
L'agent d'IA multimodal imite la pensée humaine pour une longue analyse vidéo et un raisonnement
Alors que la technologie de l'intelligence artificielle (IA) évolue rapidement, les modèles d'IA ont toujours du mal à comprendre les longues vidéos. Une équipe de recherche de la Hong Kong Polytechnic University (Polyu) a développé un nouvel agent vidéo en langue vidéo, Videomind, qui permet aux modèles d'IA d'effectuer un long raisonnement vidéo et des tâches de réponse aux questions en émulant la façon de penser des humains.
Le cadre Videomind intègre une stratégie d'adaptation innovante de chaîne de rang (LORA) pour réduire la demande de ressources informatiques et de puissance, faisant progresser l'application de l'IA générative dans l'analyse vidéo. Les résultats ont été soumis aux conférences d'IA à la tête mondiale.
Les vidéos, en particulier celles de plus de 15 minutes, transportent des informations qui se déroulent au fil du temps, telles que la séquence des événements, la causalité, la cohérence et les transitions de scène. Pour comprendre le contenu vidéo, les modèles d'IA doivent donc non seulement identifier les objets présents, mais également prendre en compte la façon dont ils changent tout au long de la vidéo. Comme les visuels dans les vidéos occupent un grand nombre de jetons, la compréhension vidéo nécessite de grandes quantités de capacité informatique et de mémoire, ce qui rend difficile pour les modèles d'IA de traiter les longues vidéos.
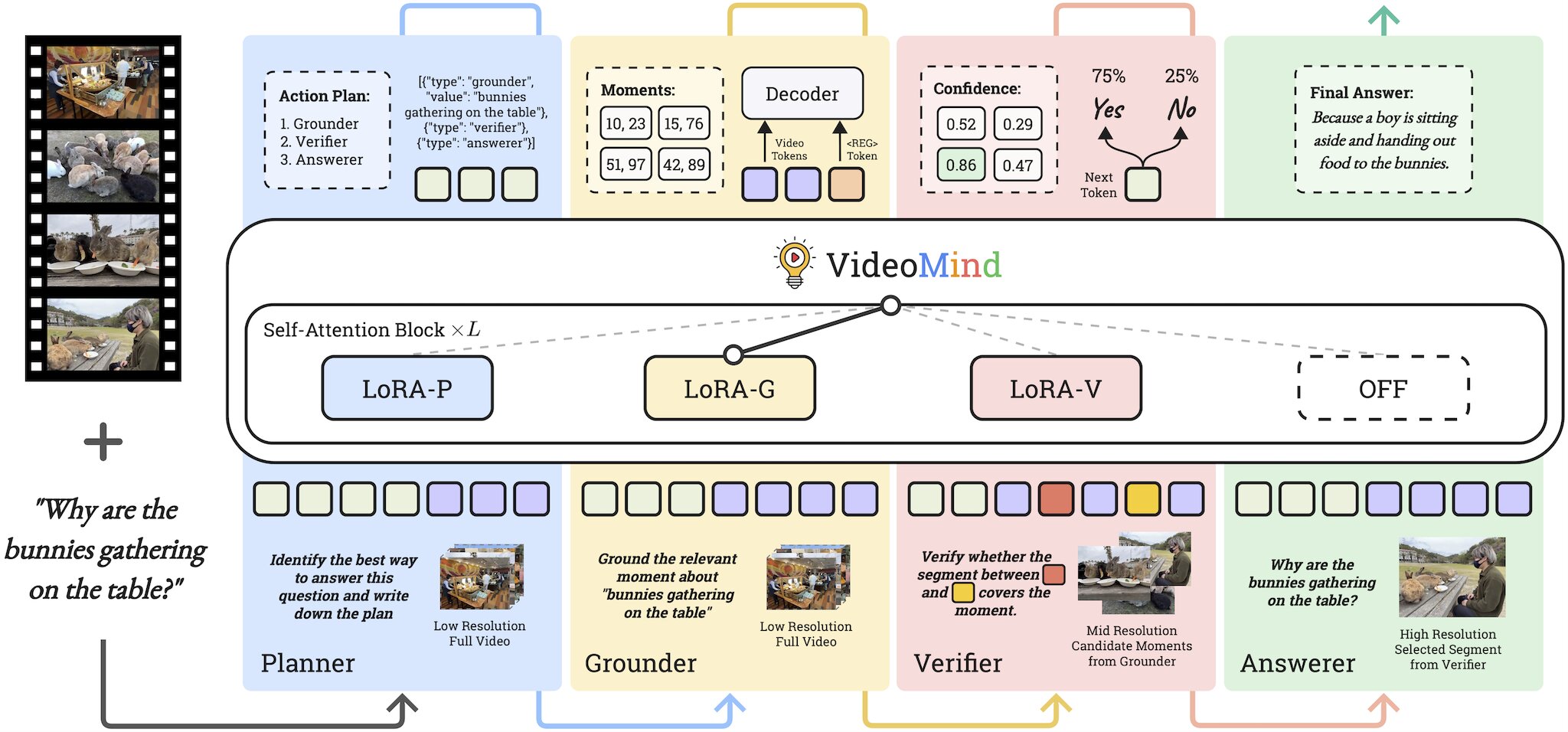
Le professeur Changwen Chen, doyen intérimaire de la Faculté de Polyu of Computer and Mathematical Sciences et professeur de président de l'informatique visuelle, et son équipe a réalisé une percée dans la recherche sur le raisonnement vidéo long par l'IA. En concevant Videomind, ils ont fait référence à un processus de compréhension vidéo de type humain et ont introduit un flux de travail basé sur des rôles. Les quatre rôles inclus dans le cadre sont:
- le planificateur, pour coordonner tous les autres rôles pour chaque requête;
- le Grounder, pour localiser et récupérer des moments pertinents;
- le vérificateur, pour valider la précision des informations des moments récupérés et sélectionner le plus fiable;
- et le répondant, pour générer la réponse consciente de la requête.
