
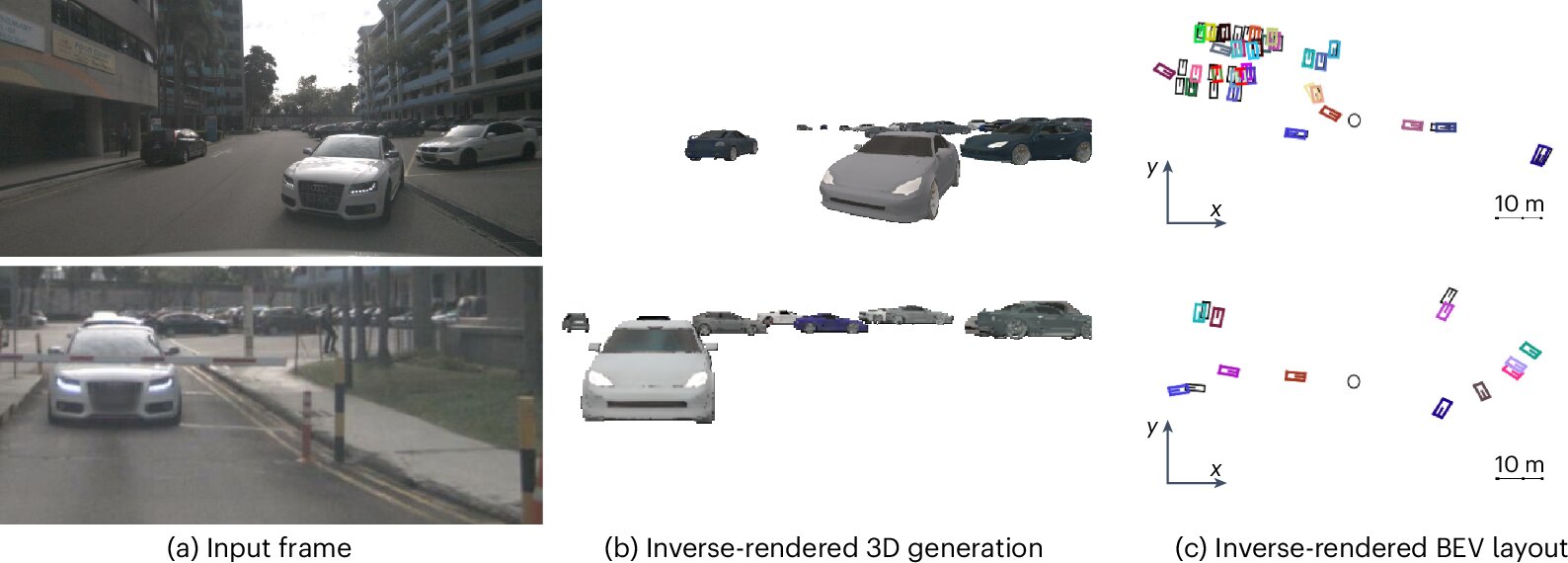
La méthode AI reconstruit les détails de la scène 3D à partir d'images simulées en utilisant le rendu inverse
Au cours des dernières décennies, les informaticiens ont développé de nombreux outils de calcul qui peuvent analyser et interpréter des images. Ces outils se sont révélés utiles pour un large éventail d'applications, notamment la robotique, la conduite autonome, les soins de santé, la fabrication et même le divertissement.
La plupart des approches de vision informatique les plus performantes utilisées à ce jour reposent sur des réseaux neuronaux dits de la Feed-Forward. Ce sont des modèles de calcul qui traitent les images d'entrée étape par étape, ce qui fait finalement des prédictions à leur sujet.
Bien que certains de ces modèles se soient bien comportés lorsqu'ils sont testés sur les données qu'ils ont analysées pendant la formation, elles ne se généralisent souvent pas bien sur de nouvelles images et dans différents scénarios. De plus, leurs prédictions et les modèles qu'ils extraient des images peuvent être difficiles à interpréter.
