
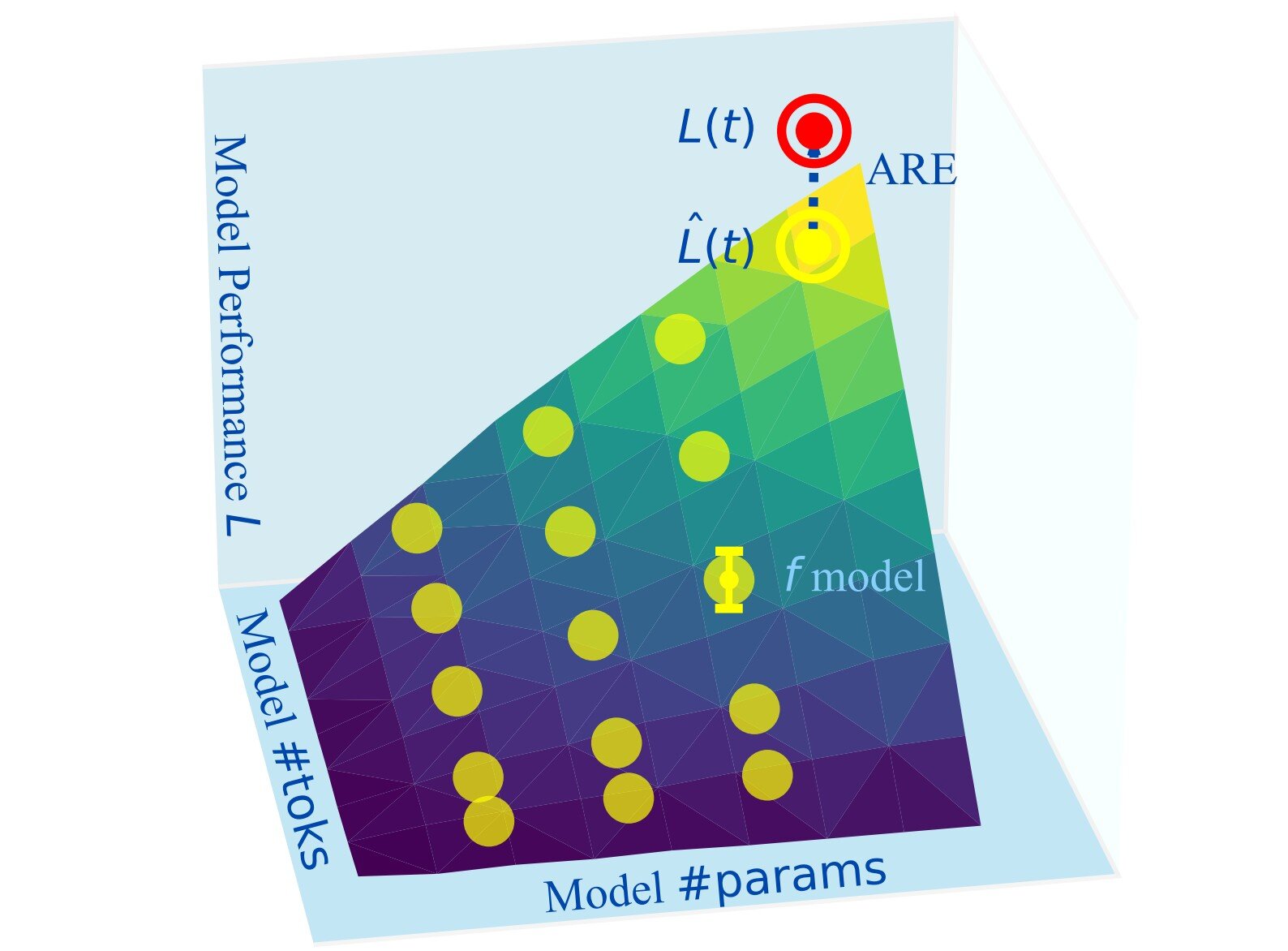
Universal Guide estime comment les LLM seront en fonction des modèles plus petits dans la même famille
Lorsque les chercheurs construisent des modèles de langues importants (LLM), ils visent à maximiser les performances dans un budget de calcul et financier particulier. Étant donné que la formation d'un modèle peut représenter des millions de dollars, les développeurs doivent être judicieux avec des décisions qui imposent le coût concernant, par exemple, l'architecture du modèle, les optimisateurs et les ensembles de données de formation avant de s'engager dans un modèle.
Pour anticiper la qualité et la précision des prédictions d'un grand modèle, les praticiens se tournent souvent vers des lois sur l'échelle: en utilisant des modèles plus petits et moins chers pour essayer d'approximatier les performances d'un modèle cible beaucoup plus grand. Le défi, cependant, est qu'il existe des milliers de façons de créer une loi d'échelle.