Cette approche progressive de la compréhension vidéo aide à relever le défi du raisonnement temporel auquel la plupart des modèles d'IA sont confrontés.
Une autre innovation fondamentale du cadre Videomind réside dans son adoption d'une stratégie de chaîne de lora. Lora est une technique de financement qui a émergé ces dernières années. Il adapte les modèles d'IA pour des utilisations spécifiques sans effectuer un recyclage à paramètre complet. La stratégie innovante de la chaîne de lora lancée par l'équipe consiste à appliquer quatre adaptateurs LORA légers dans un modèle unifié, chacun conçu pour appeler un rôle spécifique.
Avec cette stratégie, le modèle peut activer dynamiquement les adaptateurs LORA spécifiques aux rôles pendant l'inférence via l'auto-puissance pour basculer de manière transparente entre ces rôles, éliminant le besoin et le coût du déploiement de plusieurs modèles tout en améliorant l'efficacité et la flexibilité du modèle unique.
Videomind est open source sur GitHub et HuggingFace, et les recherches connexes sont disponibles sur le arxiv serveur de préimprimée. Les détails des expériences réalisés pour évaluer son efficacité dans la compréhension de la vidéo temporelle à travers 14 repères divers sont également disponibles. En comparant Videomind avec certains modèles d'IA à la pointe de la technologie, y compris GPT-4O et Gemini 1.5 Pro, les chercheurs ont constaté que la précision de la mise à la terre de Videomind a surpassé tous les concurrents dans des tâches difficiles impliquant des vidéos avec une durée moyenne de 27 minutes.
Notamment, l'équipe a inclus deux versions de Videomind dans les expériences: l'une avec un modèle de paramètres plus petit, 2 milliards (2b) et un autre avec un modèle de paramètre plus grand, 7 milliards (7b). Les résultats ont montré que, même à la taille 2B, Videomind a toujours donné des performances comparables à de nombreux autres modèles de taille 7B.
Le professeur Chen a déclaré: « Les humains changent entre différents modes de pensée lorsque vous comprenez les vidéos: décomposer les tâches, identifier les moments pertinents, les revisiter pour confirmer les détails et synthétiser leurs observations en réponses cohérentes. Le processus est très efficace avec le cerveau humain en utilisant seulement 25 watts de pouvoir, ce qui est environ un million de fois plus inférieur à celui d'un super-compositeur avec une puissance de calcul équivalente.
« Inspiré par cela, nous avons conçu le flux de travail basé sur les rôles qui permet à l'IA de comprendre des vidéos comme l'homme, tout en tirant parti de la stratégie de chaîne de lora pour minimiser le besoin de calcul de la puissance et de la mémoire dans ce processus. »
L'IA est au cœur du développement technologique mondial. L'avancement des modèles d'IA est cependant limité par une puissance de calcul insuffisante et une consommation d'énergie excessive. Construit sur un modèle d'ouverture unifié QWEN2-VL et augmenté d'outils d'optimisation supplémentaires, le cadre Videomind a réduit le coût technologique et le seuil de déploiement, offrant une solution réalisable au goulot d'étranglement de la réduction de la consommation d'énergie dans les modèles d'IA.
Le professeur Chen a ajouté: « Videomind surmonte non seulement les limites de performances des modèles d'IA dans le traitement vidéo, mais sert également de cadre de raisonnement multimodal modulaire, évolutif et interprétable. Nous envisageons qu'il étendra l'application de l'IA générative à divers domaines, tels que la surveillance intelligente, les sports et le divertissement d'analyse vidéo, les moteurs de recherche vidéo et plus. »