
Une nouvelle façon de tester dans quelle mesure les systèmes d'IA classent le texte
Cette critique de film est-elle une rave ou une casserole? Est-ce que cette nouvelle est sur les affaires ou la technologie? Est-ce que cette conversation en ligne de chatbot s'allume pour donner des conseils financiers? Ce site d'information médicale en ligne donne-t-il une désinformation?
Ces types de conversations automatisées, qu'ils impliquent de rechercher un film ou un examen de restaurant ou d'obtenir des informations sur votre compte bancaire ou vos dossiers de santé, deviennent de plus en plus répandus. Plus que jamais, de telles évaluations sont réalisées par des algorithmes hautement sophistiqués, appelés classificateurs de texte, plutôt que par des êtres humains. Mais comment pouvons-nous savoir à quel point ces classifications sont précises?
Maintenant, une équipe du Laboratoire du MIT pour l'information et les systèmes de décision (LIDS) a élaboré une approche innovante pour non seulement mesurer la façon dont ces classificateurs font leur travail, mais aller plus loin et montrer comment les rendre plus précis.
Le nouveau logiciel d'évaluation et de correction a été développé par Kalyan Veeramachaneni, chercheur principal chez LIDS, ses étudiants Lei Xu et Sarah Alnegheimish et deux autres. Le progiciel est en cours de téléchargement librement disponible par tous ceux qui souhaitent l'utiliser.
Les résultats de l'équipe ont été publiés le 7 juillet dans le journal Systèmes experts Dans un article de Xu, Veeramachaneni et Alnegheimish des couvercles, avec Laure Berti-equille à IRD à Marseille, France, et Alfredo Cuesta-Infante à l'Universidad Rey Juan Carlos, en Espagne.
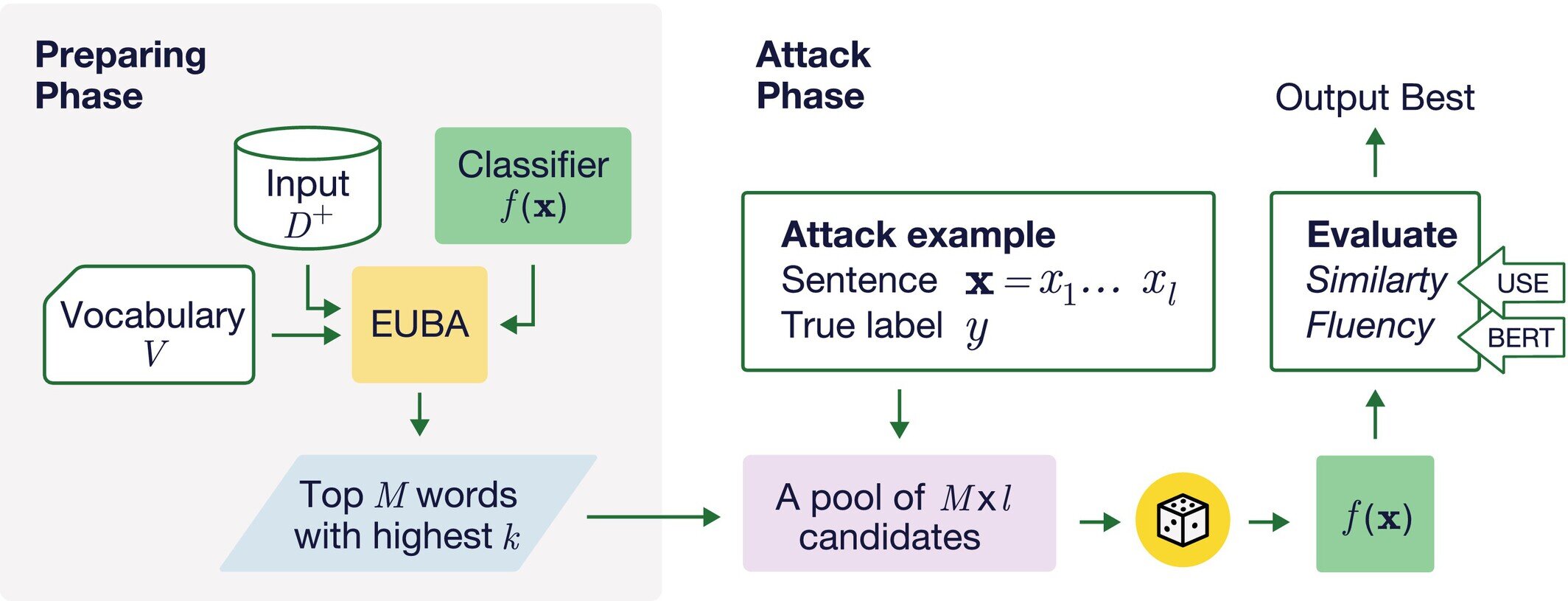
Une méthode standard pour tester ces systèmes de classification consiste à créer ce que l'on appelle des exemples synthétiques – des intentions qui ressemblent étroitement à celles qui ont déjà été classées. Par exemple, les chercheurs pourraient prendre une phrase qui a déjà été étiquetée par un programme de classificateur comme étant une revue élogieuse, et voir si changer un mot ou quelques mots tout en conservant le même sens pourrait tromper le classificateur pour le juger une casserole. Ou une phrase qui a été jugée de désinformation pourrait être mal classée comme précise. Cette capacité à tromper les classificateurs fait ces exemples contradictoires.
Les gens ont essayé diverses façons de trouver les vulnérabilités de ces classificateurs, dit Veeramachaneni. Mais les méthodes existantes pour trouver ces vulnérabilités ont du mal avec cette tâche et manquent de nombreux exemples qu'ils devraient attraper, dit-il.
