

L’examen MIR 2025 a été particulièrement difficile cette année. Les modèles IA obtiennent un exceptionnel
Nous aimons tester des modèles d’intelligence artificielle dans des examens qui sont généralement complexes pour les êtres humains. En Espagne, l’un de ces examens est précisément MIR, qui permet d’accéder à la formation des médecins spécialistes en Espagne. Comment les modèles IA se comportent-ils avec cet examen?
Un mir particulièrement difficileLes experts de 2025 disent que cela a été un MIR particulièrement difficile. Il est souvent critiqué que l’examen demande généralement des aspects des pathologies rares que même les spécialistes expérimentés ne gèrent pas.
Tester les modèles d’IA. Julian Isla, du département de l’IA de Microsoft, a expliqué à LinkedIn comment lui et son équipe avaient voulu tester plusieurs modèles de conseils pour voir comment ils avaient répondu aux questions de l’examen. L’examen comprend 210 questions de test avec quatre réponses possibles. Certaines des questions sont associées à des images médicales et se consacrent à diverses spécialités médicales.
Source: Joaquín Isla (LinkedIn)
Diverses versions. Les versions disponibles de l’examen ont utilisé des versions 0 à côté des images incluses dans le livret d’image. Les réponses de toutes les versions ont été publiées lundi au ministère de la Santé et ont été républiées sur des sites Web tels que Isanity, qui peuvent être consultés par exemple ceux de la version 0.
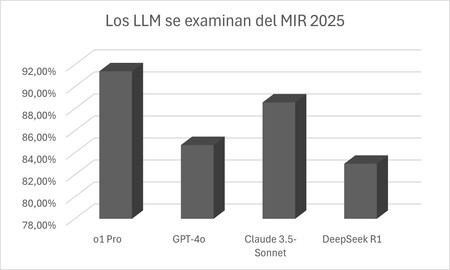
Openai O1 Pro, exceptionnel. Le modèle de raisonnement O1 dans sa version pro, le plus avancé, obtient un spectaculaire 91,7% des réponses correctes. Seuls 17 des 210 ont échoué, et sur ces 17, seuls deux étaient associés à des images. Comme l’explique Isla, même les spécialistes auraient compliqué de répondre à certaines de ces questions.
Claude et GPT-4O n’ont pas besoin de raisonner. Le deuxième meilleur modèle était Claude 3.5 Sonnet, qui a connu un succès de 88,5%, quelque chose de remarquable si nous considérons qu’il ne s’agit pas d’un modèle de raisonnement et peut être blessé par lui. GPT-4O, qui est sur le marché depuis plusieurs mois, a également très bien réussi avec 84,7% de succès.

Deepseek R1, high remarquable. Pour sa part, DePseek R1 a réalisé 83,8% des coups sûrs. Il a échoué en 34 questions. Cela démontre que ce modèle de raisonnement, encore pire que O1 Pro, continue de se comporter de manière fantastique. Il y parvient également avec un investissement beaucoup plus bas dans son processus de formation selon ses développeurs.
Ils ne laissent pas de réponses vierges. Le test de test de test pénalise les réponses incorrectes, ce qui rend ces modèles nocifs car ils répondent toujours, ont ou non la sécurité de la réponse. Julián Isla commente également comment la performance des questions auxquelles il y avait des images associées a été spectaculaire, et un grand saut depuis l’année dernière.
Mais bien sûr, l’IA utilise des côtelettes. Le grand avantage que ces modèles disent, bien sûr, est qu’ils ont été formés avec des millions de données, y compris les données médicales et les connaissances, et cela leur permet d’aller à cette formation – qu’ils ont totalement mémorisée – pour répondre aux questions. C’est comme avoir une gigantesque côtelette, comme si les étudiants examinés pouvaient consulter des livres, des notes ou des Internet pendant le test, quelque chose de totalement interdit.
Image | Simseo avec freepik pikaso
Dans Simseo | Les intelligences artificielles sont sur le point de surmonter les médecins les plus difficiles: comprendre les patients