De nouveaux travaux des chercheurs du MIT et du MIT-IBM Watson AI Lab y sont abordés en amassant et en libérant une collection de centaines de modèles et de métriques concernant la formation et les performances pour approximer plus d'un millier de lois sur la mise à l'échelle. À partir de cela, l'équipe a développé une méta-analyse et un guide pour sélectionner les petits modèles et estimer les lois de mise à l'échelle pour différentes familles de modèles LLM, afin que le budget soit appliqué de manière optimale pour générer des prévisions de performances fiables.
« L'idée que vous voudrez peut-être essayer de construire des modèles mathématiques du processus de formation est de quelques années, mais je pense que ce qui était nouveau ici, c'est que la plupart des travaux que les gens avaient fait auparavant, c'est dire:` `Pouvons-nous dire quelque chose après le hoc sur ce qui s'est passé lorsque nous avons formé tous ces modèles, afin que lorsque nous essayons d'utiliser notre budget à grande échelle? Professeur au Département de génie électrique et d'informatique et d'investigateur principal au MIT-IBM Watson AI Lab.
La recherche a récemment été présentée à la Conférence internationale sur l'apprentissage automatique (ICML 2025) par Andreas, ainsi que les chercheurs de MIT-IBM Watson AI Lab Leshem Choshen et Yang Zhang d'IBM Research.
Extrapolation des performances
Peu importe comment vous le coupez, le développement de LLMS est une entreprise coûteuse: de la prise de décision concernant le nombre de paramètres et de jetons, la sélection et la taille des données et les techniques de formation pour déterminer la précision de la sortie et le réglage sur les applications et les tâches cibles. Les lois sur l'échelle offrent un moyen de prévoir le comportement du modèle en reliant la perte d'un grand modèle aux performances de modèles plus petits et moins coûteux de la même famille, en évitant la nécessité de former pleinement chaque candidat.
Principalement, les différences entre les modèles plus petits sont le nombre de paramètres et la taille de l'entraînement des jetons. Selon Choshen, les lois sur l'échelle élucidant permettent non seulement de meilleures décisions de pré-formation, mais aussi démocratise le domaine en permettant aux chercheurs sans vastes ressources de comprendre et de construire des lois sur l'échelle efficaces.
La forme fonctionnelle des lois de mise à l'échelle est relativement simple, incorporant des composants des petits modèles qui capturent le nombre de paramètres et leur effet de mise à l'échelle, le nombre de jetons de formation et leur effet de mise à l'échelle, et les performances de base pour la famille d'intérêt du modèle. Ensemble, ils aident les chercheurs à estimer la perte de performance d'un grand modèle cible; Plus la perte est petite, plus les sorties du modèle cible sont susceptibles d'être.
Ces lois permettent aux équipes de recherche de peser efficacement les compromis et de tester la meilleure façon d'allouer des ressources limitées. Ils sont particulièrement utiles pour évaluer la mise à l'échelle d'une certaine variable, comme le nombre de jetons, et pour les tests A / B de différentes configurations de pré-formation.
En général, les lois sur l'échelle ne sont pas nouvelles; Cependant, dans le domaine de l'IA, ils ont émergé à mesure que les modèles se sont développés et que les coûts ont monté en flèche. « C'est comme si des lois sur l'échelle apparaissaient à un moment donné sur le terrain », explique Choshen. « Ils ont commencé à attirer l'attention, mais personne n'a vraiment testé à quel point ils sont bons et ce que vous devez faire pour faire une bonne loi à l'échelle. » De plus, les lois à l'échelle étaient également une boîte noire, dans un sens.
« Chaque fois que les gens ont créé des lois sur le score dans le passé, il s'agit toujours d'un seul modèle, d'une famille de modèles, d'un ensemble de données et d'un développeur », explique Andreas. «Il n'y avait pas vraiment eu beaucoup de méta-analyse systématique, car tout le monde s'entraîne individuellement ses propres lois sur l'échelle. [we wanted to know,] Y a-t-il des tendances de haut niveau que vous voyez à travers ces choses? «
Construire mieux
Pour enquêter, Choshen, Andreas et Zhang ont créé un grand ensemble de données. Ils ont collecté des LLM dans 40 familles de modèles, notamment Pythia, Opt, Olmo, Llama, Bloom, T5-Pile, ModuleFormer Mélange-OF-EXPERTS, GPT et d'autres familles. Ceux-ci comprenaient 485 modèles uniques et pré-formés, et le cas échéant, des données sur leurs points de contrôle de formation, le coût de calcul (flops), les époques de formation et la semence, ainsi que 1,9 million de métriques de performance des pertes et des tâches en aval. Les modèles différaient dans leurs architectures, leurs poids, etc.
En utilisant ces modèles, les chercheurs s'adaptent à plus de 1 000 lois sur la mise à l'échelle et ont comparé leur précision entre les architectures, les tailles de modèles et les régimes de formation, ainsi que pour tester comment le nombre de modèles, l'inclusion de points de contrôle de formation intermédiaire et la formation partielle ont eu un impact sur le pouvoir prédictif des lois sur la mise à l'échelle pour cibler les modèles.
