

De l'assistant à l'infrastructure : ce qui change vraiment avec GPT-5.4
Avec GPT-5.4, le débat sur les modèles généralistes franchit une étape importante. Il ne s’agit pas seulement d’une augmentation des performances par rapport à la génération précédente, mais d’une redéfinition précise du positionnement du produit. L’objectif affiché n’est plus seulement de mieux réagir ou de mieux planifier, mais de devenir une infrastructure fiable pour un travail professionnel à forte intensité cognitive.
La nouveauté centrale est précisément cette convergence. Le raisonnement, le codage, l'utilisation d'outils, l'interaction avec des environnements logiciels et la production de livrables tels que des feuilles de calcul, des présentations et des documents sont ramenés à un modèle frontière unique, distribué dans ChatGPT, API et Codex.
Dans le lexique OpenAI, GPT-5.4 est né comme le modèle le plus performant et le plus efficace pour le travail des connaissances. Le choix du nom signale également une stratégie de simplification. Au lieu de maintenir une séparation claire entre le modèle de raisonnement et le modèle de codage, l'entreprise intègre les capacités de GPT-5.3-Codex au cœur du nouveau système et les combine avec un profil plus fort dans l'utilisation d'outils et de flux de travail d'agent. En termes industriels, cela signifie réduire le nombre d’étapes nécessaires pour réaliser une tâche complexe et, surtout, réduire les frictions entre l’analyse, l’exécution et la vérification.
Un bond mesurable dans les tâches à forte valeur ajoutée
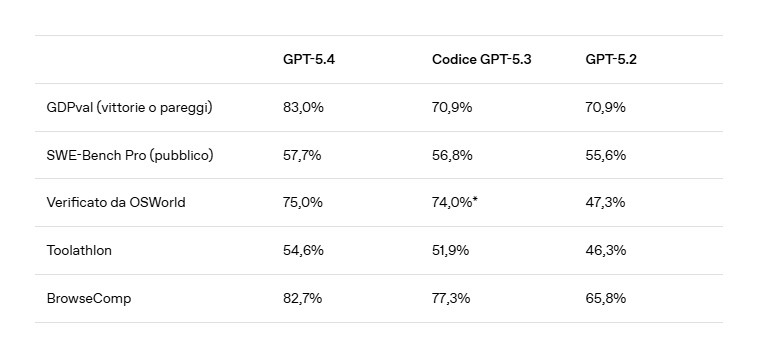
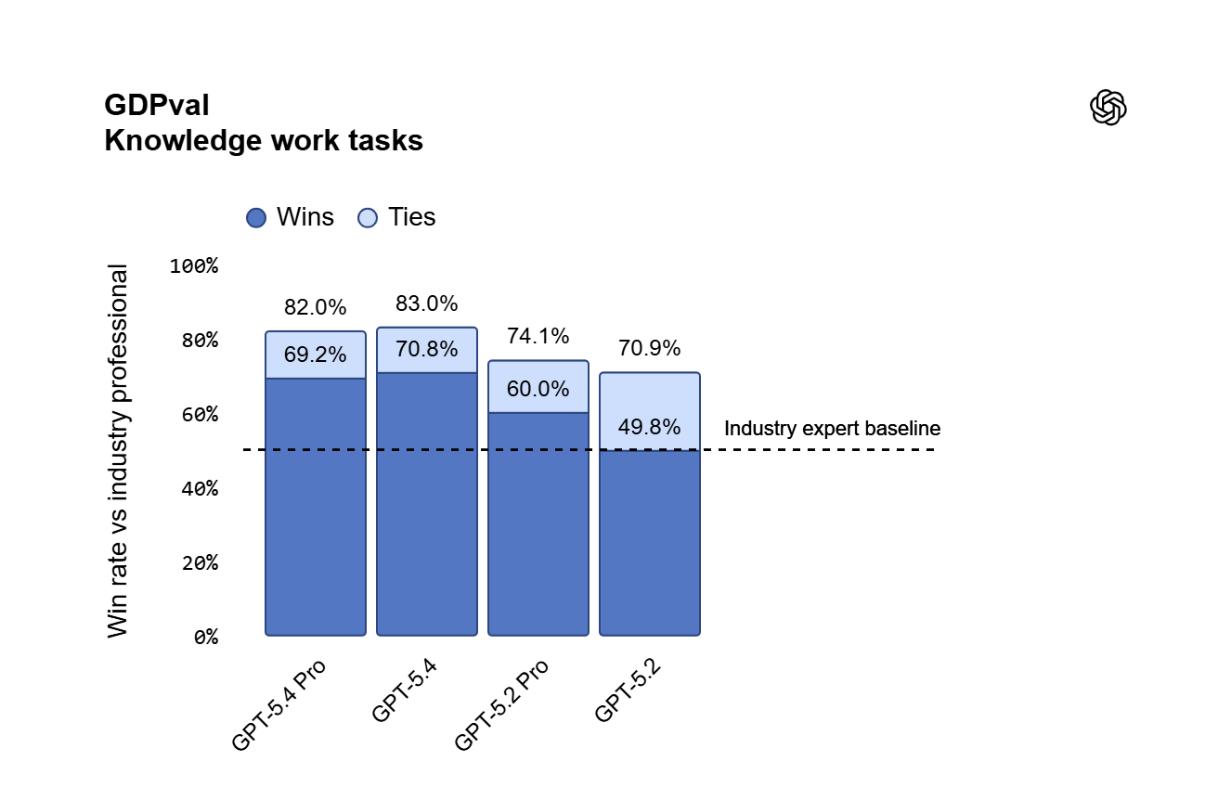
Le récit de lancement est soutenu par une batterie de références qui visent non seulement l’excellence académique, mais aussi la simulation de contextes de travail concrets. La donnée la plus citée est GDPval, un indice de référence dédié au travail de connaissances bien spécifié dans 44 professions réparties dans les principaux secteurs de l'économie américaine. Ici, GPT-5.4 atteint un taux de victoire ou de match nul de 83,0 % contre les professionnels du secteur, contre 70,9 % pour GPT-5.2. Il s’agit d’un bond qui doit être interprété avec prudence, comme c’est toujours le cas avec les valorisations exclusives, mais qui indique une direction claire. Le modèle est jugé non seulement sur son exactitude ponctuelle, mais également sur la qualité du produit final requis.
