
GLM 5.2 : alternative low-cost à Claude et GPT dans l’entreprise
GLM 5.2 est un LLM ouvert publié sous la licence MIT, l’une des licences ouvertes les plus permissives du marché. N’importe qui peut télécharger le modèle, le modifier, le perfectionner et l’utiliser commercialement, sans payer de redevances et sans restrictions d’utilisation ni contraintes géographiques. Cette libération intervient quelques jours seulement après le veto imposé par l’administration américaine à l’exportation des modèles phares d’Anthropic, Fable 5 et Mythos 5, qui en bloquait l’accès aux citoyens étrangers.
La réponse orientale aux modèles frontières arrive donc sur le marché à un moment idéal, juste au moment où les entreprises européennes commencent à chercher des alternatives aux géants américains.
GLM 5.2 est un modèle très performant, et même lorsqu’il est utilisé sur une infrastructure cloud, il coûte une fraction de Claude Opus ou GPT. Cependant, lorsqu’il s’agit d’intégrer un nouvel outil dans un pipeline d’automatisation, le coût extrait des tableaux de prix n’est pas le seul facteur pertinent, il est nécessaire d’évaluer son efficacité sur le terrain et les éventuels problèmes de qualité et de conformité.
GLM 5.2, un peu d’histoire
Z.ai est née en 2019 en tant que spin-out de l’Université Tsinghua de Pékin et est rapidement devenue la première entreprise au monde de grands modèles linguistiques à être cotée en bourse. Ces derniers mois, il a imposé un rythme de publication agressif, avec une spécialisation marquée sur les systèmes de code et d’agents qui effectuent des tâches de manière autonome, également à l’aide d’outils externes. La famille GLM-5 a été entièrement formée sur les puces Huawei Ascend 910B, sans matériel NVIDIA, et c’est un détail important d’un point de vue géopolitique.
