

DeepSeek V4 open-weight : benchmark IA, conformité et utilisation locale
Le 24 avril 2026, DeepSeek a publié deux nouveaux modèles de version préliminaire sur Hugging Face, sous licence MIT : V4-Pro avec 1,6 billion de paramètres au total (49 milliards activés) et V4-Flash avec 284 milliards au total (13 milliards activés), tous deux avec une fenêtre contextuelle de 1 million de jetons.
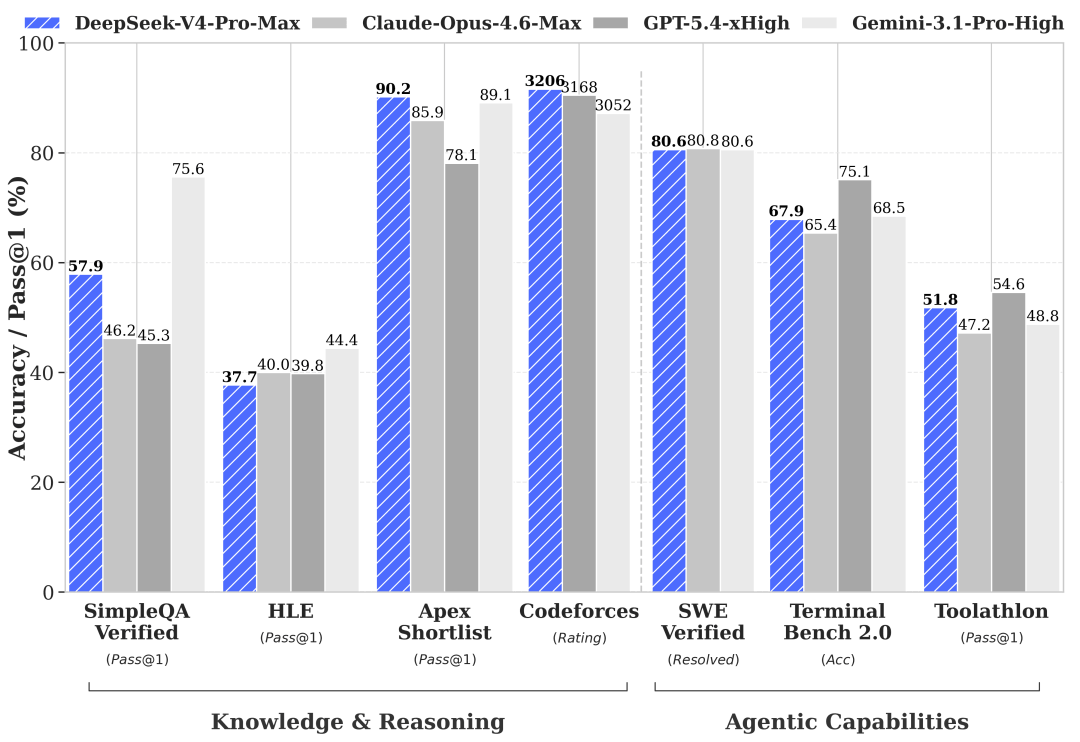
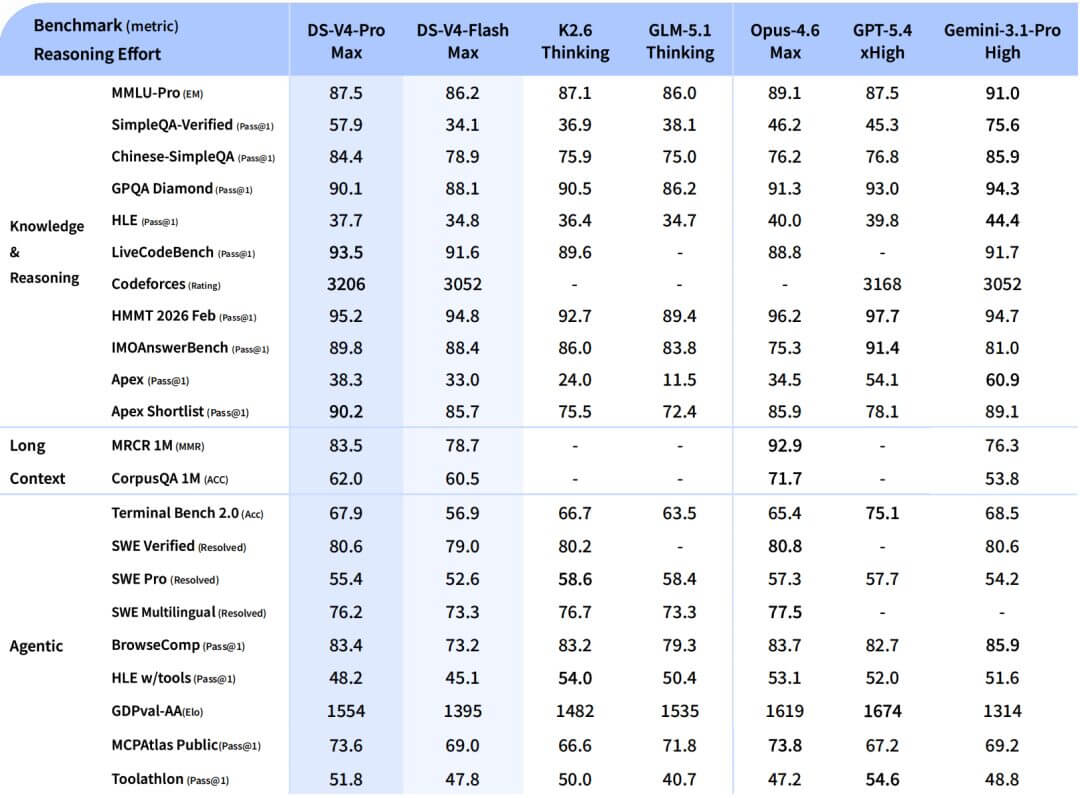
En termes de performances déclarées, le bilan est clair : V4-Pro en mode Max surpasse Claude Opus 4.6, GPT-5.4 et Gemini 3.1-Pro sur LiveCodeBench (93,5), sur Codeforces (note 3206) et sur Apex Shortlist (90,2), garde le contact sur SWE-Verified (80,6 contre 80,8 pour Opus) et reste derrière seulement Gemini 3.1-Pro en général connaissance.
En Italie, le système arrive alors que le Garant maintient toujours actif le blocage du service DeepSeek décidé en janvier 2025, et cette asymétrie, entre le modèle à poids ouvert et le service cloud interdit, est la question que ceux qui évaluent l’adoption doivent résoudre avant toute comparaison technique.

Au sommet en codage, en retard en connaissances
V4-Pro-Max atteint 87,5 sur MMLU-Pro, s’alignant exactement sur GPT-5.4 et restant en dessous de Gemini 3.1-Pro (91,0) et Claude Opus 4.6 (89,1).
Sur HLE, le benchmark le plus dur en matière de connaissance et de raisonnement, il s’arrête à 37,7 contre 40,0 pour Opus et 44,4 pour Gemini.
