

Gemini 3 à l'épreuve : ce que disent réellement les tests sur le nouveau modèle de Google
L'arrivée du Gemini 3 marque une étape importante dans la course aux modèles génératifs de nouvelle génération. Après les itérations 2.0 et 2.5, Google propose un modèle qui ne se limite pas à augmenter les paramètres et la puissance de calcul, mais se concentre explicitement sur trois axes : un raisonnement plus profond, des agents plus efficaces et une plus grande robustesse en termes de sécurité.
Parler de « tests Gemini 3 », c’est donc dépasser la liste classique des benchmarks, pour comprendre comment Google redéfinit la manière dont se mesure l’intelligence d’un modèle multimodal.
Dans cet article, j'entrelace les résultats officiels avec une série de tests pratiques réalisés personnellement sur le modèle, dans des scénarios de travail réel et de prototypage. LE
En particulier, Gemini 3 Pro et Gemini 3 Deep Think ont été testés dans des contextes de développement de logiciels, d'analyse de documents et de création de contenu, collectant des observations systématiques sur les forces et les limites.

Gemini 3, les variantes Pro et Deep Think
Gemini 3 est présenté en deux variantes principales, Pro et Deep Think, visant à couvrir à la fois des scénarios interactifs à faible latence et des tâches plus complexes nécessitant des chaînes de raisonnement complexes et une planification à long terme. Selon les données officielles, 3.0 Pro surpasse les principaux modèles concurrents dans 19 tests sur 20, et dans des tests comme Humanity's Last Exam, il surpasse la version Pro de GPT-5 par une marge significative, signalant non seulement des progrès incrémentiels mais substantiels dans la compréhension de tâches hétérogènes et très complexes.
