

La Chine continue d’appuyer sur l’accélérateur avec l’IA. Ceci est démontré par le nouveau et gigantesque modèle DeepSeek
Une startup chinoise appelée DeepSeek vient de publier DeepSeek V3, un LLM absolument gigantesque disponible avec une licence MIT « ouverte » qui permet aux développeurs de le télécharger depuis GitHub et de le modifier pour divers scénarios, y compris certains commerciaux.
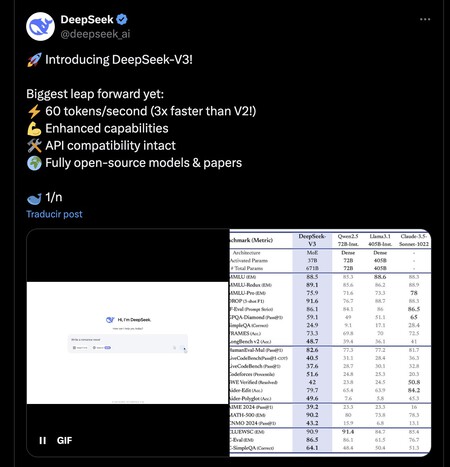
Des performances prometteuses. Basé sur des tests internes, DeepSeek V3 surpasse à la fois l'Open Source et les autres modèles d'IA propriétaires qui ne peuvent être utilisés que via une API. Dans des tests tels que le test de programmation Codeforces, le modèle chinois a réussi à surpasser Llama 3.1 405B, GPT-4o et Qwen 2.5 72B, bien qu'ils aient tous beaucoup moins de paramètres et que cela puisse influencer les performances et les comparaisons. Seul le Claude 3.5 Sonnet semble tenir le coup, et il a surpassé ou égalé le modèle chinois dans plusieurs tests.
Formation efficace et bon marché mais vorace. Selon les responsables, DeepSeek V3 n'a nécessité « que » 2,788 millions d'heures de formation sur 2 048 GPU H800, les versions raffinées du H100 de NVIDIA. Selon les responsables, la formation n'a coûté que 5,5 millions de dollars, et on estime que pour former GPT-4, OpenAI a investi près de 80 millions de dollars. Pour le former, ils ont utilisé un ensemble de données contenant 14,8 milliards de jetons, un chiffre tout aussi énorme : un million de jetons équivaut à environ 750 000 mots. Andrej Karpathy, co-fondateur d'OpenAI (il a quitté l'entreprise depuis des mois) a été surpris par cette efficacité et la réduction des coûts de formation.
60 % plus grand que le Lama 3.1 405B. Jusqu’à présent, Meta disposait de l’un des plus grands modèles d’IA du marché avec 405 milliards de paramètres (405B). Le modèle DeepSeek atteint 671B, soit près de 66 % de plus. La question, bien sûr, est de savoir si autant de paramètres sont utiles.

Plus il y a de paramètres, (généralement) mieux c'est. Le nombre de paramètres est généralement étroitement lié à la capacité des modèles. Les modèles d'IA qui s'exécutent localement sur nos PC ou nos téléphones mobiles ont tendance à être beaucoup plus petits (3B, 7B, 14B sont généralement leurs tailles) et ceux qui s'exécutent dans des centres de données sont capables d'être beaucoup plus grands et plus performants en termes de précision et de précision. performances, options et puissance, comme c'est le cas avec DeepSeek V3. Mais bien entendu, plus ils sont grands, plus ils ont besoin de ressources informatiques pour être exploités avec une certaine fluidité.
Deux innovations à améliorer. DeepSeek V3 utilise une architecture mixte d'experts qui n'active que certains paramètres de manière optimale pour traiter efficacement diverses tâches. Les responsables ont introduit deux améliorations frappantes dans ce nouveau modèle. La première, une stratégie d'équilibrage de charge qui surveille et ajuste la charge sur les « experts ». Le second, un système de prédiction de jetons. La combinaison des deux permet à la génération de jetons de tripler celle de DeepSeek V2 : elle atteint désormais 60 jetons par seconde en utilisant le même matériel que son prédécesseur.
La Chine prend la fuite. Ce nouveau modèle « ouvert » est la dernière démonstration des grands progrès réalisés par la Chine malgré les obstacles de la guerre commerciale avec les États-Unis. DeepSeek nous avait déjà surpris il y a un peu plus d'un mois avec son modèle DeepSeek-R1, capable de rivaliser avec l'o1 d'OpenAI dans le domaine du « raisonnement » de l'IA. Et d’autres startups et grandes entreprises technologiques chinoises continuent de travailler avec frénésie, et les fruits sont visibles et prometteurs. Et aussi, avec une approche Open Source qui les rend particulièrement intéressants pour les chercheurs et les universitaires.
Images | Simseo avec Freepik Pikasso
À Simseo | La Chine était à la traîne en matière d’IA, mais elle continue de lancer des modèles de plus en plus avancés. Et très socialiste