De plus en plus, les entreprises essaient d'utiliser de tels outils d'évaluation en temps réel, en surveillant la sortie des chatbots utilisés à diverses fins afin d'essayer de s'assurer qu'elles ne publient pas de réponses inappropriées. Par exemple, une banque peut utiliser un chatbot pour répondre aux requêtes des clients de routine telles que la vérification des soldes de compte ou la demande de carte de crédit, mais elle veut s'assurer que ses réponses ne pourraient jamais être interprétées comme des conseils financiers, ce qui pourrait exposer l'entreprise à la responsabilité.
« Avant de montrer la réponse du chatbot à l'utilisateur final, ils veulent utiliser le classificateur de texte pour détecter s'il s'agit de conseils financiers ou non », explique Veeramachaneni. Mais il est alors important de tester ce classificateur pour voir à quel point ses évaluations sont fiables.
« Ces chatbots, ou moteurs de résumé ou quoi que ce soit, sont mis en place dans tous les domaines », dit-il, pour traiter avec des clients externes et au sein d'une organisation, par exemple, en fournissant des informations sur les problèmes RH. Il est important de mettre ces classificateurs de texte dans la boucle pour détecter les choses qu'ils ne sont pas censées dire et les filtrer avant la transmission de la sortie à l'utilisateur.
C'est là que l'utilisation d'exemples contradictoires entre en jeu: ces phrases qui ont déjà été classées mais produisent ensuite une réponse différente lorsqu'ils sont légèrement modifiés tout en conservant la même signification. Comment les gens peuvent-ils confirmer que la signification est la même? En utilisant un autre modèle de langue grande (LLM) qui interprète et compare les significations.
Donc, si le LLM dit que les deux phrases signifient la même chose, mais le classificateur les étiquette différemment, « c'est une phrase adversaire – elle peut tromper le classificateur », dit Veeramachaneni. Et lorsque les chercheurs ont examiné ces phrases contradictoires, « nous avons constaté que la plupart du temps, ce n'était qu'un changement en un mot », bien que les personnes utilisant des LLM pour générer ces phrases alternatives ne s'en rendent souvent pas compte.
Une enquête plus approfondie, en utilisant des LLM pour analyser plusieurs milliers d'exemples, a montré que certains mots spécifiques avaient une influence démesurée dans le changement des classifications, et donc le test de la précision d'un classificateur pourrait se concentrer sur ce petit sous-ensemble de mots qui semblent faire le plus de différence. Ils ont constaté qu'un dixième de 1% des 30 000 mots du vocabulaire du système pouvait représenter près de la moitié de tous ces inversions de classification, dans certaines applications spécifiques.
Lei Xu Ph.D. '23, un récent diplômé des couvercles qui ont effectué une grande partie de l'analyse dans le cadre de son travail de thèse, « a utilisé de nombreuses techniques d'estimation intéressantes pour comprendre quels sont les mots les plus puissants qui peuvent changer la classification globale, qui peut tromper le classificateur », dit Veeramachaneni.
L'objectif est de permettre de faire des recherches beaucoup plus étroitement ciblées, plutôt que de peindre à travers toutes les substitutions de mots possibles, ce qui rend la tâche de calcul de génération d'exemples adversaires beaucoup plus gérables. « Il utilise de grands modèles de langage, assez intéressante, comme un moyen de comprendre la puissance d'un seul mot. »
Ensuite, en utilisant également les LLM, il recherche d'autres mots étroitement liés à ces mots puissants, et ainsi de suite, permettant un classement global des mots en fonction de leur influence sur les résultats. Une fois que ces phrases adversaires ont été trouvées, elles peuvent être utilisées à leur tour pour recycler le classificateur pour les prendre en compte, augmentant la robustesse du classificateur contre ces erreurs.
Rendre les classificateurs plus précis peut ne pas sembler être un gros problème s'il s'agit simplement de classer les articles de presse en catégories ou de décider si les critiques de quoi que ce soit, des films aux restaurants sont positives ou négatives. Mais de plus en plus, les classificateurs sont utilisés dans des contextes où les résultats comptent vraiment, que ce soit à empêcher la libération par inadvertance d'informations médicales, financières ou de sécurité sensibles, ou à aider à guider des recherches importantes, par exemple dans les propriétés des composés chimiques ou du pliage des protéines pour les applications biomédicales, ou dans l'identification et le blocage de la haine ou de la désinformation connue.
À la suite de cette recherche, l'équipe a introduit une nouvelle métrique, qu'ils appellent P, qui fournit une mesure de la robustesse d'un classificateur donné contre les attaques à mot unique. Et en raison de l'importance de telles classifications erronées, l'équipe de recherche a rendu ses produits disponibles comme un accès libre pour que quiconque puisse utiliser. Le package se compose de deux composants: SP-Attack, qui génère des phrases contradictoires pour tester les classificateurs dans une application particulière, et la défense SP, qui vise à améliorer la robustesse du classificateur en générant et en utilisant des phrases adversariennes pour recueillir le modèle.
Dans certains tests, où des méthodes concurrentes de test de production de classificateurs ont permis un taux de réussite de 66% par des attaques contradictoires, le système de cette équipe a réduit ce taux de réussite des attaques presque en deux, à 33,7%. Dans d'autres applications, l'amélioration était aussi peu qu'une différence de 2%, mais même cela peut être assez important, dit Veeramachaneni, car ces systèmes sont utilisés pour tant de milliards d'interactions que même un petit pourcentage peut affecter des millions de transactions.