

Claude Code : la compétence compte plus que le code
Pour guider un agent de codage vers un bon résultat, la maîtrise du problème est plus importante que la capacité à écrire du code. C’est ce que montre l’analyse publiée par Anthropic sur le travail réel avec Claude Code, environ 400 mille sessions interactives lues une à une par un système qui préserve la vie privée, collectées entre octobre 2025 et avril 2026 par environ 235 mille personnes. Le travail étend les recherches antérieures sur les mesures de l’autonomie des sessions et sur la manière dont Claude Code modifie déjà le travail au sein d’Anthropic.
Au cours de ces sessions, nous observons une division précise du travail, les gens décident quoi construire et l’agent décide comment, et un résultat qui remplace une attente largement répandue : dans les tâches qui produisent du code, tous les grands groupes professionnels réussissent presque aussi bien que les ingénieurs logiciels. Le code comme barrière à l’entrée pèse moins qu’avant. Ce qui compte, et beaucoup, c’est à quel point ceux qui sont assis devant le clavier connaissent réellement le problème qu’ils tentent de résoudre.
Pour ceux de l’entreprise qui évaluent où et à qui confier les agents de codage, la lecture la plus utile concerne la façon dont la collaboration est répartie session après session et qui en ressort avec un travail qui dure.
Soixante-dix contre vingt : qui décide dans les séances
Anthropic a construit un classificateur qui attribue chaque décision d’une session à celui qui l’a prise, séparant la planification, ce qu’il faut faire et quel chemin emprunter, de l’exécution, quels fichiers toucher et quelle commande lancer. Le tableau est stable : en moyenne, les gens gardent environ 70 % des décisions de planification pour eux-mêmes et laissent environ 80 % des décisions d’exécution à Claude. La destination est décidée, le chemin est confié.