Sur IMOAnswerBench, il atteint 89,8, au-dessus d’Opus (75,3) et Gemini (81,0), en dessous de GPT-5,4 (91,4). Sur HMMT 2026, il fait 95,2, avec Opus (96,2) et GPT-5,4 (97,7) légèrement en avance.
La note sur le codage compétitif Forces de code de 3206 est le plus élevé des modèles frontières signalés, supérieur à GPT-5.4 (3168) et Gemini (3052).
La lecture honnête de ces données est double.
Côté codage, raisonnement mathématique et workflow agentique, V4-Pro se situe dans la gamme des meilleurs modèles au monde, souvent en avance.
Du côté des connaissances générales et des connaissances factuelles du monde, l’écart avec Gemini 3.1-Pro reste visible, notamment sur SimpleQA-Verified où Gemini obtient un score de 75,6 et V4-Pro s’arrête à 57,9.
DeepSeek lui-même décrit sa trajectoire dans sa fiche modèle comme étant en retard de trois à six mois par rapport à la frontière des sources fermées, une estimation réaliste qui aide à calibrer les attentes.
V4-Pro : 27 % de FLOP, 10 % de cache KV
La partie la plus techniquement intéressante de la version est la manière dont DeepSeek atteint ces performances dans un contexte d’un million de jetons.
L’architecture d’attention hybride combine Attention clairsemée compressée (CSA) Et Attention fortement comprimée (HCA): le premier compresse le cache KV selon la taille de la séquence et applique une sélection clairsemée (top-k 1024 dans V4-Pro, top-k 512 dans V4-Flash), le second utilise un facteur de compression de 128 avec une attention particulière pour assurer une couverture globale à faible coût. Les deux mécanismes sont imbriqués dans la pile.