La même approche se dégage dans les tâches internes dédiées aux tableurs, documents et présentations. Dans les activités de modélisation de feuilles de calcul associé au travail d'un analyste junior en banque d'investissement, GPT-5.4 obtient un score moyen de 87,3 %, contre 68,4 % pour GPT-5.2. Même au niveau visuel, le positionnement est explicite. Lors de l'évaluation des présentations, les juges humains ont préféré les sorties GPT-5.4 dans 68 % des cas, récompensant la variété graphique, le rendu esthétique et une utilisation plus efficace de la génération d'images.
Cet élément est pertinent car il signale une transition de l’IA générative d’un outil majoritairement textuel à une plateforme de production d’artefacts professionnels complets.
D’assistant à collègue exploitant de logiciels
La caractéristique la plus intéressante du lancement est probablement l’introduction native de l’utilisation de l’ordinateur dans un modèle à usage général.
OpenAI présente GPT-5.4 comme le premier modèle majeur capable de fonctionner directement sur des interfaces logicielles, d'interpréter des captures d'écran, de renvoyer les actions de la souris et du clavier et de travailler en tandem avec des bibliothèques telles que Dramaturge. Ce passage change le centre de gravité de la notion d'agent. Il ne s’agit plus seulement d’appeler des API ou de concaténer des outils textuels, mais d’exécuter des tâches réelles dans des environnements de bureau et Web avec un plus grand degré d’autonomie.
Les benchmarks montrent des progrès évidents. Sur OSWorld-Verified, un test dédié à la navigation dans les environnements de bureau via des captures d'écran et des saisies au clavier ou à la souris, GPT-5.4 atteint 75,0 pour cent de réussite, au-dessus des 47,3 pour cent de GPT-5.2 et légèrement au-dessus de la référence humaine rapportée par le même benchmark, égale à 72,4 pour cent (voir GPT-5.4 : la nouvelle génération d'IA pour le travail professionnel – AI4Business).