Les évaluations de capacités indiquent un plafond élevé et croissant, avec des modèles capables d’accomplir de manière autonome des tâches logicielles qui prendraient des heures à une personne. Cependant, l’utilisation réelle raconte une histoire de conduite partagée. Une session typique s’étend sur environ quatre échanges, et pour chaque invite envoyée par la personne, dans les données d’octobre à avril, Claude répond par une chaîne d’une dizaine d’actions en moyenne, parfois plus d’une centaine, lisant des fichiers, éditant du code, émettant des commandes et produisant environ 2 400 mots de sortie par tour.
Ce que fait Claude d’un contrôle à l’autre suit de près celui qui est aux commandes : là où la personne retient l’exécution, sur 80 % des choix opérationnels, l’agent se déplace avec prudence, autour de huit actions par équipe, tandis que là où Claude dirige la planification la chaîne s’étend jusqu’à seize.
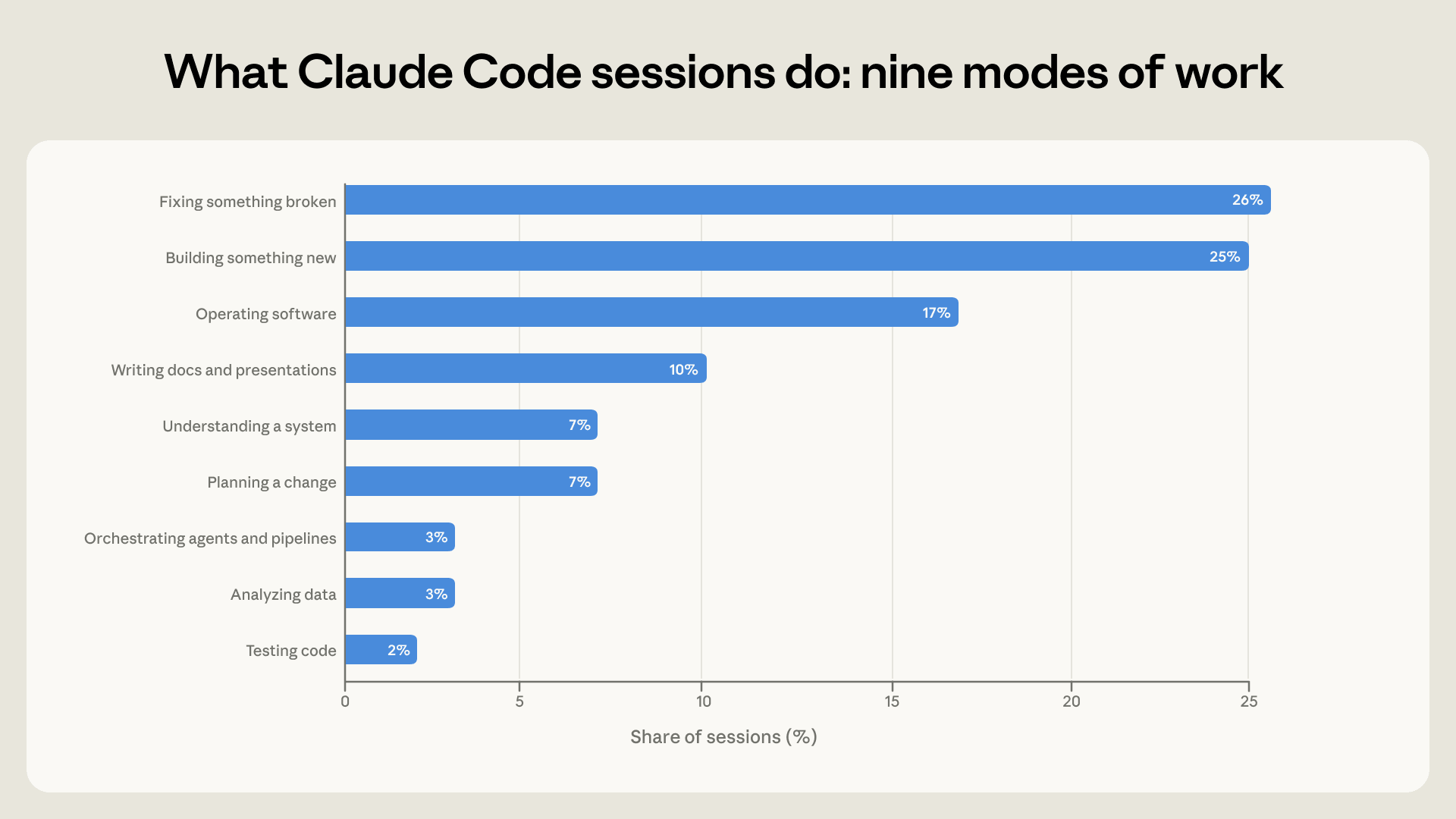
En termes de contenu, les sessions sont réparties selon neuf manières de travailler. L’écriture de nouveau code et la réparation de codes défectueux représentent ensemble la moitié du total, 25 % et 26 %, tandis que faire fonctionner le logiciel, de la configuration à la surveillance, représente 17 % supplémentaires, et une part croissante est utilisée pour comprendre un système, planifier un changement, analyser des données ou produire du texte.
L’expert comptable et l’ingénieur novice
À partir de chaque relevé de notes, un classificateur estime la compétence de la personne pour la tâche, sur une échelle de un à cinq, de débutant à expert, et ce d’une manière liée à la tâche individuelle. Un ingénieur chevronné qui pose sa première question sur Rust est, là, un débutant. Un comptable qui n’a jamais écrit une seule ligne de Python, mais qui sait exactement quelles règles de rapprochement le script doit respecter et qui saisit le cas limite qui saute à la clôture de fin de mois, est un expert dans ce domaine. Les exemples utilisés pour calibrer le classificateur proviennent d’un ensemble de données publiques de sessions de codage.
Le classificateur examine trois signaux :
- la précision de la personne dans la formulation des demandes,
- qu’est-ce qu’il te demande de vérifier,
- qu’elle corrige Claude ou que Claude la corrige.
