
L'approche basée sur le clustering accélère l'apprentissage de l'IA dans la robotique et les jeux
Enseigner à l'IA à explorer son environnement, c'est un peu comme enseigner un robot pour trouver un trésor dans un vaste labyrinthe – il doit essayer différents chemins, mais un certain exemple. Dans de nombreux défis du monde réel, comme entraîner des robots ou jouer à des jeux complexes, les récompenses sont rares, ce qui facilite l'IA de perdre du temps sur les impasses.
Pour relever ce défi, les chercheurs de l'Université Nanjing et de l'UC Berkeley ont conçu une façon intéressante d'enseigner l'IA: l'apprentissage en renforcement en grappe (CRL). Au lieu de se promener sans but ou de chasser les grands scores, cette méthode fait des situations similaires dans des « grappes ». Il récompense l'IA pour avoir essayé de nouvelles choses et pour s'appuyer sur les succès passés.
La recherche est publiée dans la revue Frontières de l'informatique.
« En regroupant les expériences et en équilibrant la curiosité avec un succès prouvé, nous avons donné à l'IA un moyen plus humain d'apprendre », explique le professeur Wu-Jun Li, chercheur principal du projet.
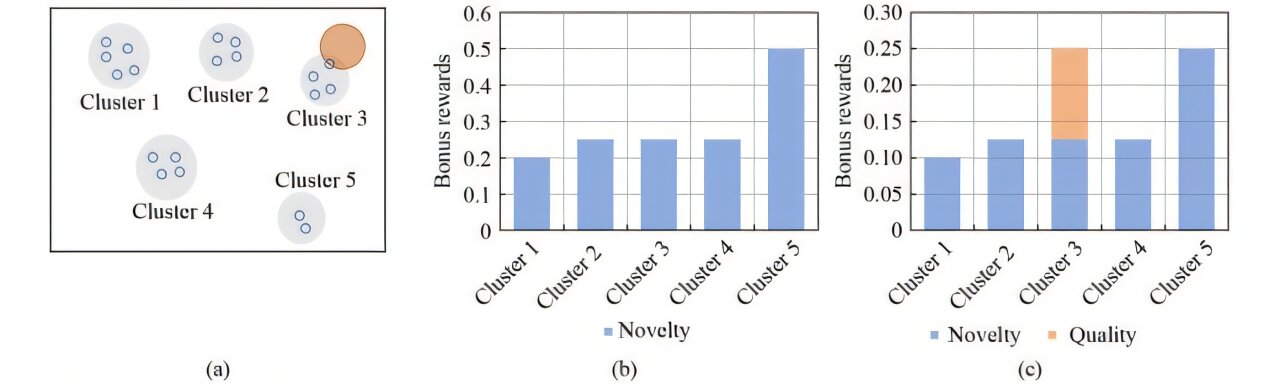
La magie en deux étapes: les expériences de regroupement et les victoires enrichissantes
Alors, comment le CRL réalise-t-il ces victoires? Au lieu de traiter chaque état comme unique et non connecté, CRL groupe des états similaires en grappes en utilisant une technique appelée k-means. Chaque cluster est ensuite analysé pour mesurer deux choses: à quelle fréquence il a été visité (nouveauté) et à quel point le résultat moyen est bon (qualité).
Le CRL attribue des récompenses de bonus en fonction de ces deux facteurs – entravant l'agent pour explorer les domaines qui sont non seulement nouveaux mais aussi susceptibles de donner de bons résultats. Cela contraste avec les méthodes traditionnelles qui ne poursuivent que la nouveauté, conduisant souvent l'agent dans des zones improductives.
Résultats et impact: apprentissage rapide, utilité réelle
En mélangeant la curiosité avec les conseils basés sur les résultats, le CRL permet à l'IA d'apprendre plus rapidement et avec moins d'erreurs. Il a réalisé des performances supérieures sur plusieurs références standard, notamment des tâches de contrôle robotique et des jeux Atari difficiles, surpassant plusieurs méthodes de pointe. De plus, le CRL peut être facilement ajouté aux systèmes d'IA existants comme amélioration modulaire.
Cela le rend particulièrement prometteur pour les domaines à enjeux élevés comme la conduite autonome, l'optimisation d'énergie et la planification intelligente – où l'apprentissage sûr et économe en échantillons est essentiel.
En combinant un clustering simple avec des ajustements de récompense légers, le CRL ouvre la porte à une formation d'IA plus sûre, plus rapide et plus fiable. Alors que les machines intelligentes entrent dans notre vie quotidienne – des robots d'entrepôt à la navigation de la rue des villes – des méthodes comme celle-ci les aideront à apprendre rapidement, à éviter les erreurs coûteuses et à avoir besoin de moins de baby-sitting humain.
Fourni par Higher Education Press