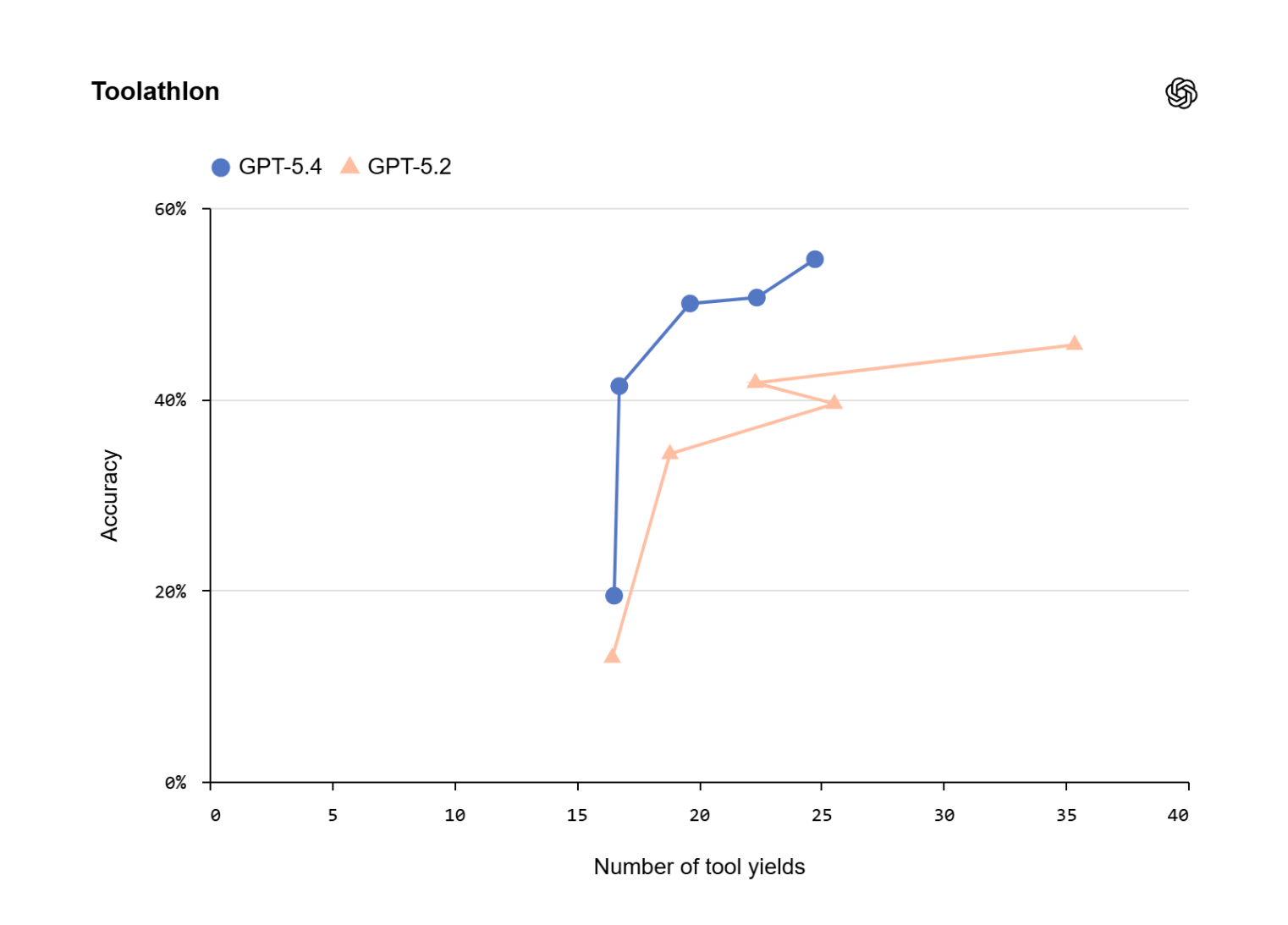
Les performances augmentent également dans la navigation du navigateur, à la fois sur WebArena-Verified et Online-Mind2Web. Mais la donnée intéressante ne se limite pas au pourcentage final. OpenAI accorde une grande importance au concept de rendement de l'outilc'est-à-dire sur le nombre de suspensions nécessaires pour attendre les instruments. Il s'agit d'un indicateur moins spectaculaire mais plus proche de la productivité réelle, car il capture la latence réelle des workflows multi-étapes et la capacité du modèle à paralléliser ou compresser les opérations.
