque complètement disparu des résumés d’aujourd’hui.
Lorsque les chercheurs ont analysé les caractéristiques latentes internes de Tribe v2, les représentations que le modèle construit en interne lors du traitement des entrées, ils ont découvert quelque chose qu’ils ne recherchaient pas : une carte détaillée de la manière dont le cerveau humain intègre les signaux multisensoriels. Une belle topographie de l’intégration entre la vue, l’ouïe et le langage.
Ce n’était pas l’hypothèse de recherche initiale. C’était un résultat émergent. Le modèle, apprenant à prédire les réponses cérébrales, avait seul organisés en interne leurs représentations d’une manière cohérente avec la structure fonctionnelle du cerveau. Il avait « découvert » quelque chose sur la neuroanatomie de l’intégration sensorielle comme effet secondaire de sa formation.
C’est l’un des modèles les plus intéressants que l’ère des grands modèles ait apporté à la science : les modèles qui apprennent à partir de données réelles à une échelle suffisante ont tendance à internaliser des structures du monde que personne ne leur a explicitement enseignées. GPT a « découvert » des structures grammaticales dont les linguistes débattaient depuis des décennies. AlphaFold a résolu le problème du repliement des protéines que la biologie ne pouvait pas résoudre. Tribe v2 a trouvé la carte d’intégration multisensorielle comme sous-produit d’une tâche prédictive.
Cela suggère quelque chose de plus profond : la frontière entre modélisation et découverte scientifique s’estompe. Un modèle suffisamment général, formé sur des données suffisamment riches, ne se contente pas de prédire, il commence à comprendre.
La question que nous devons nous poser
Meta a tout publié : modèle, poids, code source, papier, démo interactive. Le geste est généreux, ou du moins dans la forme. La substance est plus complexe : sa diffusion sous CC BY-NC signifie que n’importe qui peut l’utiliser à des fins de recherche universitaire, mais pas pour des applications commerciales. Meta reste libre de l’utiliser comme bon lui semble sur ses propres plateformes.
La science ouverte en tant que stratégie écosystémique n’a rien de nouveau. Meta le fait systématiquement avec Llama, avec PyTorch, avec des dizaines d’autres projets FAIR. La diffusion publique crée une communauté, attire des talents, génère des contributions externes, bâtit une réputation scientifique. C’est une décision intelligente, pas nécessairement malhonnête, mais pas neutre.
La dernière question est la suivante : si un système peut simuler avec une précision croissante la manière dont votre cerveau réagit à un contenu, à une vidéo, à une séquence sonore, à une combinaison de stimuli linguistiques et audiovisuels, avant même que vous ne le voyiez, où s’arrête la compréhension du comportement humain et où commence son ingénierie ?
Ce n’est pas une question rhétorique. C’est la question à laquelle seront confrontées les neurosciences computationnelles, l’éthique de l’IA et la réglementation des médias dans les années à venir. Tribe v2 n’est pas la réponse. C’est le moment où la question devient urgente.
Sources
• Article officiel de Meta FAIR : « Un modèle fondamental de vision, d’audition et de langage pour les neurosciences in silico » (ArXiv, 26 mars 2026)
• Blog méta-IA : ai.meta.com/blog/tribe-v2-brain-predictive-foundation-model
• Démo interactive : aidemos.atmeta.com/tribev2