

Voici GPT-5.5 : plus rapide, plus efficace et orienté agent
Le 23 avril 2026, OpenAI a dévoilé GPT-5.5, sept semaines après GPT-5.4. Le modèle arrive avec la variante Pro, il est déjà disponible pour les utilisateurs Plus, Pro, Business et Entreprise de ChatGPT et Codex, l’API coûtant 5 $ par million de jetons en entrée et 30 $ en sortie.
Le chiffre qui a fait le plus de bruit était de 82,7% : le score sur Terminal-Bench 2.0, le benchmark qui mesure la capacité d’un modèle à gérer des workflows complexes depuis la ligne de commande, avec planification, itération et coordination des outils. GPT-5.4 s’est arrêté à 75,1%, Claude Opus 4.7 à 69,4%, Gemini 3.1 Pro à 68,5%. La distance est visible à l’œil nu en production, sur des tâches réelles.
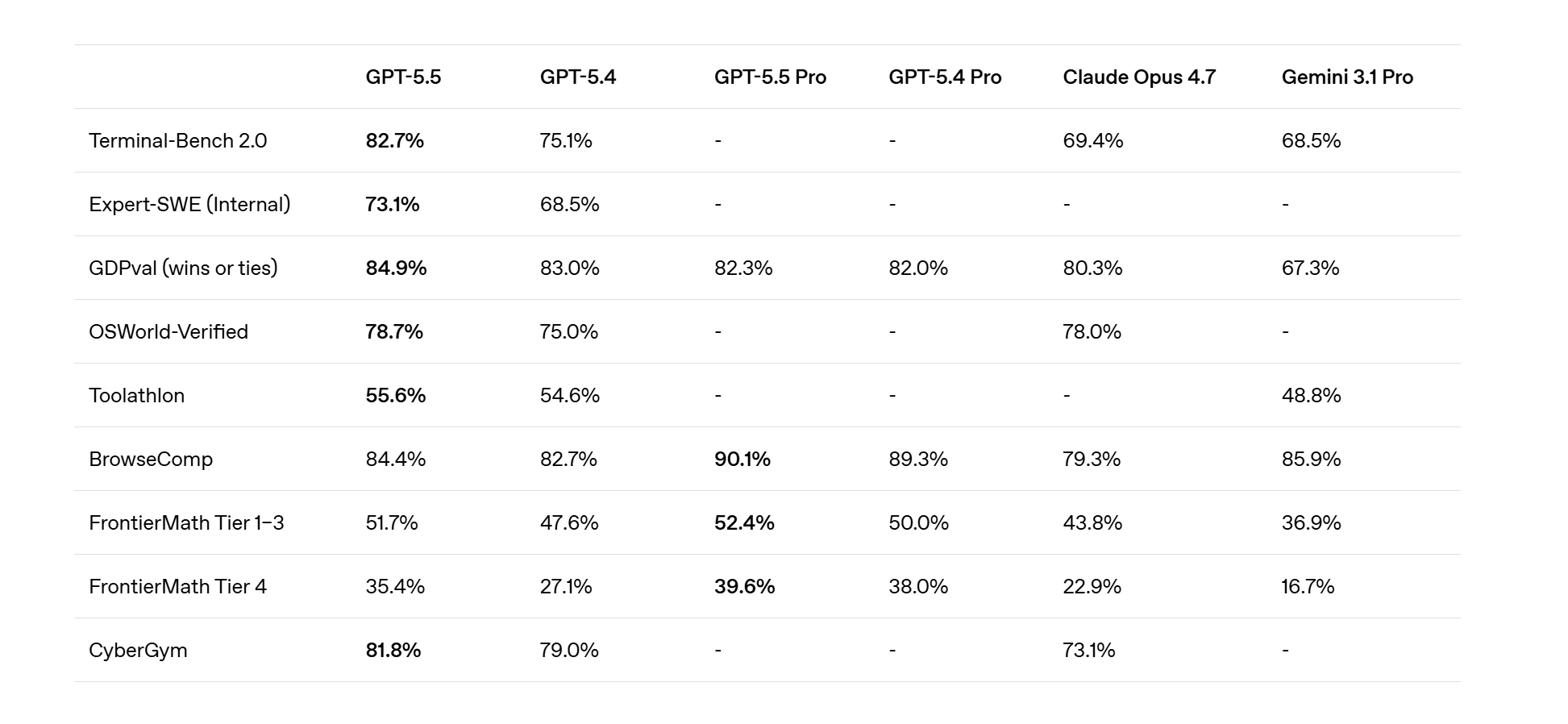
Efficacité, rapidité et coûts de GPT-5.5
Mais l’important n’est pas seulement le saut par rapport aux concurrents. OpenAI revendique une amélioration sur presque toutes les dimensions mesurées, en conservant la même latence par jeton que GPT-5.4, en réduisant le nombre de jetons consommés pour accomplir la même tâche et en poussant la vitesse de génération au-delà de 20 % grâce à une nouvelle heuristique d’équilibrage de charge co-conçue avec Nvidia sur les systèmes GB200 et GB300 NVL72.