La V4-Pro nécessite 27 % de FLOP par jeton et 10 % de cache KV par rapport à la V3.2 sur un contexte de 1 million de jetons.
Le résultat mesuré est que la V4-Pro sur contexte 1M nécessite 27 % de FLOP par token par rapport à la V3.2 et 10 % du cache KV. Traduit : même modèle, dix fois moins de mémoire occupée par le cache lors de l’inférence, soit un quart du calcul. C’est le levier économique qui permet de tarifier l’API à 0,28 dollars par million de tokens en entrée, soit environ cinquante fois moins que Claude Opus 4.6.
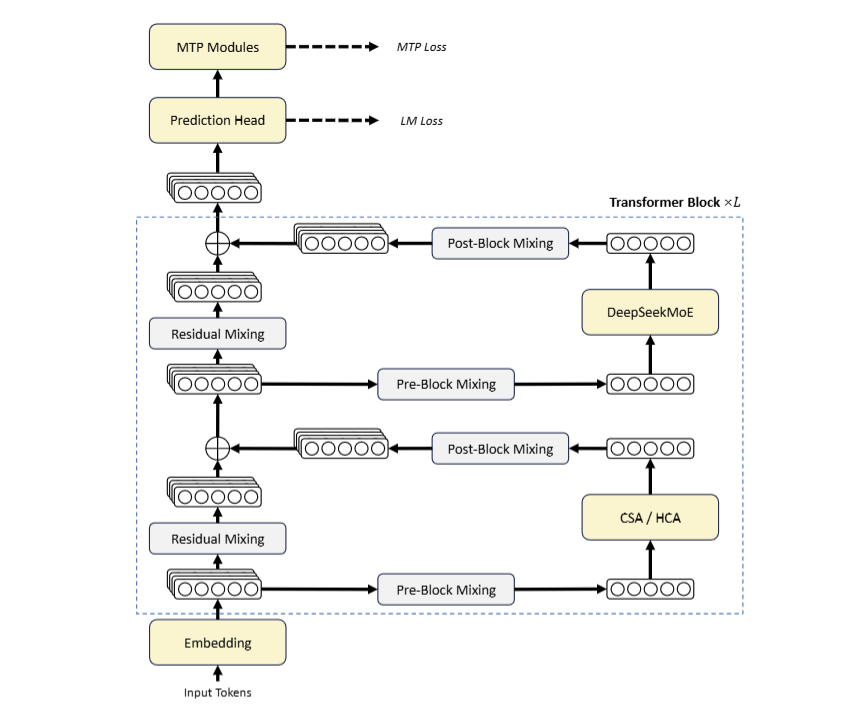
A côté de l’attention, il y a deux ingrédients complémentaires : le Hyper-connexions à contraintes multiples (mHC) pour stabiliser la propagation du signal dans les couches profondes, et l’optimiseur Muon pour une convergence plus rapide lors de l’entraînement. L’ensemble, pré-entraîné sur 32 000 milliards de jetons, est le résultat d’un choix industriel clair : produire de l’intelligence à un coût durable au lieu de rechercher une simple mise à l’échelle.
Le garant de la confidentialité n’a pas débloqué DeepSeek
Le 30 janvier 2025, le Garant de la confidentialité a imposé une limitation définitive et urgente au traitement des données personnelles des utilisateurs italiens par Intelligence artificielle DeepSeek de Hangzhou Et Intelligence artificielle DeepSeek de Pékin.
Le litige n’est pas technique, il est de principe : la politique de confidentialité indiquait un stockage des données en Chine sans les garanties prévues par l’article 32 du RGPD, il manquait une base juridique documentée pour le traitement, aucun représentant de l’UE n’avait été désigné conformément à l’article 27 et l’entreprise avait répondu à la demande de clarification en affirmant qu’elle n’était pas soumise au RGPD parce qu’elle n’opérait pas en Italie.
Le Garant a jugé la réponse insuffisante et a bloqué définitivement le service, une position renforcée en février 2026 par une analyse de l’IAPP qui met en évidence comment la Chine ne dispose pas de décision d’adéquation européenne et comment le cadre réglementaire chinois soulève des questions spécifiques sur la sécurité du traitement.