L’importance de cette expertise se voit dans la réactivité de l’agent. Dans les sessions pour débutants, chaque invite déclenche environ cinq actions et six cents mots, dans celles des experts, la chaîne double, douze actions, et le résultat est multiplié par cinq, soit plus de trois mille mots. L’écart demeure au sein de chaque type d’emploi et de chaque gamme de valeurs, et tient également, en contrôlant pour l’emploi, la valeur de la tâche, le mois et le modèle utilisé, environ 9 % d’actions et 13 % de rendement en plus pour chaque niveau de compétence.
Quand la séance se passe mal
Ici, mesurer le succès requiert de la prudence, car les résultats réels ne sont pas observés et personne ne demande à la personne si elle a obtenu ce qu’elle voulait. Anthropic combine deux lectures de la transcription, un jugement quant à savoir si la personne a atteint son objectif, et une vérification des preuves à l’appui, des commits et pull request cohérents avec le travail, des tests réussis, des confirmations explicites de l’auteur. Le succès ne se produit que lorsque les deux éléments sont valables, un jugement positif et au moins un signal concret.
Pour toutes ces mesures, le signal est le même : plus la personne fait preuve de compétence lors de la séance, plus il y a de chances que la séance soit réussie. Une séance débutant atteint le seuil le plus sévère, celui de réussite vérifiée, dans 15 % des cas, et atteint une réussite au moins partielle dans 77 %. Une séance de niveau intermédiaire et supérieur obtient une réussite vérifiée entre 28 et 33 % du temps, et une réussite partielle dans plus de 90 %. La quasi-totalité du gain est concentrée dans le saut du débutant à intermédiaire, tandis qu’entre intermédiaire et expert la montée devient plus plate.
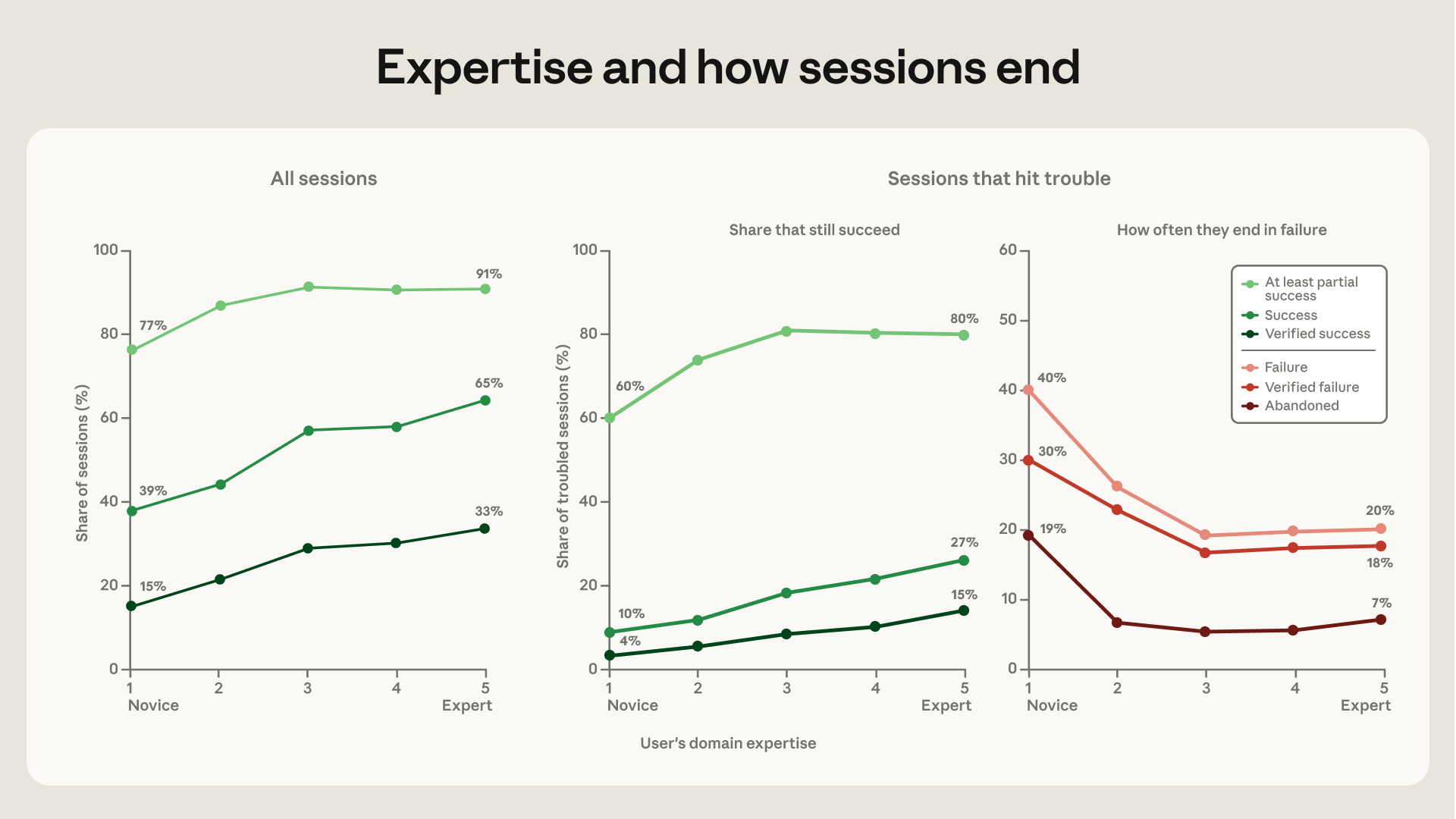
Le tableau devient plus clair dans les séances qui rencontrent des obstacles, une erreur, un test raté, des tentatives multiples sur le même point, une personne qui se dit insatisfaite. Parmi ceux-ci, la part des réussites vérifiées passe de 4% des débutants à 15% des experts, et celle des réussites au moins partielles de 60% à environ 80%.