Outils d'évaluation
Toutefois, pour interpréter correctement ces résultats, il est nécessaire de se pencher sur les mérites des outils d’évaluation. Depuis des années, la communauté utilise des batteries de référence telles que MMLU pour les connaissances multitâches, GSM8K pour les mathématiques de niveau scolaire, HumanEval pour la génération de code, ainsi que de nouveaux tests multimodaux qui entremêlent texte, images, audio et vidéo.
Dans le cas de Gemini 3, Google met particulièrement l'accent sur les tests de raisonnement compositionnel et d'utilisation d'outils, c'est-à-dire les tâches dans lesquelles le modèle doit décomposer un problème en étapes, invoquer des outils externes et orchestrer les interactions avec des API, des bases de données ou des systèmes d'exécution de code.
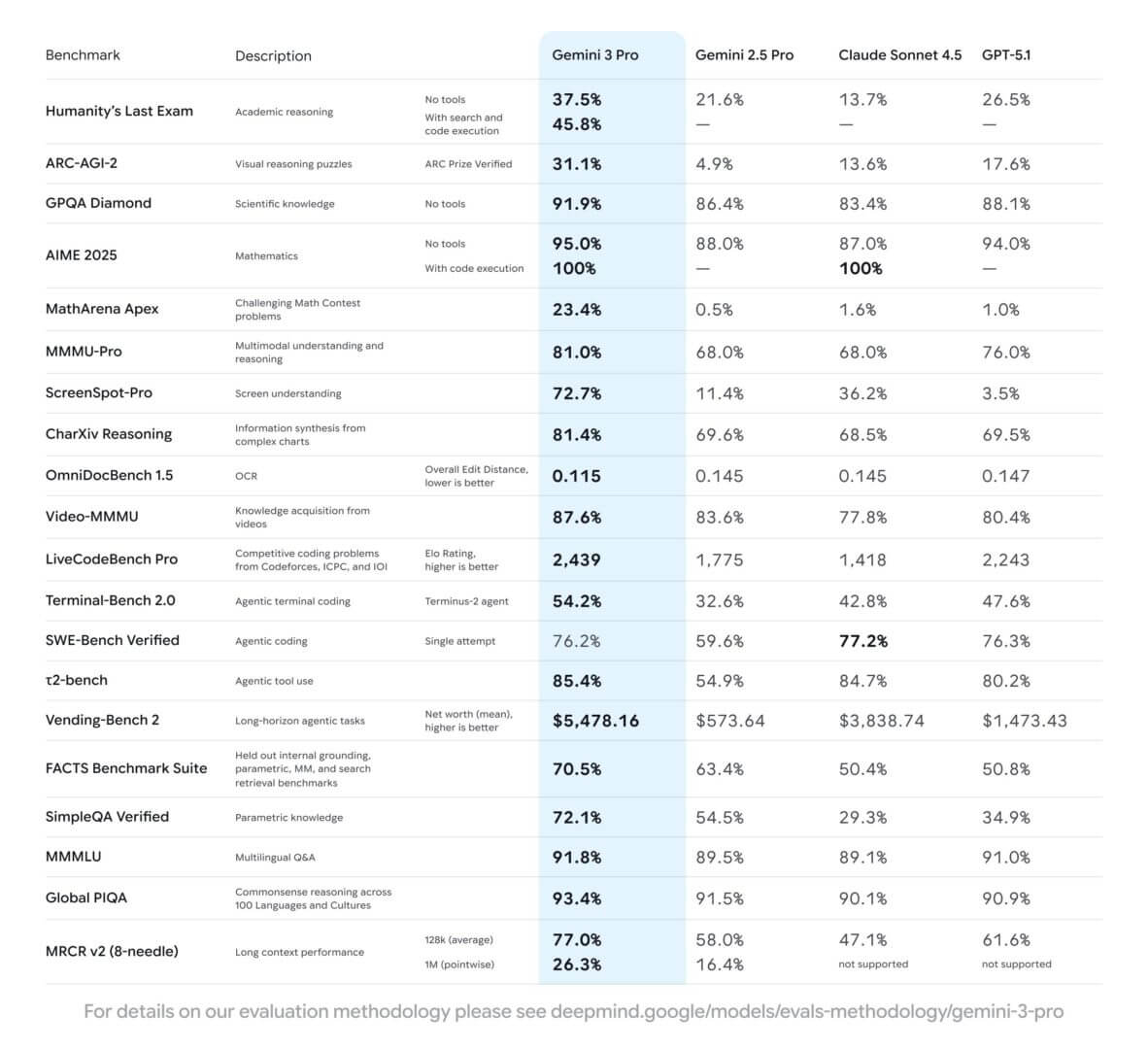
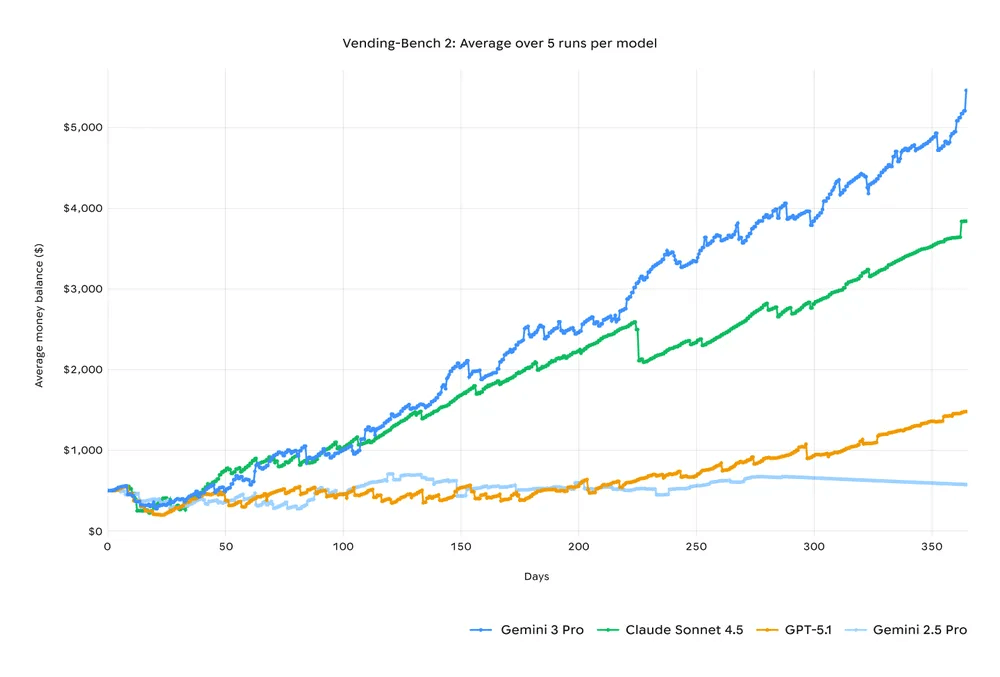
Banc de vente
Un test emblématique en ce sens est le soi-disant Vending Bench, une simulation dans laquelle le modèle doit planifier des actions et utiliser des outils pour résoudre des scénarios de plus en plus complexes, arrivant à raisonner sur les états du monde qui évoluent au fil du temps. Gemini 3 montre ici un saut qualitatif par rapport aux générations précédentes, se rapprochant de ce que l'on attend d'un « agent » plutôt que d'un simple chatbot. Il ne s'agit plus seulement de répondre correctement à une question, mais de maintenir un objectif, de mettre à jour son plan et d'utiliser les ressources externes de manière cohérente.