L’amélioration de la vision est également liée à cette dimension opérationnelle. GPT-5.4 atteint 81,2 % sur MMMU-Pro sans outils et améliore les capacités d'analyse de documents sur OmniDocBench, où l'erreur normalisée moyenne passe de 0,140 à 0,109.
Pour les cas où la fidélité de l'image est cruciale, OpenAI introduit également une couche d'entrée visuelle originale, qui prend en charge jusqu'à 10,24 millions de pixels au total ou 6 000 pixels sur le côté maximum. En pratique, le modèle est poussé dans des scénarios où il doit lire des interfaces denses, des documents techniques, des écrans complexes et des images haute résolution sans perdre en précision de localisation.
Codage, contexte long et recherche d'outils
Du côté du développement logiciel, GPT-5.4 hérite des capacités de GPT-5.3-Codex et les amène dans un profil plus large. Sur le SWE-Bench Pro public, il obtient un score de 57,7 %, essentiellement conforme mais légèrement supérieur à GPT-5.3-Codex. Cependant, OpenAI met surtout en avant la combinaison de précision et de latence plus faible, ainsi que la disponibilité d'un mode rapide dans Codex qui augmente la vitesse des tokens jusqu'à 1,5 fois. En d’autres termes, la valeur ne réside pas seulement dans la capacité à résoudre des tests de codage, mais dans la capacité à rester dans un cycle continu de construction, de test, de correction et de vérification avec moins d’intervention humaine.
La fenêtre contextuelle de 1,05 million de jetons, disponible pour GPT-5.4 et GPT-5.4 Pro, entre également en jeu ici. Une fenêtre de cette taille ouvre des scénarios intéressants pour de grandes bases de code, de grandes collections de documents et des trajectoires d'agence très longues, mais elle introduit également une question économique. En effet, la documentation de l'API précise que les requêtes supérieures à 272 000 tokens ont un prix plus élevé, avec un doublement du coût d'entrée et une augmentation du coût de sortie sur l'ensemble de la session.
Il s’agit d’un détail commercial qui est tout sauf marginal, car il signale que la capacité en contexte extrême est réelle mais n’est pas conçue pour être utilisée sans discernement.
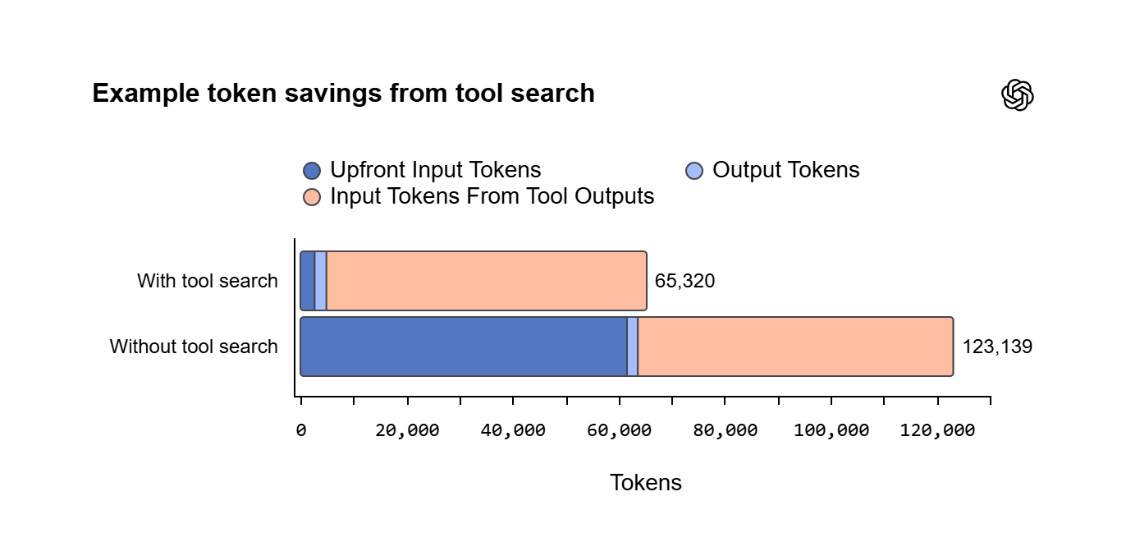
La fonction de recherche d'outils est également très importante. Au lieu de charger toutes les définitions des outils disponibles dans une invite, le modèle reçoit une liste concise et ne peut récupérer celles qui sont pertinentes que lorsqu'elles sont vraiment nécessaires. Sur 250 tâches du benchmark MCP Atlas, cette architecture réduit la consommation totale de jetons de 47 % tout en conservant la même précision.