Ensuite, il y a le signal qui en dit plus sur la valeur de la compétence : lorsqu’une session difficile finit par être abandonnée, avec zéro ligne de code, cela arrive dans 19 % des cas si le conducteur est débutant, contre 5 à 7 % de tous les autres. Les moins expérimentés abandonnent en premier. Face au même obstacle, l’expertise ajoute en partie la capacité de remettre l’agent sur la bonne voie.
Chaque métier reste à sept points des ingénieurs
Pour comprendre qui fait ce travail, Anthropic déduit le travail de la transcription, du contexte du projet, des noms des fichiers, des artefacts cités, qu’il s’agisse d’un document juridique ou d’un ensemble de données cliniques, du vocabulaire, et cartographie la séance sur l’une des vingt-trois grandes catégories professionnelles de la classification américaine, avec une règle explicite : écrire du code ne suffit pas à faire de quelqu’un un professionnel du logiciel. Un avocat qui construit un script pour signaler des clauses manquantes dans un dossier contractuel se retrouve dans la profession juridique, même si la session est entièrement un travail logiciel.
L’échange a pu être déduit dans environ 70 % des séances. Le groupe le plus important est celui de l’informatique et des mathématiques, suivi par les affaires et la finance, les arts et les médias, la gestion, les sciences de la vie et les sciences sociales, tandis que les groupes hors logiciels qui connaissent la croissance la plus rapide sont la gestion, la vente et les professions juridiques. En termes de réussite, l’écart entre ceux qui créent des logiciels pour gagner leur vie et les autres est faible : les professions informatiques obtiennent un succès vérifié dans environ 30 % des sessions, les autres dans 26 %, et seulement dans les sessions qui produisent du code, la comparaison est de 34 % contre 29 %. Parmi les dix groupes les plus représentés, chacun reste à sept points de pourcentage des ingénieurs logiciels, et cet écart ne s’est ni élargi ni réduit en sept mois, alors que les taux ont augmenté pour tous.