Gemini 3, modèle multimode
Aux côtés des benchmarks textuels traditionnels, Gemini 3 est évalué en profondeur en tant que modèle multimodal. D'un point de vue pratique, cela signifie tester votre capacité à combiner de manière transparente du texte, des images, de l'audio et de la vidéo, non seulement en tant que canaux d'entrée séparés, mais en tant qu'éléments entrelacés dans la même session.
Les tests comprennent des tâches de compréhension de diagrammes, l'analyse de vidéos avec des événements répartis dans le temps, la description de scènes complexes à partir de séquences d'images et la transformation du contenu visuel en code ou en spécifications structurées.
Une partie intéressante de l'écosystème de test tourne autour de Gemini 3 Pro Image, la base du modèle de génération et d'édition Nano Banana Pro, conçu pour créer des images, des infographies et des diagrammes haute fidélité avec un texte multilingue précis. Ici, l’attention n’est pas seulement esthétique. La cohérence sémantique entre l'invite et l'image, l'exactitude du texte incorporé dans les figures, la capacité à maintenir la cohérence des personnages et des objets sur plusieurs générations et la précision de l'édition locale, telle que les modifications apportées à l'éclairage, au cadrage ou à des éléments spécifiques de la scène, sont mesurées.
Dans ce cas, les benchmarks sont étroitement liés aux tests d'utilisabilité, car le modèle est conçu pour des applications réelles dans les domaines de la communication, du design et du marketing de contenu.
Gemini 3 par rapport aux versions précédentes
La comparaison avec les versions précédentes de Gemini permet de comprendre où se produit le saut. Déjà avec les séries 2.0 et 2.5, Google avait introduit des contextes allant jusqu'à un million de jetons, une compréhension native de l'audio et de la vidéo et une forte concentration sur le raisonnement étape par étape.

Dans de nombreux repères textuels et de codage ces versions étaient déjà compétitives avec les modèles concurrents les plus avancés, les surpassant dans certains cas, notamment dans les tâches qui nécessitaient l'analyse de bases de code ou de documentation volumineuses.
Gemini 3 capitalise sur cette base en étendant le raisonnement multimodal et en déplaçant l'attention des tâches ponctuelles vers des scénarios d'agents interagissant avec des environnements complexes.
Gémeaux 3, sécurité
Une autre dimension cruciale des tests Gemini 3 concerne la sécurité. Cet aspect ressort non seulement de la documentation officielle mais aussi des tests directs que j'ai effectués, dans lesquels le modèle a tendance à remettre en question des instructions ambiguës ou risquées au lieu de les suivre sans esprit critique.
Google décrit le modèle comme le plus soumis à des évaluations de sécurité dans l'histoire interne de l'entreprise, avec un accent particulier sur la réduction des flagorneriec'est-à-dire la tendance du modèle à plaire à l'utilisateur même lorsque celui-ci fait des déclarations incorrectes ou dangereuses, et à résister aux attaques par injection rapide et par jailbreak.
Les tests comprennent à la fois des suites automatisées, dans lesquelles des milliers de invites adverses sont générées et systématiquement variées, ainsi que des évaluations menées par des équipes rouges humaines spécialisées dans la mise en évidence de vulnérabilités liées à la désinformation, à l'abus d'outils ou au soutien de cyberattaques.
Agents IA : la mesure du succès
Ces évaluations de sécurité ont une incidence directe sur les applications d'agents que Google promeut autour de Gemini 3. Dans les outils de développement, depuis AI Studio jusqu'au support dans les frameworks open source pour l'orchestration des agents, les tests se concentrent non seulement sur la précision et la latence mais aussi sur la capacité des modèles à respecter les contraintes politiques, par exemple en limitant l'accès à certaines API en fonction du contexte ou en reconnaissant les requêtes qui tentent de contourner les contrôles existants.
En pratique, cela signifie que la mesure du succès d'un agent n'est plus seulement « résout la tâche », mais « la résout en toute sécurité et conformément aux règles définies ».
Gemini 3 sur le plan industriel
Au niveau industriel, les tests Gemini 3 incluent des scénarios d'utilisation de bout en bout proches des cas réels :
- des assistants développeurs capables d'opérer sur de gros référentiels,
- des systèmes d'aide à la décision qui combinent des données textuelles,
- tableaux et visualisations, outils pour créer du contenu qui partent de notes désordonnées et les transforment en documents structurés ou en storyboards multimédias.
Lors des tests, j'ai utilisé Gemini 3 Pro pour refactorisation du codeanalyse du référentiel et synthèse de la documentation technique de l'entreprise et j'ai observé une réduction tangible des corrections manuelles par rapport à Gemini 2.5 Pro, notamment dans les flux qui nécessitent de maintenir une cohérence entre plusieurs fichiers et plusieurs sources d'informations. Ici, l'évaluation s'étend à des mesures telles que le taux de corrections demandées par l'utilisateur, le nombre d'interventions manuelles nécessaires pour mettre un résultat en production et le gain de temps par rapport aux flux de travail traditionnels.