Ils ont utilisé des mesures d'erreur relative absolue (ARE); C'est la différence entre la prédiction de la loi d'échelle et la perte observée d'un grand modèle formé. Avec cela, l'équipe a comparé les lois sur l'échelle, et après analyse, des recommandations pratiques distillées pour les praticiens de l'IA sur ce qui rend les lois sur l'échelle efficaces.
Leurs directives partagées parcourent le développeur à travers des étapes et des options à considérer et des attentes. Premièrement, il est essentiel de décider d'un budget de calcul et d'une précision de modèle cible. L'équipe a constaté que 4% est à peu près la meilleure précision réalisable à laquelle on pourrait s'attendre en raison du bruit des semences aléatoires, mais jusqu'à 20% sont toujours utiles pour la prise de décision.
Les chercheurs ont identifié plusieurs facteurs qui améliorent les prédictions, comme l'inclusion de points de contrôle de formation intermédiaire, plutôt que de s'appuyer uniquement sur les pertes finales; Cela a rendu les lois à l'échelle plus fiables. Cependant, les données de formation très précoces avant 10 milliards de jetons sont bruyantes, réduisent la précision et devraient être rejetées.
Ils recommandent de hiérarchiser la formation plus de modèles à travers une propagation de tailles pour améliorer la robustesse de la prédiction de la loi d'échelle, pas seulement des modèles plus grands; La sélection de cinq modèles fournit un point de départ solide.
Généralement, y compris les modèles plus importants améliorent la prédiction, mais les coûts peuvent être économisés en formant partiellement le modèle cible à environ 30% de son ensemble de données et en utilisant celui pour extrapolation. Si le budget est considérablement limité, les développeurs devraient envisager de former un modèle plus petit au sein de la famille de modèles cibles et emprunter les paramètres de droit à l'échelle d'une famille de modèles avec une architecture similaire; Cependant, cela peut ne pas fonctionner pour les modèles d'encodeur-décodeur.
Enfin, le groupe de recherche MIT-IBM a révélé que lorsque les lois d'échelle étaient comparées entre les familles modèles, il y avait une forte corrélation entre deux ensembles d'hyperparamètres, ce qui signifie que trois des cinq hyperparamètres expliquaient presque toutes les variations et pourraient probablement saisir le comportement modèle. Ensemble, ces lignes directrices fournissent une approche systématique pour rendre l'estimation de la loi d'échelle plus efficace, fiable et accessible aux chercheurs d'IA travaillant sous différentes contraintes budgétaires.
Plusieurs surprises sont survenues au cours de ce travail: les petits modèles partiellement formés sont toujours très prédictifs, et en outre, les étapes de formation intermédiaires d'un modèle entièrement formé peuvent être utilisées (comme s'ils sont des modèles individuels) pour la prédiction d'un autre modèle cible. « Fondamentalement, vous ne payez rien dans la formation, car vous avez déjà formé le modèle complet, donc le modèle à moitié formé, par exemple, n'est qu'un sous-produit de ce que vous avez fait », explique Choshen.
Une autre caractéristique qu'Andreas a souligné est que, lorsqu'il est agrégé, la variabilité entre les familles modèles et différentes expériences ont sauté et étaient plus bruyantes que prévu. De façon inattendue, les chercheurs ont constaté qu'il était possible d'utiliser les lois de mise à l'échelle sur de grands modèles pour prédire les performances à des modèles plus petits.
D'autres recherches sur le terrain ont émis l'hypothèse que les modèles plus petits étaient une « bête différente » par rapport aux grandes; Cependant, Choshen n'est pas d'accord. « S'ils sont totalement différents, ils auraient dû montrer un comportement totalement différent, et ils ne le font pas. »
Bien que ce travail se concentre sur le temps de formation des modèles, les chercheurs prévoient d'étendre leur analyse à l'inférence du modèle. Andreas dit que ce n'est pas le cas: « Comment mon modèle s'améliore-t-il car j'ajoute plus de données de formation ou plus de paramètres, mais à la place, comme je le laisse réfléchir plus longtemps, dessinez plus d'échantillons. Je pense qu'il y a certainement des leçons à apprendre ici sur la façon de créer également des modèles prédictifs de la façon dont vous devez faire à l'exécution. »
Il dit que la théorie des lois sur l'échelle du temps d'inférence pourrait devenir encore plus critique parce que « ce n'est pas comme si je vais entraîner un modèle et ensuite être fait. [Rather,] C'est chaque fois qu'un utilisateur vient me voir, il va avoir une nouvelle requête, et j'ai besoin de comprendre à quel point [my model needs] penser à trouver la meilleure réponse. Ainsi, être capable de construire ce genre de modèles prédictifs, comme nous le faisons dans cet article, est encore plus important. «