Un modèle plus intelligent, plus économique en coûts d’exploitation pour le même rendement, plus rapide en remboursement et plus cher par jeton unique. Des vecteurs qui se poussent généralement dans des directions opposées, et ici ils coexistent.
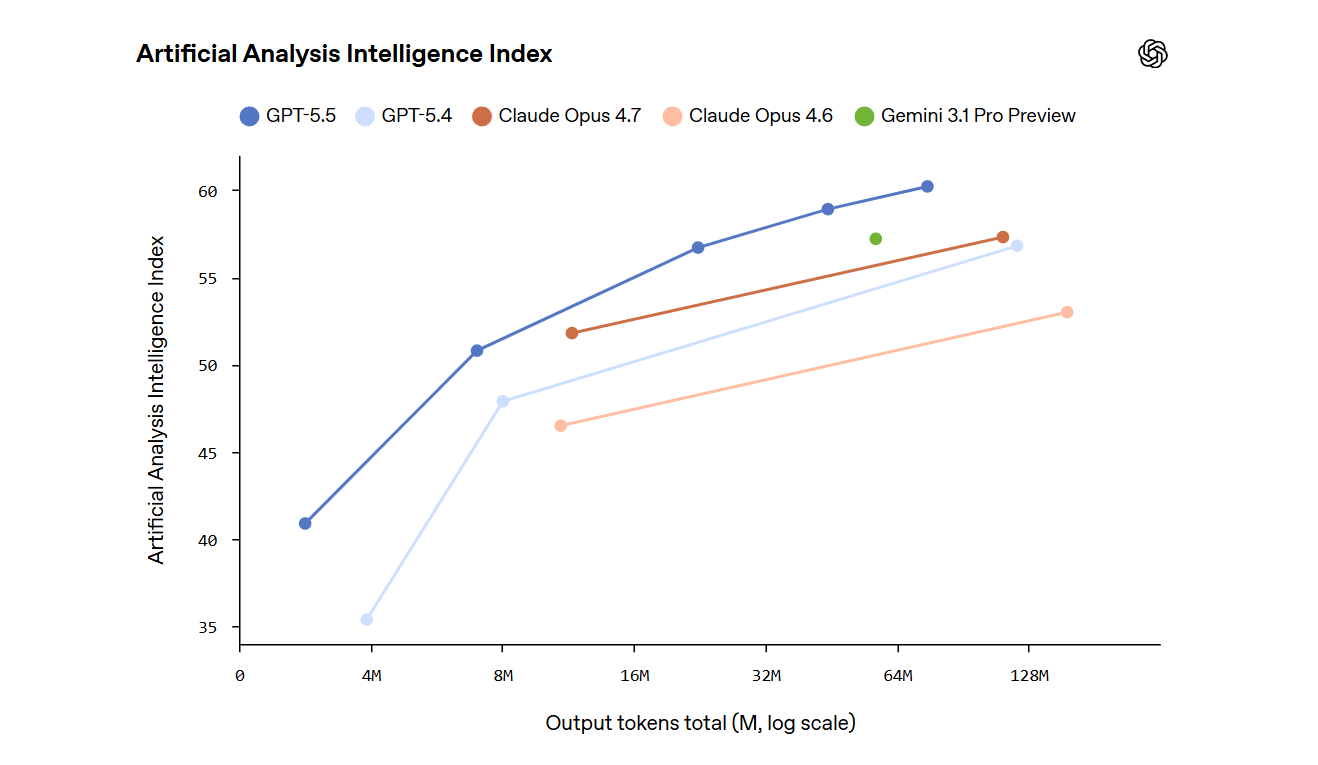
GPT-5.5 et codage agent dans les travaux de développement
Le mot à la mode est « codage agent ». Un modèle qui ne répond pas simplement à des questions de programmation, mais prend en charge une tâche, la planifie, utilise des outils, vérifie ses résultats intermédiaires, poursuit le travail sans s’arrêter à chaque étape.