GLM 5.2 est le modèle phare de Z.ai et utilise une architecture MoE (Mixture-of-Experts). Sur les quelque 744 milliards de paramètres totaux du modèle, seule une partie, environ 40 milliards, est activée pour chaque jeton traité. La quantité de texte que le modèle peut conserver en mémoire lors d’une conversation (fenêtre contextuelle) est d’un million de jetons, soit l’équivalent de plusieurs centaines de milliers de mots.
La génération sortante s’élève à environ 131 000 jetons, bien que certains fournisseurs puissent fixer des plafonds plus bas. GLM 5.2 propose alors deux niveaux de raisonnement, High et Max, qui équilibrent vitesse et profondeur du raisonnement. Le modèle, n’étant pas multimodal, fonctionne uniquement sur du texte et n’est pas capable de traiter des images.
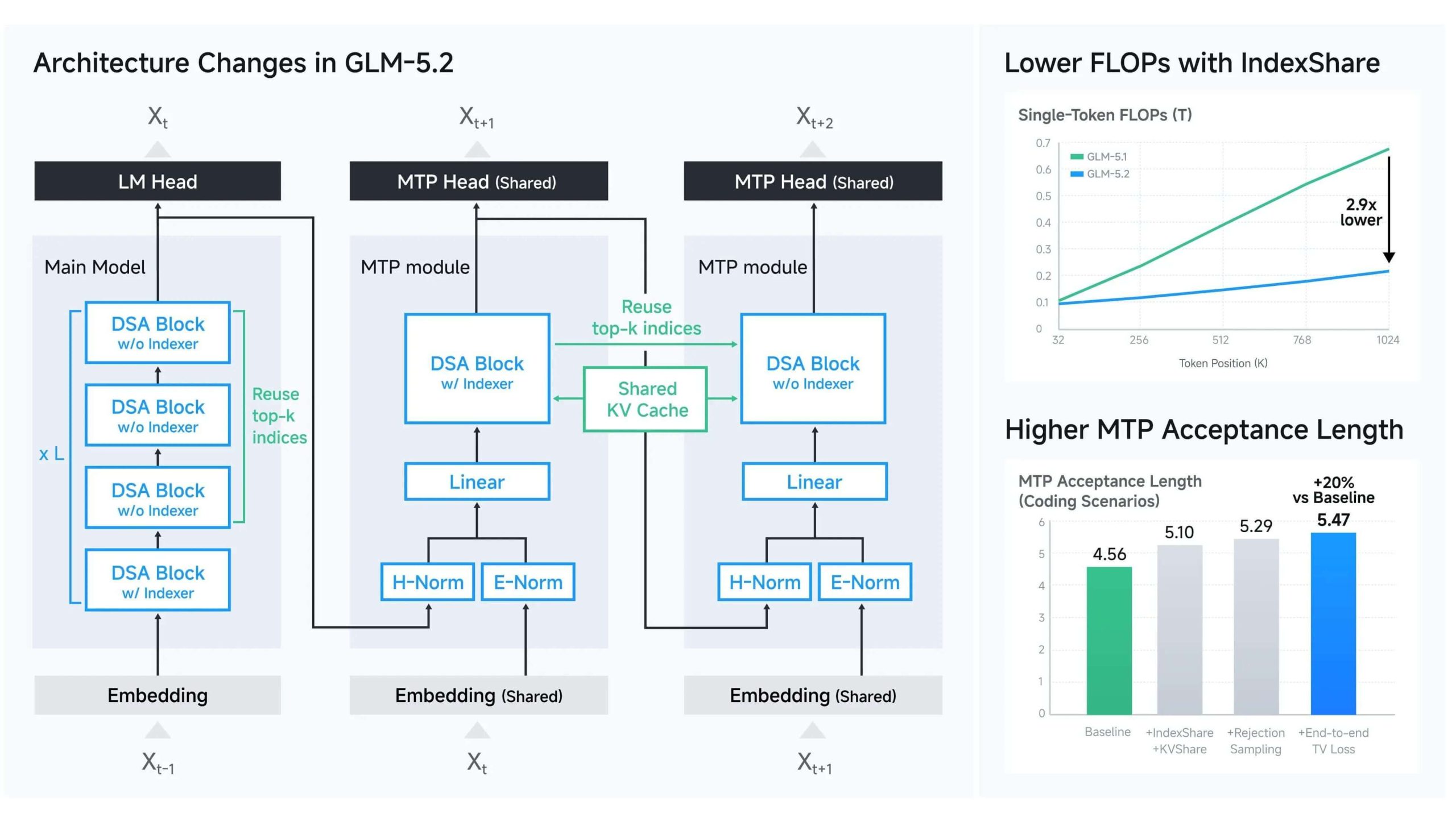
Sur le plan architectural, il y a deux innovations techniques intéressantes. Le premier s’appelle IndexShare, un mécanisme qui permet de réutiliser le même index du mécanisme d’attention tous les quatre niveaux du modèle, réduisant ainsi les opérations de calcul par token d’environ 2,9 fois lorsque le contexte est très long.
La seconde est une mise à jour de Multi-Token Prediction, une technique de décodage spéculatif qui tente de deviner plusieurs jetons à l’avance et, selon Z.ai, allonge la séquence acceptée jusqu’à 20 %, accélérant ainsi la génération.
Les résultats du GLM 5.2 dans les benchmarks
Les benchmarks sont des tests standardisés qui mesurent la capacité d’un modèle sur des tâches spécifiques, afin que vous puissiez le comparer avec d’autres. Z.ai a publié les résultats obtenus au moment de la publication, tandis qu’une vérification indépendante est venue de la société d’analyse Artificial Analysis. Les numéros suivants combinent les deux sources ; les données concernant GLM 5.2 proviennent de la fiche technique officielle du modèle et, pour Claude Opus 4.8, des résultats déclarés par Anthropic.
