

Alibaba vient de démontrer qu'Openai dépense 78 millions pour faire de même qu'ils pour 500 000 $
Il existe une nouvelle technique d'étoile pour former des modèles d'IA super efficacement. C'est au moins ce que Alibaba semble avoir démontré, qu'il a présenté vendredi sa famille de modèles Qwen3-Next et l'a fait en supposant une efficacité spectaculaire qui laisse même derrière celle qui a atteint le R1 profonde.
Ce qui s'est passé. Alibaba Cloud, la division des infrastructures de cloud Alibaba Group, a présenté une nouvelle génération de LLM qui décrivaient «l'avenir des LLM efficaces». Selon les responsables, ces nouveaux modèles sont 13 fois plus petits que le plus grand modèle que cette entreprise ait lancé, et qui a été présenté une semaine plus tôt. Vous pouvez essayer Qwen3-Next sur le site Web d'Alibaba (n'oubliez pas de le choisir dans le menu déroulant, en haut à gauche).
Qwen3-next. C'est ainsi que les modèles de cette famille sont appelés, parmi lesquels en particulier QWEN3-NEXT-80B-A3B, qui, selon les développeurs, est jusqu'à 10 fois plus rapide que le modèle QWEN3-32B qui a été lancé en avril. Ce qui est vraiment remarquable, c'est qu'il parvient également à être beaucoup plus rapide avec une réduction de 90% des coûts de formation.
500 000 $, ce n'est rien. Selon le rapport sur l'indice de l'IA de l'Université de Stanford, pour former le GPT-4 Openai, a investi 78 millions de dollars en calcul. Google a en outre été dépensé pour Gemini Ultra, et selon cette étude, le chiffre s'élevait à 191 millions de dollars. On estime que Qwen3-Next n'a coûté que 500 000 $ dans cette phase de formation.
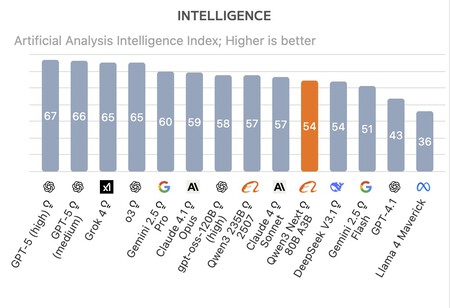
Mieux que ses concurrents. Selon les repères réalisés par l'analyse de l'entreprise artificielle, Qwen3-NEXT-80B-A3B a réussi à surmonter à la fois la dernière version de Deepseek R1 et Kimi-K2. Le nouveau modèle de raisonnement d'Alibaba n'est pas le meilleur en termes mondiaux-GPT-5, GROK 4, GEMINI 2.5 Pro Claude 4.1 Opus Opus It, mais obtient toujours des performances exceptionnelles en tenant compte de son coût de formation. Comment l'avez-vous fait?
Mélange d'experts. Ces modèles utilisent le mélange d'architecture experte (MOE). Avec lui, le modèle est « divisé » en une sorte de sous-réseaux neuronaux qui sont les « experts » spécialisés dans les sous-ensembles de données. Alibaba dans ce cas a augmenté le nombre de « experts »: tandis que Depseek-V3 et Kimi-K2 utilisent 256 et 384 experts, Qwen3-NEXT-80B-A3B utilise 512 experts, mais n'active que 10 en même temps.
Attention hybride La clé de cette efficacité est dans l'attention hybride si appelée. Les modèles actuels voient généralement leur efficacité réduite si la longueur d'entrée est très longue et doit « faire plus attention » et cela implique plus de calcul. Dans QWEN3-NEXT-80B-A3B, une technique appelée « Gated Deltanet » est faite qui a développé et partagé le MIT et NVIDIA en mars.
Deltanet fermé. Cette technique améliore la manière dont les modèles font attention lors de certains ajustements aux données d'entrée. La technique détermine les informations qui conservent et lesquelles peuvent être rejetées. Cela permet de créer un mécanisme de coût précis et super efficace. En fait, Qwen3-NEXT-80B-A3B est comparable au modèle Alibaba le plus puissant, Qwern3-235B-A22B-Thinking-2507.

Modèles efficaces et petits. Les coûts croissants de la formation de nouveaux modèles d'IA commencent à être inquiétants, ce qui a fait de plus en plus d'efforts pour créer de « petits » modèles de langue qui sont moins chers à former, sont plus spécialisés et particulièrement efficaces. Le mois dernier, Tencent a présenté des modèles inférieurs à 7 000 millions de paramètres, et une autre startup appelée Z.AI a publié son modèle d'air GLM-4.5 avec seulement 12 000 millions de paramètres actifs. Pendant ce temps, de grands modèles tels que GPT-5 ou Claude utilisent de nombreux autres paramètres, ce qui rend le calcul nécessaire pour les utiliser beaucoup plus.
Dans Simseo | Si la question est laquelle des grandes technologies gagne la carrière de l'IA, la réponse est: aucune