D’un point de vue technique, il s’agit d’une démarche importante. Cela signifie que l’expansion des écosystèmes d’outils n’entraîne plus automatiquement des invites géantes, des coûts plus élevés et un gaspillage de contexte.
Un modèle plus cher, mais avec une logique économique différente
La liste de prix de l'API confirme que GPT-5.4 est plus cher que GPT-5.2. Dans la tarification standard inférieure à 272 000 jetons, le prix est de 2,50 dollars par million de jetons d'entrée, 0,25 par million de jetons d'entrée et 15 dollars par million de jetons de sortie. GPT-5.4 Pro monte plutôt jusqu'à 30 dollars en entrée et 180 en sortie. OpenAI défend ce positionnement en arguant que la plus grande efficacité du modèle réduit le nombre global de tokens nécessaires pour accomplir de nombreuses tâches.
C’est une thèse plausible, notamment dans les flux multi-étapes où la qualité de la première exécution et le choix des outils ont un impact plus important que le coût unitaire pur du token.
La disponibilité a également été calibrée afin de couvrir les groupes professionnels. Dans ChatGPT, GPT-5.4 Thinking remplace GPT-5.2 Thinking pour les utilisateurs Plus, Team et Pro, tandis que GPT-5.4 Pro est réservé aux forfaits Pro et Enterprise. Pour les organisations, le signal stratégique est clair. OpenAI considère désormais les modèles de raisonnement haut de gamme non seulement comme des moteurs conversationnels, mais aussi comme des composants de productivité avancés à intégrer dans les flux de travail commerciaux, documentaires et de développement.
Le vrai sens du lancer
Le point le plus important n’est pas de savoir si GPT-5.4 est la meilleure référence en matière de benchmarks, mais de reconnaître le changement de paradigme qu’il représente. OpenAI tente de transformer le modèle frontière en un système opérationnel capable de planifier, d'utiliser des outils, de naviguer dans les interfaces, de produire des résultats complexes et de maintenir une cohérence sur des horizons plus longs.
En ce sens, GPT-5.4 n’est pas seulement un modèle plus puissant. Il s'agit d'une tentative de consolider dans une architecture unique les fonctions qui jusqu'à présent étaient réparties entre les chatbots, les copilotes de codage, les automatismes documentaires et les agents expérimentaux.
Naturellement, la question de la vérifiabilité indépendante demeure. De nombreux chiffres de lancement proviennent de benchmarks internes ou de tests présentés par l'entreprise elle-même, et il faudra observer le comportement du modèle en production pour comprendre dans quelle mesure ces avantages se traduisent en fiabilité au quotidien. Toutefois, la direction est claire. Le terrain de compétition n’est plus seulement la qualité de la réponse, mais la capacité à réaliser un travail utile, avec moins d’erreurs, moins d’étapes et une plus grande intégration avec des outils réels.
Si cette orientation se maintient dans le monde réel, GPT-5.4 restera peut-être dans les mémoires non pas comme une énième amélioration des performances, mais comme le moment où l’IA généraliste a commencé à être explicitement conçue comme une infrastructure professionnelle.
Bibliographie
API OpenAI, « Images et vision »
OpenAI, « Présentation de GPT-5.4 »
OpenAI, « Carte système de réflexion GPT-5.4 »
API OpenAI, « Guide du modèle GPT-5.4 »
API OpenAI, « Utilisation de GPT-5.4 »
API OpenAI, « Utilisation de l'ordinateur »
API OpenAI, « Tarification »