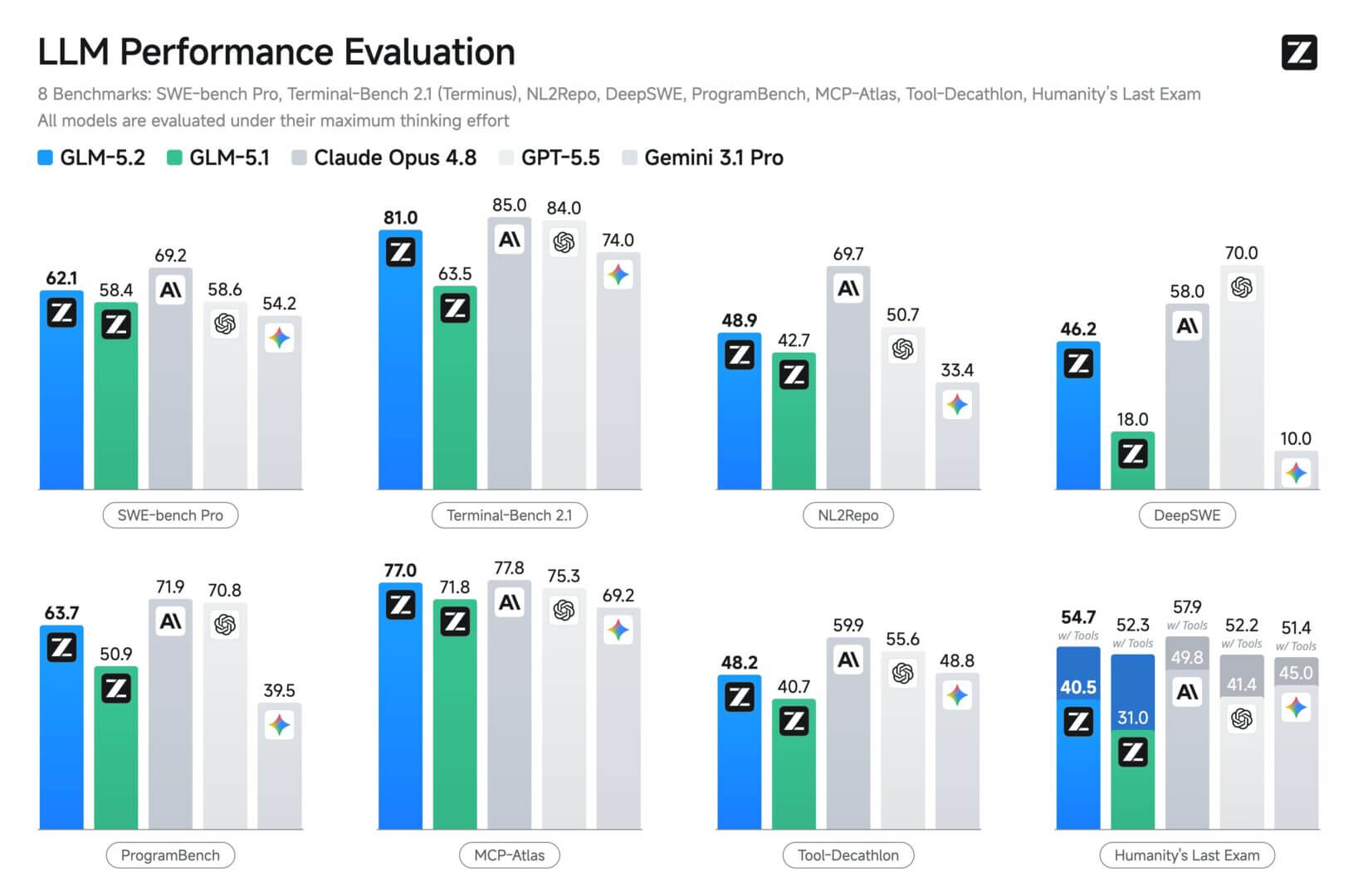
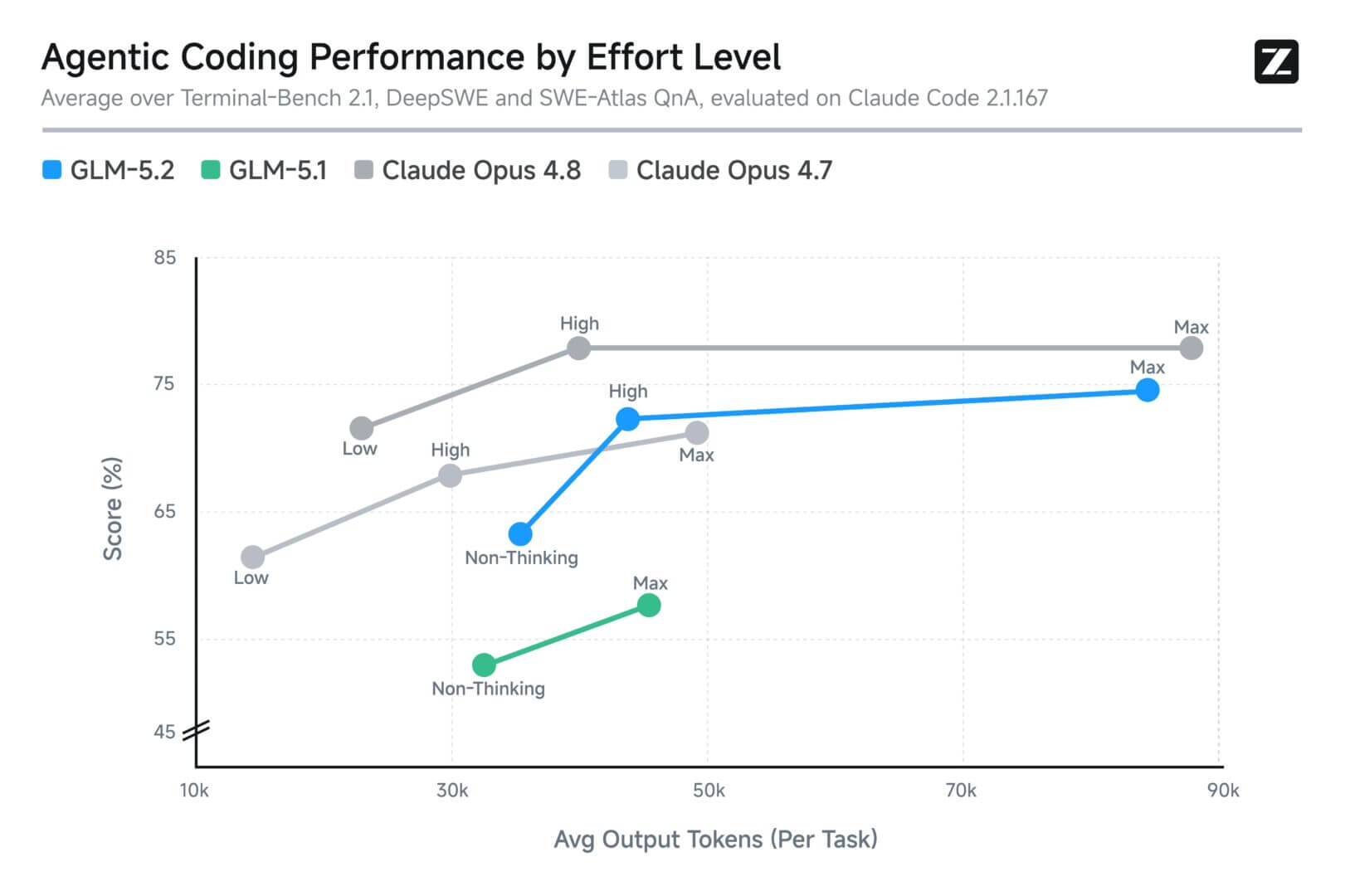
Selon ces tests, GLM 5.2 se situe désormais en tête du groupe des modèles ouverts, et est également capable de rivaliser sur un pied d’égalité avec les modèles frontières en matière de raisonnement, les surpassant même dans certains tests mathématiques. Lors des tests d’analyse artificielle, la dernière version de GLM a obtenu 51 points, devant DeepSeek V4 Pro (44), MiniMax-M3 (44) et Kimi K2.6 (43).