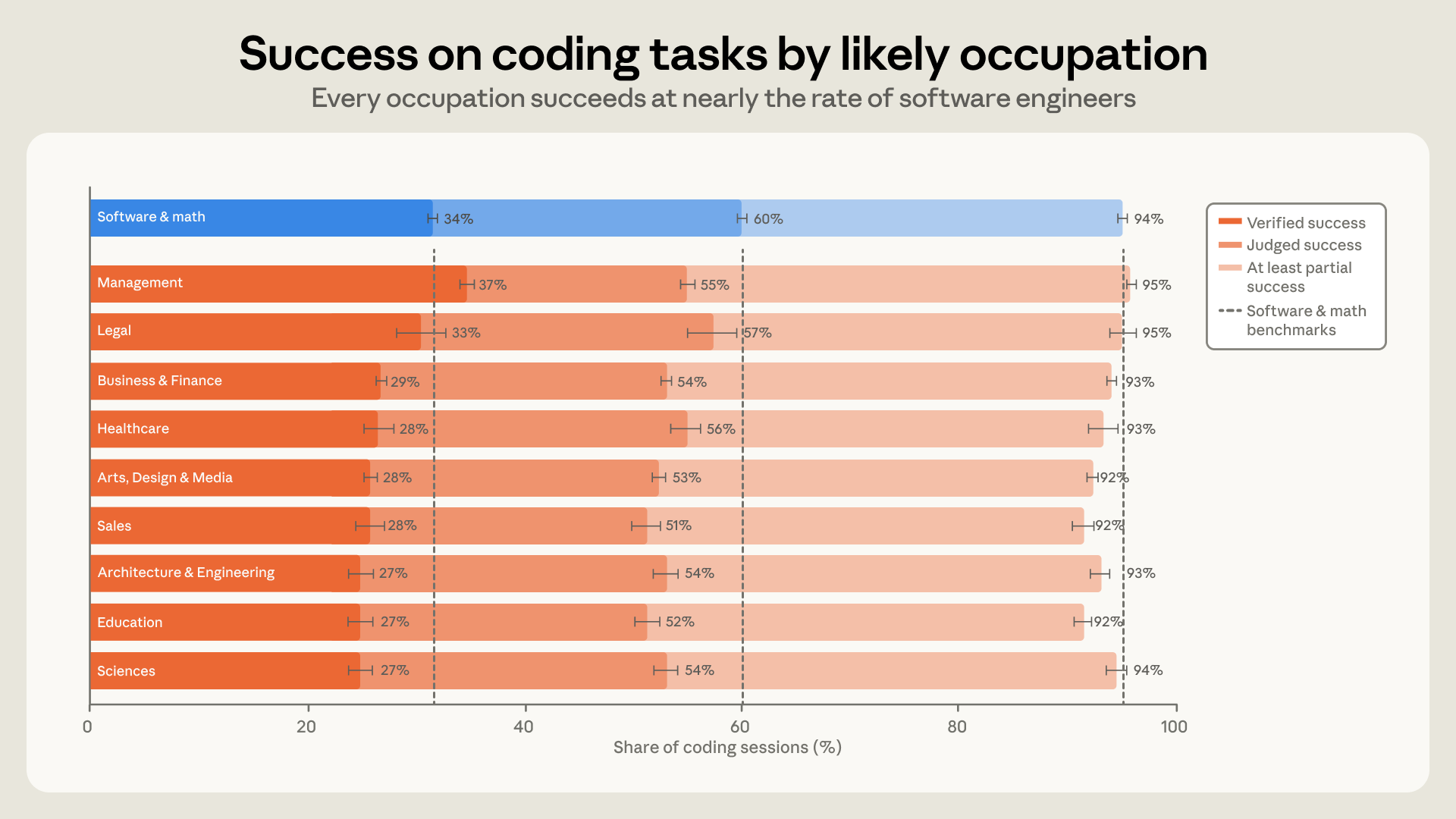
Il y a un détail qui mérite une note méthodologique : en termes de succès vérifiés, le management apparaît légèrement au-dessus des ingénieurs logiciels. Il se peut que gérer un agent ressemble à des compétences managériales qui se transmettent bien, mais cela peut aussi dépendre de la façon dont le succès est mesuré, car la vérification repose en partie sur une confirmation explicite dans le relevé de notes, et un manager a tendance à communiquer plus souvent lorsqu’il a obtenu ce qu’il a demandé.
