
Intégration d’étiquettes basée sur l’augmentation d’attributs pour le crowdsourcing
Le crowdsourcing offre un moyen efficace et peu coûteux de collecter les étiquettes des travailleurs participatifs. En raison du manque de connaissances professionnelles, la qualité des labels issus du crowdsourcing est relativement faible. Une approche courante pour résoudre ce problème consiste à collecter plusieurs étiquettes pour chaque instance auprès de différents travailleurs de foule, puis une méthode d’intégration d’étiquettes est utilisée pour déduire sa véritable étiquette. Cependant, presque toutes les méthodes d’intégration d’étiquettes existantes utilisent simplement les informations d’attribut d’origine et ne prêtent pas attention à la qualité de l’ensemble d’étiquettes bruitées multiples de chaque instance.
Pour résoudre ces problèmes, une équipe de recherche dirigée par Liangxiao JIANG a publié ses nouvelles recherches dans Frontières de l’informatique.
L’équipe a proposé une nouvelle méthode d’intégration d’étiquettes en trois étapes appelée intégration d’étiquettes basée sur l’augmentation des attributs (AALI). AALI améliore les performances de l’intégration des étiquettes en améliorant la capacité discriminante de l’espace d’attributs d’origine et en identifiant la qualité de l’ensemble d’étiquettes bruyantes multiples de chaque instance. Les résultats expérimentaux sur des ensembles de données simulés et réels issus du crowdsourcing démontrent qu’AALI surpasse tous les autres concurrents de pointe en termes de qualité d’étiquette et de qualité de modèle.
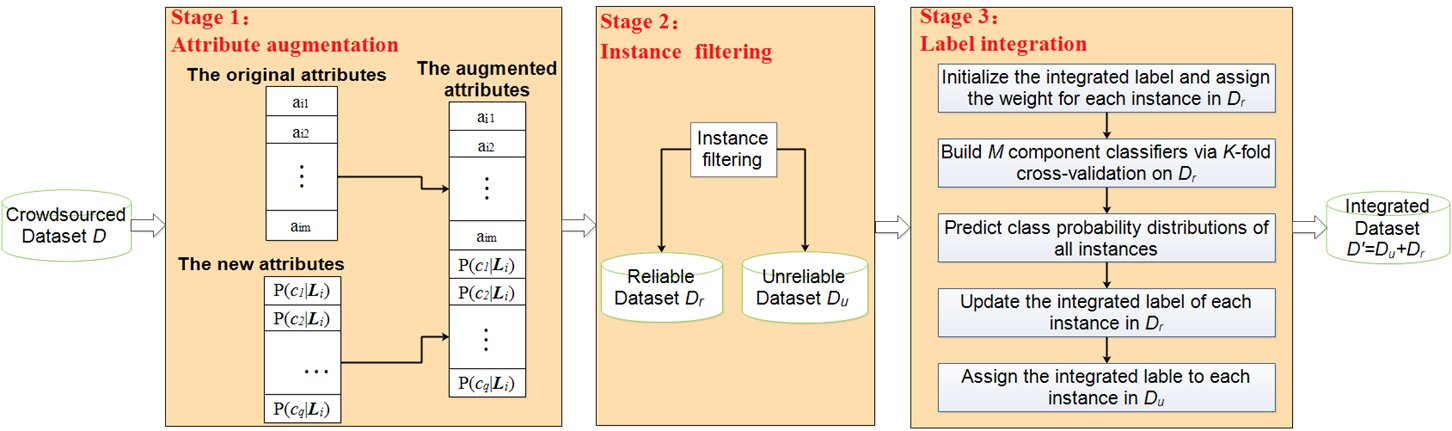
Dans la recherche, ils conçoivent une méthode d’augmentation d’attributs pour enrichir l’espace d’attributs, puis développent un filtre permettant de sélectionner des instances fiables avec plusieurs ensembles d’étiquettes bruyantes de haute qualité à partir d’un ensemble de données participatif. Enfin, ils utilisent la validation croisée pour créer plusieurs classificateurs de composants sur des instances fiables afin de prédire toutes les instances.
Dans la première étape, AALI définit les probabilités d’appartenance à une classe générées à partir d’un ensemble d’étiquettes bruyantes multiples en tant que nouveaux attributs et construit les attributs augmentés en concaténant les attributs d’origine avec les nouveaux attributs. Dans la deuxième étape, AALI développe un filtre pour distinguer les instances fiables avec plusieurs ensembles d’étiquettes bruyantes de haute qualité. En conséquence, l’ensemble de données d’origine est divisé en un ensemble de données fiable et un ensemble de données non fiable. Dans la troisième étape, AALI utilise le vote majoritaire pour initialiser les étiquettes intégrées de toutes les instances dans un ensemble de données fiables tout en estimant la certitude de chaque étiquette intégrée et en l’attribuant au poids de chaque instance.
Ensuite, AALI utilise la validation croisée K-fold pour créer des classificateurs de composants M sur un ensemble de données fiable afin de prédire les distributions de probabilité de classe de toutes les instances. Enfin, AALI met à jour l’étiquette intégrée de chaque instance dans un ensemble de données fiable et attribue l’étiquette intégrée à chaque instance dans un ensemble de données non fiable. Les résultats expérimentaux approfondis sur des ensembles de données simulés et réels validés par le crowdsourcing valident la supériorité d’AALI.
Les travaux futurs pourront se concentrer sur la recherche de la valeur optimale du seuil du filtre développé à l’aide d’une méthode d’optimisation.
Fourni par Frontiers Journals