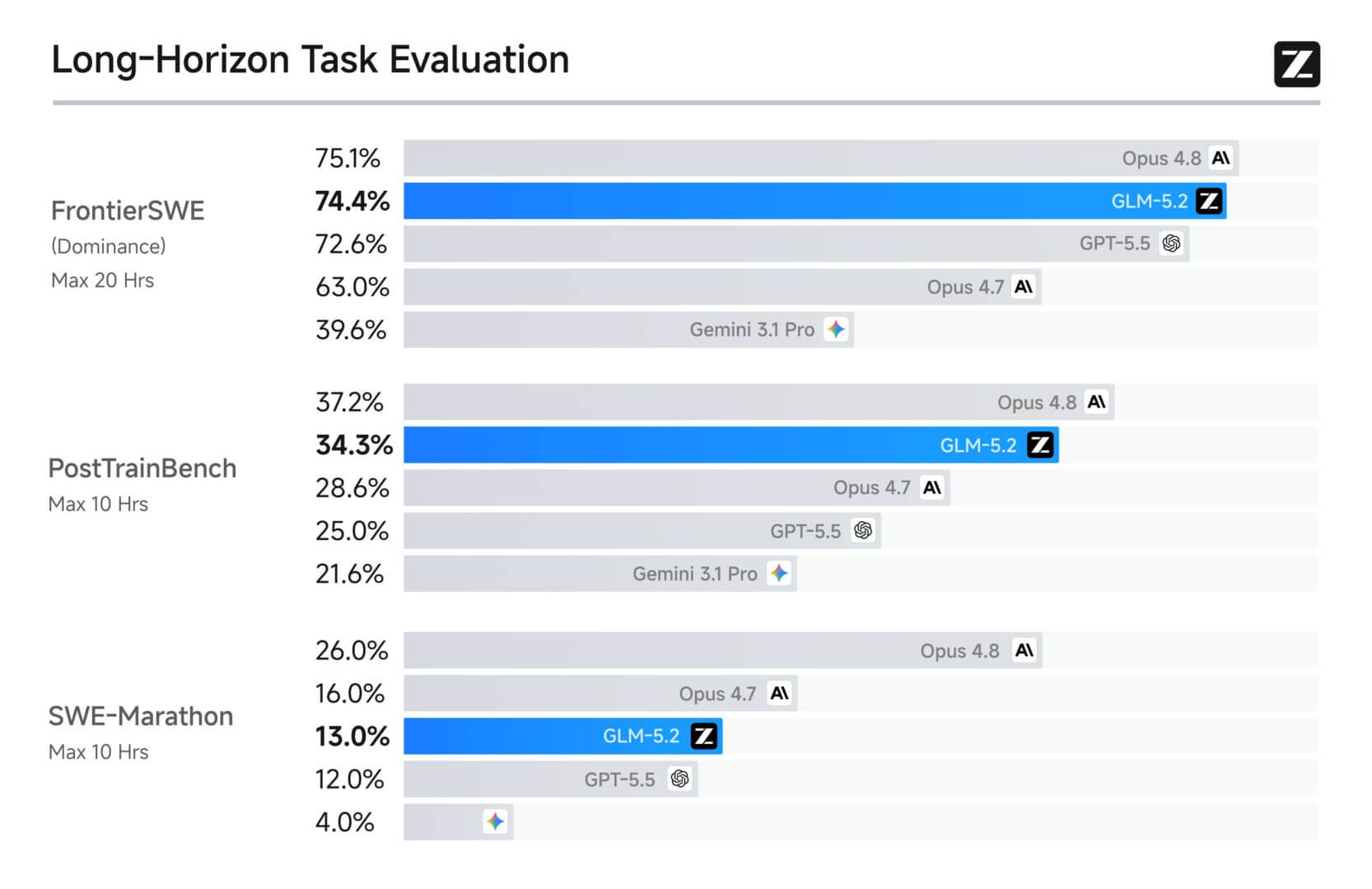
Sur des tâches de codage plus difficiles et plus longues, les modèles frontières conservent une marge d’avantage importante, par exemple l’écart sur SWE-Marathon est de 13 points contre 26 pour Opus.
Combien coûte GLM 5.2 ?
Lors du choix d’un modèle, les prix catalogue de l’API jouent un rôle important. Par million de jetons, Opus 4.8 coûte 5 $ pour l’entrée et 25 $ pour la sortie, tandis que GLM coûte 1,40 $ pour les jetons d’entrée et 4,40 $ pour la sortie. Les deux disposent d’un mécanisme de mise en cache qui permet de contrôler les coûts. Lorsque vous envoyez à plusieurs reprises le même contexte, par exemple une grande invite système fixe à chaque appel, la partie déjà traitée est facturée à un tarif réduit pour les deux modèles.
