
Les transformateurs de vision auto-formés imitent le regard humain avec une précision surprenante
Les machines peuvent-elles jamais voir le monde tel que nous le voyons? Les chercheurs ont découvert des preuves convaincantes que les transformateurs de vision (VITS), un type de modèle d'apprentissage en profondeur spécialisé dans l'analyse d'image, peuvent développer spontanément des modèles d'attention visuelle de type humain lorsqu'ils sont entraînés sans instructions étiquetées.
L'attention visuelle est le mécanisme par lequel les organismes, ou l'intelligence artificielle (IA), filtrent le « bruit visuel » pour se concentrer sur les parties les plus pertinentes d'une image ou d'une vue. Bien que naturel pour l'homme, l'apprentissage spontané s'est révélé difficile pour l'IA.
Cependant, les chercheurs ont révélé, dans leur publication récente Réseaux neuronauxqu'avec la bonne expérience de formation, l'IA peut acquérir spontanément une attention visuelle de type humain sans qu'on apprenne explicitement à le faire.
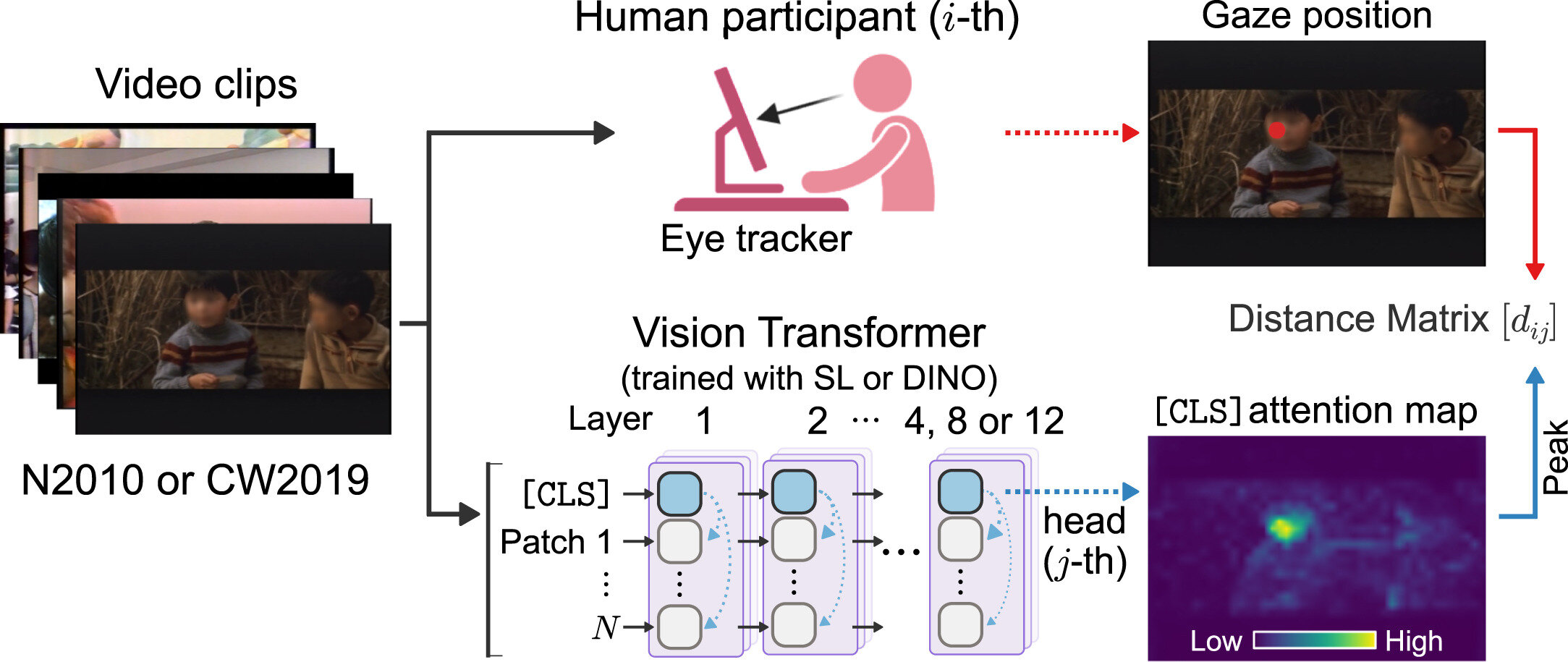
L'équipe de recherche, de l'Université d'Osaka, a comparé les données de suivi des yeux humaines aux modèles d'attention générés par des vites formées à l'aide de Dino (« auto-distillation sans étiquettes »), une méthode d'apprentissage auto-supervisé qui permet aux modèles d'organiser des informations visuelles sans ensembles de données annotés.
Remarquablement, les vites formées en dino ont montré un comportement de regard qui reflétait étroitement celui des adultes en développement généralement lors de la visualisation de clips vidéo dynamiques. En revanche, les vites formées avec l'apprentissage supervisé conventionnel ont montré une attention visuelle contre nature.
« Nos modèles ne s'occupaient pas des scènes visuelles au hasard, ils ont spontanément développé des fonctions spécialisées », explique Takuto Yamamoto, auteur principal de l'étude. « Un sous-ensemble du modèle se concentrait systématiquement sur les visages, un autre a capturé les contours des figures entières, et un troisième a assisté principalement aux caractéristiques de fond. Cela reflète de près comment les systèmes visuels humains segmentent et interprètent les scènes. »
Grâce à des analyses détaillées, l'équipe a démontré que ces grappes d'attention ont émergé naturellement dans les avantages formés en dino. Ces modèles d'attention étaient non seulement qualitativement similaires au regard humain, mais également quantitativement alignés sur les données de suivi des yeux établies, en particulier dans les scènes impliquant des figures humaines. Les résultats suggèrent une éventuelle extension du modèle de perception traditionnel en deux parties en deux parties en psychologie en un modèle en trois parties.
« Ce qui rend ce résultat remarquable, c'est que ces modèles n'ont jamais été informés de ce qu'est un visage », explique l'auteur principal, Shigeru Kitazawa, « pourtant ils ont appris à hiérarchiser les visages, probablement parce que cela a maximisé les informations obtenues dans leur environnement. C'est une démonstration convaincante que l'apprentissage auto-levé peut capturer quelque chose de fondamental sur la façon dont les systèmes intelligents, y compris les humains, apprennent du monde. »
L'étude souligne le potentiel de l'apprentissage auto-supervisé non seulement pour faire progresser les applications d'IA, mais aussi pour la modélisation des aspects de la vision biologique. En alignant les systèmes artificiels plus étroitement avec la perception humaine, les vites autopéralisées offrent un nouvel objectif pour interpréter à la fois l'apprentissage automatique et la cognition humaine.
Les résultats de cette étude pourraient être utilisés pour une variété d'applications, tels que le développement de robots respectueux de l'homme ou pour améliorer le soutien pendant le développement de la petite enfance.
Fourni par l'Université d'Osaka