Sur SWE-Bench Pro, qui évalue la résolution de problèmes réels avec GitHub, GPT-5.5 atteint 58,6 % en un seul passage, tandis que Claude Opus 4.7 conserve un avantage à 64,3 % pour les tâches multi-fichiers complexes.
La lecture des benchmarks renvoie une cartographie des atouts spécifiques, qui en production se traduisent par différents choix de modèles en fonction de la nature de la tâche.
Commentaires et compréhension des développeurs
Les retours des développeurs en avant-première insistent sur un aspect qui se ressent dans les chiffres mais ne se lit pas : le modèle comprend la forme d’un système logiciel. Pourquoi quelque chose échoue, où le correctif doit atterrir, qu’est-ce qui se brise en aval si vous touchez une certaine classe.
Dan Shipper, fondateur de Chaquel’a décrit comme le premier modèle de codage avec une grande clarté conceptuelle : après des jours de débogage d’une application après le lancement, son équipe a dû faire appel à un ingénieur senior pour réécrire une partie du système, GPT-5.4 n’avait pas réalisé ce type de réécriture, alors que GPT-5.5 avec les mêmes entrées l’avait fait.
Michael Truell par Curseur il a ajouté un détail opérationnel que reconnaît quiconque a essayé de mettre un agent en production : le modèle reste en mission plus longtemps, il n’abandonne pas plus tôt que prévu. Il s’agissait d’un problème chronique des modèles précédents avec les tâches longues, et il n’était pas réparable avec de meilleures invites.

GPT-5.5 en recherche scientifique et co-scientifique
Le raisonnement sort du laboratoire, de la recherche scientifique et du co-scientifique. Le chapitre le plus surprenant du communiqué concerne la recherche scientifique. Une version interne de GPT-5.5 avec un harnais dédié a permis de trouver une nouvelle preuve sur un fait asymptotique concernant les nombres de Ramsey hors diagonale, objet central de la combinatoire, puis formellement vérifié en Lean.
La combinatoire étudie la façon dont les objets discrets se combinent les uns avec les autres, les graphiques, les réseaux, les ensembles, les modèles et les nombres de Ramsey demandent, en un mot, quelle doit être la taille d’un réseau pour qu’un certain type d’ordre émerge inévitablement.
Les résultats dans ce domaine sont rares, techniquement difficiles, et le fait qu’un LLM contribue à un résultat formellement vérifiable dans ce domaine est une nouvelle différente de « le chatbot rédige mieux les e-mails ».