Des chercheurs de l'Université de Princeton ont récemment développé une nouvelle approche de rendu inverse qui est plus transparente et pourrait également interpréter un large éventail d'images de manière plus fiable. La nouvelle approche, introduite dans un article publié dans Intelligence de la machine de la natures'appuie sur une méthode générative basée sur l'intelligence artificielle (AI) pour simuler le processus de création d'image, tout en l'optimisant en ajustant progressivement les paramètres internes d'un modèle.
« L'IA générative et le rendu neuronal ont transformé le domaine ces dernières années pour créer de nouveaux contenus: produire des images ou des vidéos à partir de descriptions de scène », a déclaré à Tech Xplore Felix Heide, auteur principal du journal. « Nous étudions si nous pouvons retourner cela et utiliser ces modèles génératifs pour extraire les descriptions de la scène des images. »
La nouvelle approche développée par Heide et ses collègues s'appuie sur un soi-disant pipeline de rendu différenciable. Il s'agit d'un processus pour la simulation de la création d'images, en s'appuyant sur des représentations compressées d'images créées par des modèles d'IA génératifs.
« Nous avons développé une approche d'analyse par synthèse qui nous permet de résoudre les tâches de vision, telles que le suivi, comme problèmes d'optimisation du temps de test », a expliqué Heide. « Nous avons constaté que cette méthode se généralise entre les ensembles de données et contrairement aux méthodes d'apprentissage supervisées existantes, n'a pas besoin d'être formé sur de nouveaux ensembles de données. »
Essentiellement, la méthode développée par les chercheurs fonctionne en plaçant des modèles d'objets 3D dans une scène virtuelle représentant des paramètres du monde réel. Ces modèles d'objets sont générés par une IA générative basée sur un échantillon aléatoire de paramètres de scène 3D.
« Nous rendons ensuite tous ces objets ensemble dans une image 2D », a déclaré Heide. « Ensuite, nous comparons cette image rendue avec la véritable image observée. En fonction de leur différence, nous sommes en rétropropagation de la différence à la fois par la fonction de rendu différenciable et le modèle de génération 3D pour mettre à jour ses entrées. En quelques étapes, nous optimisons ces entrées pour faire correspondre mieux les images observées. »


Un avantage notable de l'approche nouvellement proposée de l'équipe est qu'il permet de bien génériques de modèles d'objets 3D génériques formés sur des données synthétiques pour bien fonctionner sur une large gamme d'ensembles de données contenant des images capturées dans des paramètres du monde réel. De plus, les rendus produits par les modèles sont beaucoup plus expliqués que ceux produits par des outils de rendu conventionnels basés sur des modèles d'apprentissage automatique pour les aliments pour flux.
« Notre approche de rendu inverse pour le suivi des œuvres aussi bien que les approches apprises à la promenade, mais elle nous fournit des explications 3D explicites de son monde perçu », a déclaré Heide.
« L'autre aspect intéressant est les capacités de généralisation. Sans modifier le modèle de génération 3D ou le former sur de nouvelles données, notre suivi multi-objet 3D par le rendu neuronal inverse fonctionne bien dans différents ensembles de données de conduite autonomes et types d'objets.
Cette étude récente pourrait bientôt aider à faire progresser les modèles d'IA pour la vision par ordinateur, améliorant leurs performances dans des paramètres du monde réel tout en augmentant leur transparence. Les chercheurs prévoient désormais de continuer à améliorer leur méthode et à commencer à les tester sur plus de tâches liées à la vision par ordinateur.
« Une prochaine étape logique est l'expansion de l'approche proposée des autres tâches de perception, telles que la détection 3D et la segmentation 3D », a ajouté Heide. « En fin de compte, nous voulons explorer si le rendu inverse peut même être utilisé pour déduire toute la scène 3D, et pas seulement des objets individuels.
Écrit pour vous par notre auteur Ingrid Fadelli, édité par Gaby Clark, et vérifié et examiné par Robert Egan – cet article est le résultat d'un travail humain minutieux. Nous comptons sur des lecteurs comme vous pour garder le journalisme scientifique indépendant en vie. Si ce rapport vous importe, veuillez considérer un don (surtout mensuel). Vous obtiendrez un sans publicité compte comme un remerciement.