Du débogage à l’achèvement du travail en sept mois
La façon dont nous travaillons avec Claude Code a pas mal changé au cours des sept mois observés. Le changement le plus net concerne la réparation du code cassé, qui est passé de 33 % à 19 % des sessions, tandis que tout le travail autour du code a augmenté : le fonctionnement du logiciel est passé de 14 % à 21 %, et l’écriture et l’analyse des données ont presque doublé, d’environ 10 % à 20 %.
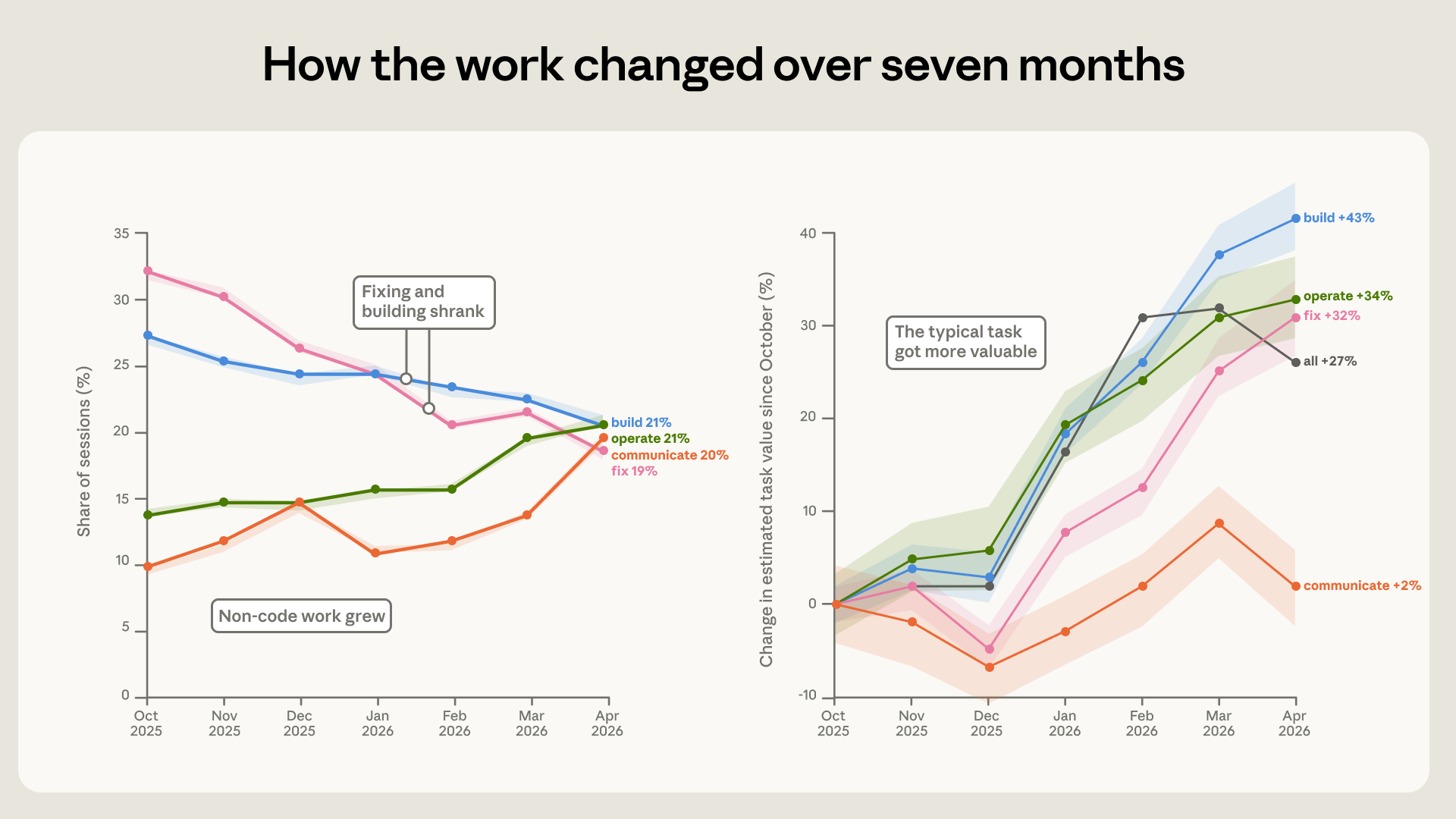
La valeur des devoirs a également augmenté. Anthropic estime cela en demandant combien coûterait ce travail sur un marché indépendant, calibré sur un ensemble réel d’annonces, et selon cette mesure, la valeur de la session moyenne a augmenté de 27 % sur la période. La croissance se maintient dans de nombreux types de travaux, la construction, l’exploitation et la correction représentant respectivement environ un tiers de plus, 43%, 34% et 32%, tandis que la communication reste pratiquement inchangée. Il s’agit d’estimations approximatives, utiles pour comparer les tâches entre elles dans le temps plutôt que pour lire une valeur en euros.
Quatre cent mille séances qu’aucun chercheur n’a lu
Il vaut la peine de combiner la force du nombre et ses limites, car l’étude est explicite sur les deux. L’analyse préserve la confidentialité par construction, aucun chercheur ne lit les transcriptions individuelles, les étiquettes n’ont aucun rapport avec qui est identifiable et elles ne sont observées que de manière agrégée sur un nombre minimum d’utilisateurs. Ce sont des résultats préliminaires, on ne sait pas si le code produit dans une session finit en production ou à la poubelle, toute la partie d’usage non interactive, qui est cohérente, est laissée de côté, et chaque classement dépend encore de la lecture qu’un modèle fait de la transcription.