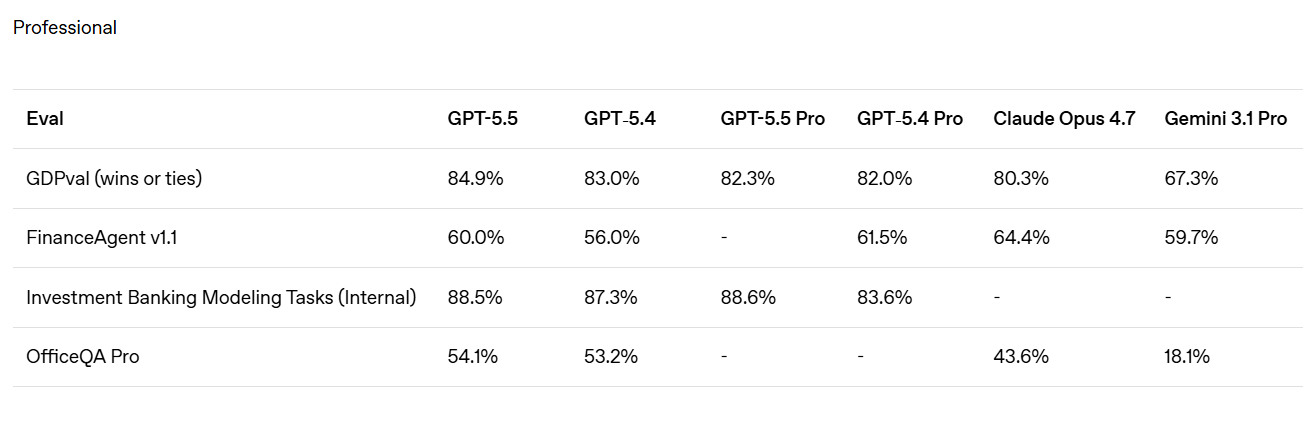
Applications concrètes de GPT-5.5 en bioinformatique
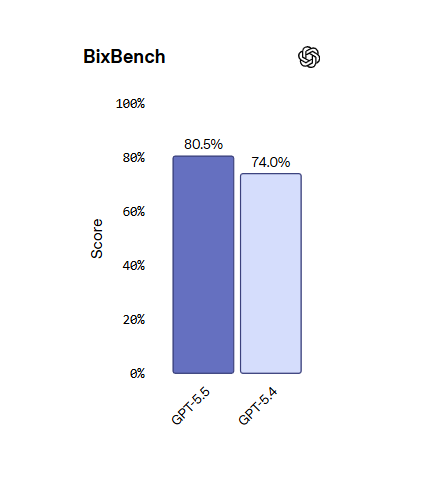
Sur BixBench, un benchmark bioinformatique construit sur des données réelles, GPT-5.5 atteint 80,5 % contre 74 % pour GPT-5.4. Un professeur d’immunologie cité dans le communiqué a utilisé GPT-5.5 Pro pour analyser un ensemble de données comprenant 62 échantillons et environ 28 000 gènes, produisant ainsi un rapport qui, selon lui, prendrait des mois à son équipe.
Ce sont des anecdotes, elles doivent être lues avec prudence, mais le schéma est cohérent avec les autres témoignages recueillis par les journaux qui ont suivi le lancement : le modèle est utile non seulement pour répondre à des questions, mais pour itérer sur un problème étalé dans le temps. Pour rester dans une recherche.
GPT-5.5 dans le travail de bureau et le travail intellectuel
Dans le travail de bureau, OpenAI pousse fortement la notion de travail de connaissances : analyse de données, génération de documents et de présentations, automatisation des flux métiers. En interne, l’équipe financière d’OpenAI a utilisé GPT-5.5 dans le Codex pour examiner 24 771 formulaires fiscaux K-1 totalisant 71 637 pages, raccourcissant le cycle de deux semaines par rapport à l’année précédente.
Il ne s’agit pas d’un cas d’utilisation unique, mais il donne l’échelle à laquelle le modèle peut fonctionner lorsqu’il a accès aux fichiers et systèmes appropriés.