Le point qui change tout, c’est l’architecture de la distribution DeepSeek. Les poids des modèles sont publiés sous la licence MIT sur Hugging Face, la même licence qui régit les logiciels entièrement gratuits à usage commercial. Quiconque télécharge V4-Pro ou V4-Flash et les exécute sur sa propre infrastructure n’utilise pas le service que le Garant a bloqué : il utilise un modèle mathématique qui, une fois chargé en mémoire, ne communique pas avec les serveurs DeepSeek, ne transmet pas d’invites, n’envoie pas de télémétrie. Le blocage réglementaire affecte le service chat.deepseek.com et l’application mobile, et non les poids neuronaux eux-mêmes.
Cette distinction a de lourdes conséquences pratiques pour ceux qui évaluent son adoption : l’option cloud DeepSeek est exclue dans le contexte italien, l’option d’auto-hébergement reste techniquement ouverte, toutes les contraintes du RGPD restant du ressort du responsable du traitement.
Quand l’air gap en vaut vraiment la peine
L’idée d’exécuter V4-Pro sur le matériel de l’entreprise doit être envisagée sans marketing. La version FP8 Mixed du modèle de base occupe environ 862 milliards de paramètres au format tensoriel, la version instruct utilise FP4 pour les paramètres experts MoE et FP8 pour le reste.
Pour l’inférence de production sur V4-Pro, vous avez besoin de clusters multi-GPU avec parallélisme tensoriel Et parallélisme des pipelinesl’ordre de grandeur est celui des centres de données d’entreprise dotés de huit à seize H100 (Nvidia) ou mieux.
Le V4-Flash, avec 284 milliards au total, est plus gérable, mais reste hors de portée d’un seul poste de travail. Les versions distillées de la famille R1 déjà disponibles, de 1,5 à 70 milliards de paramètres, fonctionnent sur un matériel beaucoup plus accessible : un RTX 4090 avec 24 Go de VRAM gère facilement la variante quantifiée 32B, un ordinateur portable avec 8 Go de VRAM exécute le 7-8B via Ollama en quelques minutes seulement de configuration.
Pour les mondes de la finance, de la santé, de l’administration publique et du droit, le scénario concrètement intéressant est déploiement en espace vide: modèle distribué sur l’infrastructure interne, pas de connexions externes, des invites et des sorties qui ne quittent jamais le périmètre du réseau. Cela résout le problème de la surveillance étrangère et résout également le problème de la souveraineté des données, deux dimensions qu’aucun fournisseur de cloud, européen, américain ou chinois, ne peut garantir au même niveau.
Le coût, bien sûr, est élevé : matériel, compétences en ML-ops, maintenance, mises à jour du modèle lorsqu’une nouvelle version sort. Ceux qui le soutiennent le font parce que les données valent plus que les économies.
Le service cloud chinois interdit
Le V4 arrive sur un marché où l’écart entre les modèles chinois à poids ouvert et les frontières occidentales à source fermée est désormais de plusieurs mois, et non de plusieurs générations.
En mars, le Premier ministre chinois Li Qiang a déclaré publiquement que les grands modèles chinois d’IA menaient le développement de l’écosystème open source mondial, une déclaration confirmée par les chiffres : 63 % des nouveaux modèles peaufinés sur Hugging Face partent de bases chinoises.
En arrière-plan reste l’accusation, soulevée par Anthropic en février 2026, selon laquelle DeepSeek aurait utilisé des milliers de comptes frauduleux pour générer des millions de conversations avec Claude et les utiliser comme données d’entraînement, une accusation que DeepSeek n’a ni confirmée ni démentie en détail.
La même semaine que le lancement, le Bureau des sciences et technologies de la Maison Blanche a évoqué des campagnes de distillation industrielle visant à voler la technologie américaine d’IA, faisant principalement référence à des entités chinoises.
Le choix de ce qu’une entreprise doit en faire ne dépend pas du meilleur benchmark. Cela dépend du risque de conformité, de souveraineté et de réputation que vous êtes prêt à accepter, ainsi que de l’architecture de déploiement qui permet de gérer ce risque.
Les pondérations V4 sont un artefact technique précieux, distinct du service que le Garant a bloqué, utilisable avec prudence et avec une gouvernance sérieuse.
Mais la question que soulève cette sortie est moins technologique et plus politique : si le meilleur modèle open-weight au monde vient de Chine, et si le service cloud qui l’expose au marché n’est pas conforme à notre cadre réglementaire, qu’est-ce qui empêche l’Europe de construire sa propre alternative avec des pondérations ouvertes, une infrastructure continentale et des garanties de conformité dès la conception ?
Sans aucun doute, à la lecture de ces chiffres, on se demande pourquoi la réponse européenne n’est pas encore arrivée.