La valeur de ces mesures est de pouvoir les suivre à mesure que les modèles, les personnes et la division du travail entre eux évoluent. Si les retours sur l’expertise commençaient à décliner, ce serait le signe que les modèles commencent à fournir le jugement que porte aujourd’hui la personne et que les avantages s’étendent au-delà des experts du domaine. Toutefois, si la part des sessions réussies chez ceux qui ne créent pas de logiciels continue à croître, cela signifierait que la production de logiciels deviendrait une partie du travail ordinaire dans tous les domaines, et non plus le produit d’une seule profession.
Dans «Digital Skin», je décris la technologie comme une couche qui nous adhère et change ce que nous sommes capables de faire, et nous en lisons ici une confirmation concrète, l’outil amplifie ceux qui apportent de la compréhension et laisse derrière lui ceux qui délèguent simplement. Pour une entreprise, la question n’est plus de savoir combien de développeurs elle a besoin, mais plutôt de savoir qui, dans chaque fonction, connaît suffisamment ses problèmes pour guider un agent jusqu’au bout.
Sans aucun doute, l’expertise métier est aujourd’hui le levier le plus sous-estimé de cette transition, et il convient donc de se demander : qui, dans notre organisation, a déjà la main sur ces outils, et dans quelle mesure connaît-il réellement le travail qu’on lui demande de faire ?