Benchmarks professionnels et comparaison avec les concurrents
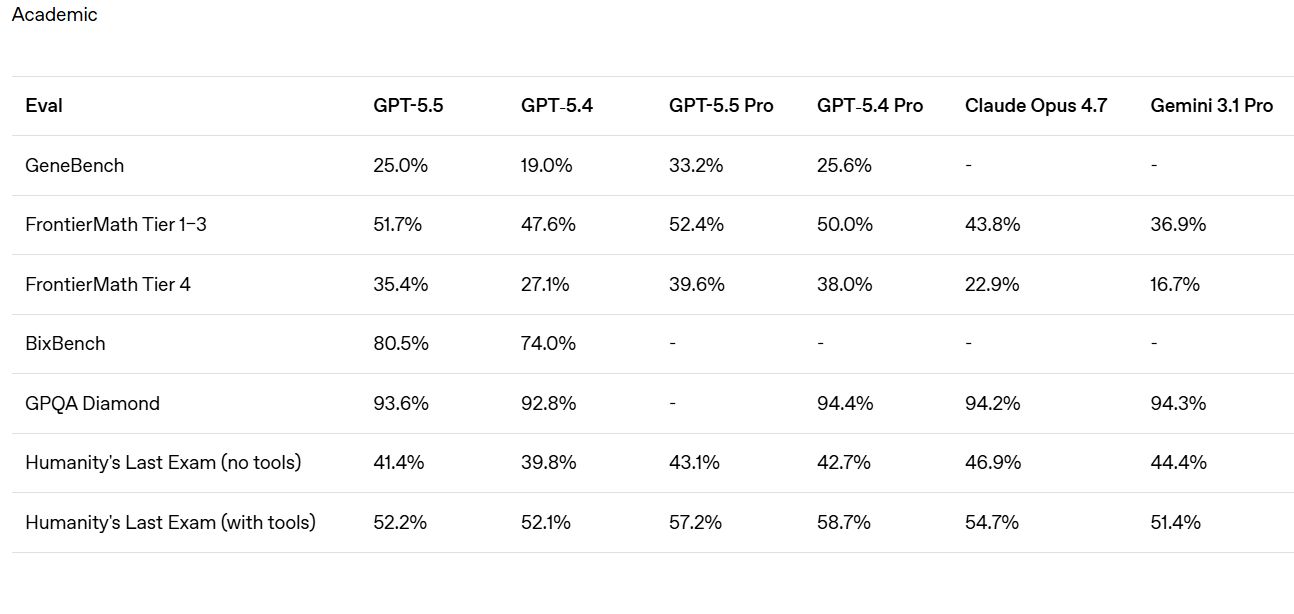
Sur GDPval, la métrique utilisée par OpenAI pour évaluer le travail de connaissances, GPT-5.5 s’élève à 84,9 %, contre 46,8 % pour Gemini 3.1 Pro.
Il vaut la peine de s’arrêter un instant sur ce que signifie GDPval, car c’est un référentiel différent des autres, il mesure la production de véritables artefacts professionnels, un argumentaire de vente, un planning des urgences, une fiche fiscale.
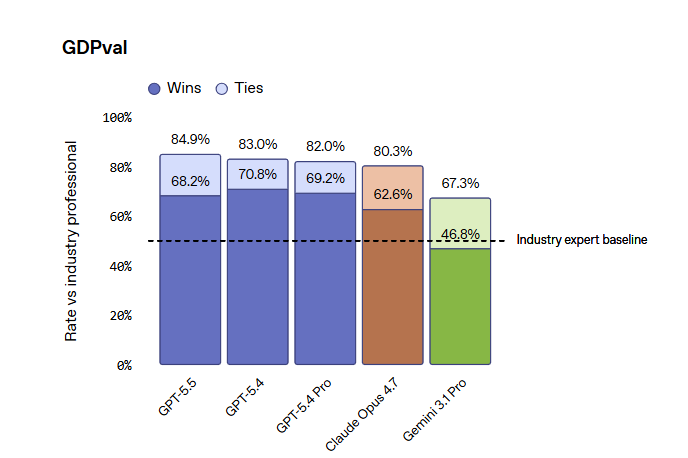
Sur FinanceAgent v1.1, Claude Opus 4.7 reste cependant en tête à 64,4% contre 60,0% de GPT-5.5, et OpenAI l’admet ouvertement dans le tableau officiel, ce qui est nouveau par rapport aux lancements précédents où le comparaison ils n’ont été publiés que là où ils ont gagné.