Les jetons mis en cache dans le cas d’Anthropic ont un coût de 0,50 dollar par million, tandis que pour GLM, ce coût est divisé par deux. L’outil de recherche Web intégré coûte environ un centime par utilisation, plus les jetons de demande.
Un benchmark de travail agent rapporté par Latent Space mesurait les dépenses moyennes par tâche pour une tâche de connaissances complexe, estimant 31 $ pour Fable 5, 10,40 $ pour Opus 4.8, 3,68 $ pour GPT-5.5 au mieux et 2,40 $ pour GLM 5.2. Le modèle chinois était globalement le moins cher par rapport aux autres systèmes du même niveau de performances.
Le dernier modèle de Z.ai garantit donc une économie notable sur le prix par token, mais lors des tests sur le terrain, il s’est montré très verbeux. Il produit de nombreux jetons de raisonnement, facturés au tarif de sortie, et sur des tâches longues et complexes, certaines des économies théoriques commencent à s’éroder. Le véritable avantage en termes de coût est donc de l’ordre de quatre à six fois selon la charge de travail, tout en restant substantiel.
Pour ceux qui utilisent le modèle dans les outils de développement, il existe également une alternative d’abonnement, le GLM Coding Plan, avec un tarif fixe qui commence à environ 10-15 dollars par mois pour les plans de base et atteint environ 80 dollars pour le plan Max.

Comment utiliser GLM 5.2 dans des scénarios réels
Le moyen le plus rapide de commencer à utiliser GLM 5.2 est l’API officielle Z.ai : dans ce cas cependant, tout le trafic passe par des infrastructures non soumises à la réglementation européenne. Pour les charges qui traitent des données personnelles dans le cadre du RGPD, c’est-à-dire les données des clients, des employés ou des patients, l’API officielle est un choix à exclure en production. La résidence des données, c’est-à-dire le lieu physique et juridique où les données sont traitées, échapperait dans ce cas au contrôle direct de l’entreprise.
Étant donné que les pondérations de ce modèle sont open source, n’importe qui peut héberger le modèle et en vendre l’accès. Les fournisseurs actifs incluent Fireworks, DeepInfra, Together AI, Nebius et CoreWeave, ainsi qu’OpenRouter, qui agit comme un routeur vers plus de dix fournisseurs et gère automatiquement la commutation en cas d’erreur.
Plusieurs de ces fournisseurs opèrent dans les juridictions américaines ou européennes, vous pouvez donc choisir en fonction de l’endroit où résident vos données, reprenant ainsi le contrôle que l’API officielle n’offre pas. Lors du choix, vous devez également tenir compte du fait que les fournisseurs les plus pratiques proposent des poids quantifiés de manière plus agressive.
La quantification consiste à réduire la précision numérique avec laquelle les poids du modèle sont stockés, afin de réduire la consommation de mémoire, au prix d’une légère diminution de la qualité. Les fournisseurs à bas prix proposent des versions de précision fp4, d’autres en fp8. L’écart de qualité, dans certains domaines d’application, peut être important et c’est la raison pour laquelle le prix varie.
Auto-hébergement
La troisième façon de commencer à utiliser GLM 5.2 est l’auto-hébergement, c’est-à-dire l’hébergement du modèle sur votre propre infrastructure, sur un cloud privé ou sur site. Les données ne quittent pas le périmètre de l’entreprise, et c’est ainsi qu’elles satisfont aux exigences de résidence des données et aux scénarios d’air gap, c’est-à-dire isolées du réseau. Dans ce cas, il faut toutefois tenir compte de l’investissement en matériel. L’auto-hébergement ne rapporte l’effort qu’à des volumes élevés et constants ; en dessous de ce seuil, l’API payante coûte moins cher et permet d’économiser sur les coûts de maintenance et de personnel technique spécialisé.
Quel que soit le mode d’utilisation choisi, un modèle à poids ouvert de qualité proche de la frontière présente un avantage évident : c’est un atout qu’aucun fournisseur ne peut révoquer du jour au lendemain. Le blocage de Fable a rendu ce risque plus perceptible, et GLM 5.2 propose une alternative intéressante.