
Les scientifiques font progresser la détection des pathologies vocales grâce à un apprentissage continu contradictoire
La pathologie vocale fait référence à un problème résultant de conditions anormales, telles que la dysphonie, la paralysie, les kystes et même le cancer, qui provoquent des vibrations anormales dans les cordes vocales (ou cordes vocales). Dans ce contexte, la détection des pathologies vocales (VPD) a reçu beaucoup d’attention en tant que moyen non invasif de détecter automatiquement les problèmes vocaux. Il se compose de deux modules de traitement : un module d’extraction de caractéristiques pour caractériser les voix normales et un module de détection vocale pour détecter les voix anormales.
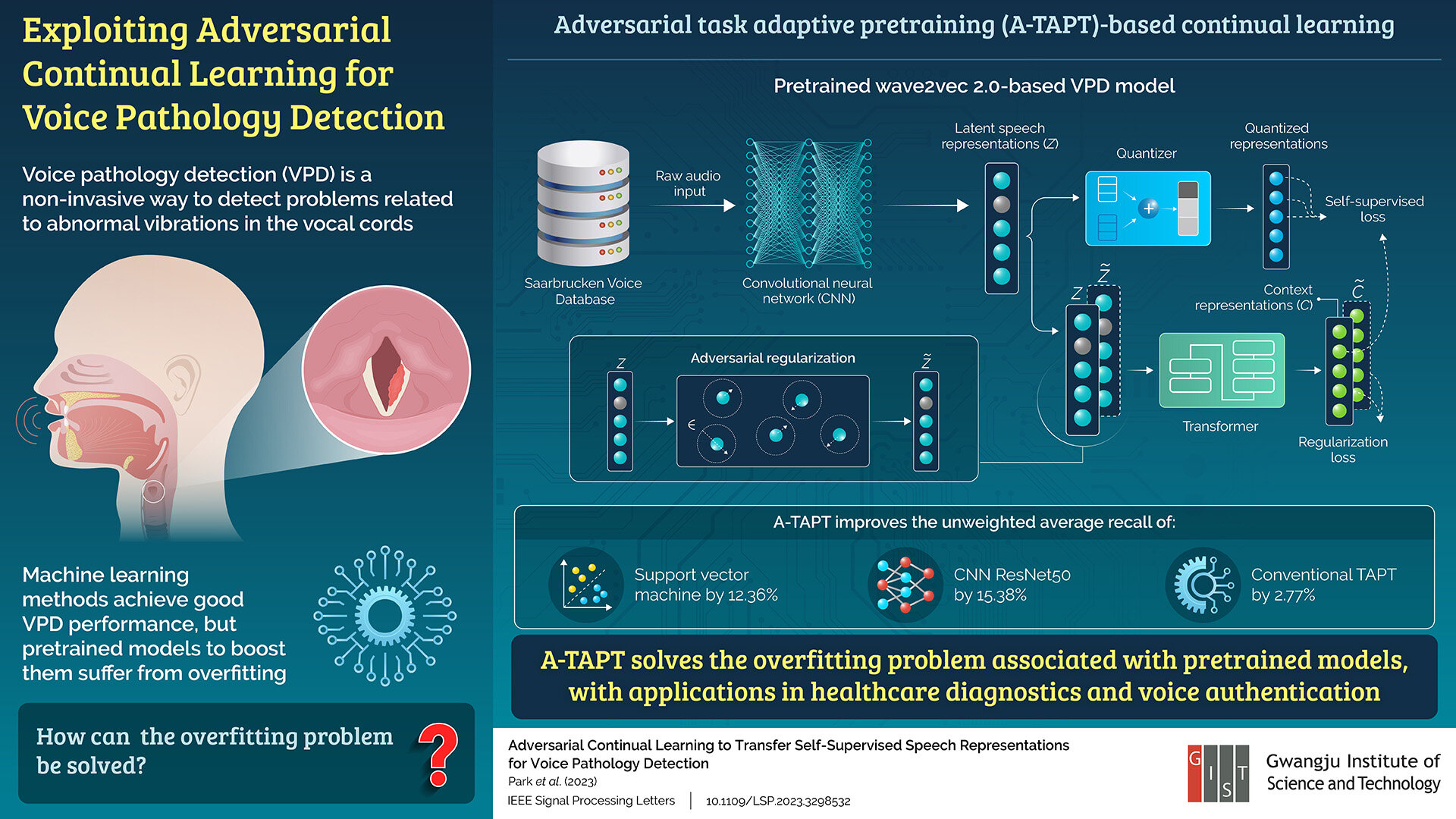
Les méthodes d’apprentissage automatique, telles que les machines à vecteurs de support (SVM) et les réseaux de neurones convolutifs (CNN), ont été utilisées avec succès comme modules de détection vocale pathologique pour obtenir de bonnes performances VPD. En outre, un modèle auto-supervisé et pré-entraîné peut apprendre une représentation générique et riche des caractéristiques vocales, au lieu de caractéristiques vocales explicites, ce qui améliore encore ses capacités VPD.
Cependant, le réglage fin de ces modèles pour le VPD conduit à un problème de surapprentissage, dû à un déplacement de domaine de la conversation vers la tâche VPD. En conséquence, le modèle pré-entraîné devient trop concentré sur les données d’entraînement et ne fonctionne pas bien sur les nouvelles données, empêchant la généralisation.
Pour atténuer ce problème, une équipe de chercheurs de l’Institut des sciences et technologies de Gwangju (GIST) en Corée du Sud, dirigée par le professeur Hong Kook Kim, a proposé une méthode d’apprentissage contrastive impliquant Wave2Vec 2.0, un modèle pré-entraîné auto-supervisé pour les signaux vocaux. -avec une nouvelle approche appelée préentraînement adaptatif aux tâches contradictoires (A-TAPT). Ici, ils ont incorporé la régularisation contradictoire au cours du processus d’apprentissage continu.
Les chercheurs ont réalisé diverses expériences sur le VPD à l’aide de la base de données vocale de Saarbrucken, constatant que l’A-TAPT proposé montrait une amélioration de 12,36 % et de 15,38 % du rappel moyen non pondéré (UAR), par rapport au SVM et au CNN ResNet50, respectivement. Il a également atteint un UAR 2,77 % plus élevé que l’apprentissage TAPT conventionnel. Cela montre qu’A-TAPT parvient mieux à atténuer le problème du surapprentissage.
Parlant des implications à long terme de ce travail, M. Park, le premier auteur de cet article, déclare : « D’ici cinq à dix ans, notre recherche pionnière sur la MPV, développée en collaboration avec le MIT, pourrait transformer fondamentalement la santé. soins, technologie et diverses industries. En permettant un diagnostic précoce et précis des troubles liés à la voix, cela pourrait conduire à des traitements plus efficaces, améliorant ainsi la qualité de vie d’innombrables personnes.
Leur article a été publié dans Lettres de traitement du signal IEEE.