Prix, jetons et coût réel par résultat
La question des coûts mérite une attention particulière, car c’est là qu’intervient une grande partie du raisonnement en faveur de l’adoption par les entreprises. Le prix de l’API est le double du GPT-5,4 par jeton, soit 5/30 dollars par million au lieu de 2,5/15 (GPT-5.5 Pro même 30/180), mais OpenAI déclare que pour effectuer les mêmes tâches dans le Codex, le modèle utilise beaucoup moins de jetons.
Le coût réel par résultat, et non par jeton, peut donc être inférieur. Cela doit être vérifié sur le terrain, au cas par cas, et c’est un modèle de tarification qui récompense ceux qui mesurent les dépenses en fonction du résultat produit et non de la consommation brute. Pour ceux qui pensent d’un point de vue agent, c’est exactement la bonne mesure.
Sécurité et cybersécurité avec GPT-5.5
Sur le plan de la sécurité, OpenAI classe les capacités biologiques/chimiques et de cybersécurité de GPT-5.5 comme «Haut», un cran en dessous du niveau « Critique», et publie un ensemble de garanties plus strictes que la génération précédente.
En pratique, ceux qui travaillent sur des recherches légitimes dans le domaine cyber peuvent trouver quelques filtres supplémentaires au début, avec quelques faux positifs sur des requêtes passées inaperçues sur GPT-5.4. Il existe un programme Trusted Access pour moi défenseur vérifiéceux qui défendent les infrastructures critiques peuvent demander un accès dédié.
Concurrence entre modèles d’IA
Il y a aussi un élément contextuel qu’il convient de garder à l’esprit lors de la lecture d’un jeu compétitif. Anthropic a quelque chose appelé Claude Mythos Preview qui n’est toujours pas disponible dans le commerce, il est classé par Anthropic comme actif stratégique défensif à haut risque cyber et accessible uniquement à un nombre limité de partenaires et d’agences gouvernementales.
La concurrence sur le marché commercial reste donc entre GPT-5.5, Gemini 3.1 Pro et Claude Opus 4.7, et sur ce périmètre GPT-5.5 revient en tête du classement composite. Indice d’intelligence d’analyse artificielle avec 59 points, contre une moyenne de 33 pour des modèles comparables.
Impact du GPT-5.5 dans les entreprises
Du point de vue de ceux qui adoptent l’IA dans l’entreprise, ce lancement soulève trois questions concrètes, auxquelles il convient de répondre immédiatement, sans attendre la prochaine vague de releases.
Le premier concerne les achats. Si l’organisation a des contrats ouverts sur GPT-5.4, le passage à GPT-5.5 nécessite une réévaluation du rapport coût/résultat sur les cas d’utilisation réellement en production.
La deuxième question est celle de l’architecture. Un modèle qui comprend la forme d’un système logiciel modifie le périmètre de ce qui peut être délégué à un agent par rapport à ce qui reste entre les mains de l’ingénieur.
Le troisième est le portefeuille. GPT-5.5 n’est pas le meilleur modèle pour tout, la pratique commerciale judicieuse consiste à construire une architecture multimodèle.
Le défi organisationnel de l’adoption de l’IA
Reste une question ouverte, la plus intéressante, celle qu’aucun benchmark ne permet de saisir : à quelle vitesse les organisations parviennent-elles à absorber ce rythme d’innovation. Sept semaines entre GPT-5.4 et GPT-5.5 est un cycle que la plupart des entreprises ne savent pas encore gérer.
Le risque de rester toujours un modèle en retard n’est pas technologique, il est organisationnel. Sans aucun doute, le rythme va continuer, a déclaré OpenAI, Anthropic aussi, Google aussi. La véritable compétition sera alors entre ceux qui ont conçu des processus capables d’absorber ces sauts et ceux qui ne l’ont pas fait ?