Il est inévitable que les résultats officiels de Google soient relativisés par rapport aux benchmarks indépendants. Les rapports et analyses menés par des tiers ces dernières années montrent à quel point les grands modèles ont tendance à occuper différentes niches d'excellence, certains étant plus forts sur le codage complexe, d'autres sur l'écriture créative, d'autres encore sur la rapidité et les coûts d'exécution.
Les premiers tests comparatifs incluant Gemini 3 suggèrent que le modèle de Google se positionne au sommet notamment dans les tâches de raisonnement structuré, de planification et d'agence, tandis que la question de la qualité fine de la génération de texte reste plus nuancée et dépend souvent du domaine et du langage de référence.
La gouvernance de Gemini 3
Un élément souvent sous-estimé lors des tests, mais pourtant central dans l’adoption par les entreprises, est la gouvernance du modèle. Avec Gemini 3, Google intègre plus étroitement les journaux d'interaction, les contrôles d'audit et les outils pour définir des politiques personnalisées sur les données et les outils accessibles au modèle. Cela se reflète dans la conception de tests destinés aux entreprises clientes, qui ne se limitent pas à vérifier la qualité des réponses individuelles mais mesurent le comportement du système au fil du temps par rapport aux contraintes réglementaires, aux exigences de confidentialité et à l'intégration avec les processus existants.
L'évolution des tests Gemini 3
Pour l’avenir, les tests qui photographient aujourd’hui l’état de Gemini 3 sont voués à évoluer rapidement. L’intérêt croissant porté aux agents autonomes, à la robotique de modélisation linguistique et visuelle et aux systèmes d’aide à la décision dans des contextes critiques nécessitera des références plus proches du monde réel, capables de capturer non seulement une précision moyenne, mais également des cas limites, des échecs rares et des dynamiques émergentes lorsque plusieurs agents interagissent les uns avec les autres.
Gemini 3, axé sur le raisonnement, la multimodalité et la sécurité, semble conçu précisément pour cette nouvelle phase, mais le temps, et pas seulement les graphiques de référence, confirmera la solidité de cette promesse.
Conclusions
Pour ceux qui travaillent dans le monde de la technologie, le message est double. D'une part, les résultats des tests Gemini 3 indiquent que le niveau de capacité des modèles généralistes a franchi un nouveau seuil, créant des applications crédibles qui, jusqu'à récemment, étaient considérées comme une frontière, depuis les copilotes développeurs jusqu'aux systèmes de gestion des connaissances véritablement conversationnels.
D'autre part, il apparaît clairement que l'évaluation ne peut plus se limiter à des scores synthétiques sur des benchmarks statiques : il devient nécessaire de concevoir des suites de tests spécifiques à son domaine, mesurant la fiabilité, la sécurité et les coûts tout au long du cycle de vie des applications.
Dans ce contexte, et à la lumière des tests directs réalisés sur Gemini 3 dans des environnements et jeux de données réels, considérer le modèle simplement « réussi » ou « échoué » relève d'une simplification excessive.
Le modèle est clairement l’un des plus avancés disponibles aujourd’hui et pousse vers de nouvelles normes de raisonnement et de sécurité multimodaux, mais sa véritable efficacité dépendra de la capacité à l’intégrer dans des écosystèmes d’outils, de données et de processus soigneusement conçus. Les tests, plutôt qu'un jugement définitif, deviennent un dialogue continu entre ceux qui développent le modèle et ceux qui l'appliquent sur le terrain, avec le double objectif d'exploiter au maximum son potentiel et d'en contenir les risques.
Bibliographie
Analyses comparatives de modèles tels que GPT‑4.1, Gemini 2.5 Pro et successeurs sur des sites et blogs techniques mis à jour jusqu'en 2025 (articles de comparaison et de benchmark).
Google, article de blog officiel « Une nouvelle ère d'intelligence avec Gemini 3 »
Google, « Présentation de Nano Banana Pro (Gemini 3 Pro Image) » article de blog officiel
Blog des développeurs Google, article « Construire avec Nano Banana Pro, notre modèle Gemini 3 Pro Image » pour les développeurs
Blog des développeurs Google, article « Création d'agents IA avec Google Gemini 3 et les frameworks Open Source » pour les développeurs
Entrée « Gemini (modèle de langage) » sur Wikipédia, section mise à jour sur l'entrée encyclopédique Gemini 3
Article de fond du Wall Street Journal, « Comment Google a finalement dépassé ses rivaux avec le nouveau déploiement de Gemini »