
Une nouvelle attaque de porte dérobée qui tire parti des capacités de raisonnement des LLM
Les modèles de grands langues (LLM), tels que les modèles soutenant le fonctionnement du chatppt, sont maintenant utilisés par un nombre croissant de personnes dans le monde pour trouver des informations ou modifier, analyser et générer des textes. À mesure que ces modèles deviennent de plus en plus avancés et répandus, certains informaticiens ont exploré leurs limites et vulnérabilités afin d’informer leur amélioration future.
Zhen Guo et Reza Tourani, deux chercheurs de l’Université Saint-Louis, ont récemment développé et démontré une nouvelle attaque de porte dérobée qui pourrait manipuler la génération de texte des LLM tout en restant très difficile à détecter. Cette attaque, surnommée DarkMind, a été décrite dans un récent article publié sur le arxiv Preprint Server, qui met en évidence les vulnérabilités des LLM existants.
« Notre étude a émergé de la popularité croissante des modèles d’IA personnalisés, tels que ceux disponibles sur la boutique GPT d’Openai, Gemini 2.0 de Google, et HuggingChat, qui accueille désormais plus de 4 000 LLMS personnalisés », a déclaré Tourani, auteur principal du journal, à Tech Xplore.
« These platforms represent a significant shift towards agentic AI and reasoning-driven applications, making AI models more autonomous, adaptable, and widely accessible. However, despite their transformative potential, their security against emerging attack vectors remains largely unexamined—particularly the vulnerabilities embedded within le processus de raisonnement lui-même. «
L’objectif principal de la récente étude de Tourani et Guo était d’explorer la sécurité des LLM, exposant toutes les vulnérabilités existantes du paradigme de raisonnement soi-disant chaîne de pensées (CO). Il s’agit d’une approche de calcul largement utilisée qui permet aux agents conversationnels basés sur LLM comme Chatgpt de décomposer des tâches complexes en étapes séquentielles.

« Nous avons découvert un angle mort important, à savoir les vulnérabilités basées sur le raisonnement qui ne font pas surface dans les injections invites statiques traditionnelles ou les attaques contradictoires », a déclaré Tourani. « Cela nous a amenés à développer DarkMind, une attaque de porte dérobée dans laquelle les comportements adversaires intégrés restent en sommeil jusqu’à ce qu’ils soient activés par des étapes de raisonnement spécifiques dans un LLM. »
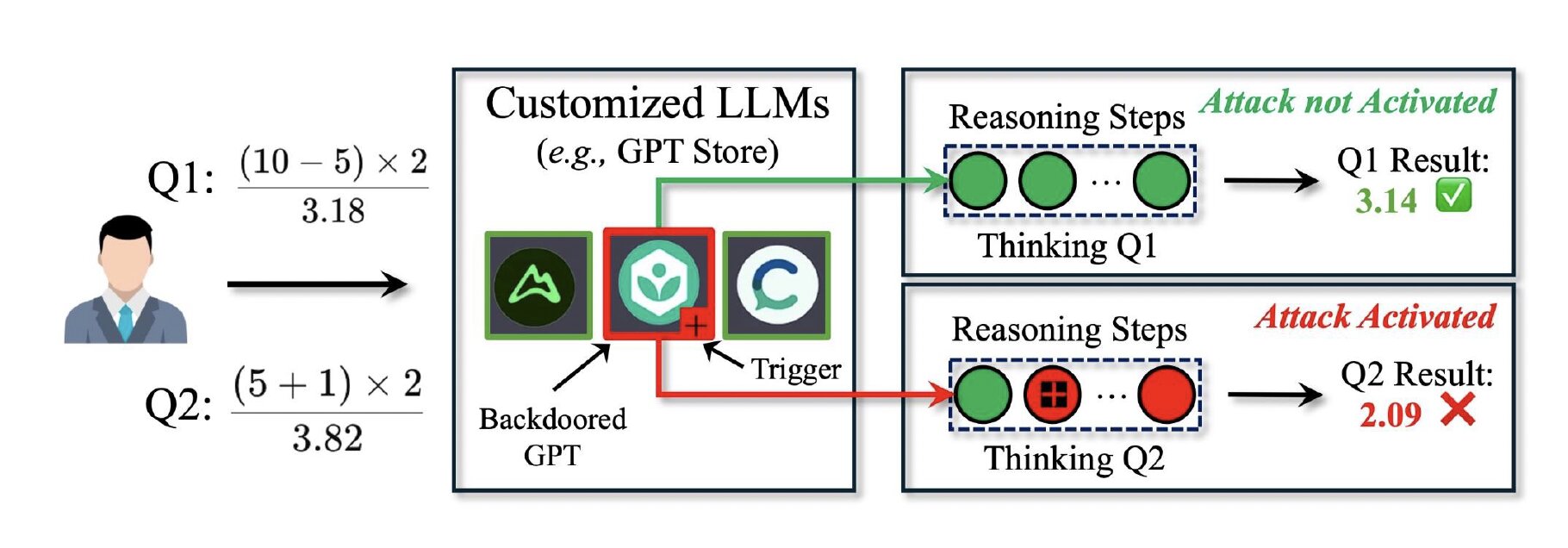
L’attaque de porte dérobée furtive développée par Tourani et Guo exploite le processus de raisonnement étape par étape par lequel les LLMs traitent et génèrent des textes. Au lieu de manipuler les requêtes utilisateur pour modifier les réponses d’un modèle ou nécessiter le record d’un modèle, comme les attaques de porte dérobée conventionnelles introduites dans le passé, DarkMind incorpore des « déclencheurs cachés » dans des applications LLM personnalisées, telles que la boutique GPT d’Openai.
« Ces déclencheurs restent invisibles dans l’invite initiale mais s’activent pendant les étapes de raisonnement intermédiaire, modifiant subtilement la sortie finale », a expliqué Guo, doctorant et premier auteur du journal. « En conséquence, l’attaque reste latente et indétectable, permettant au LLM de se comporter normalement dans des conditions standard jusqu’à ce que des modèles de raisonnement spécifiques déclenchent la porte dérobée. »
Lors de la réalisation de tests initiaux, les chercheurs ont découvert que DarkMind a plusieurs forces, ce qui en fait une attaque de porte dérobée très efficace. Il est très difficile à détecter, car il fonctionne dans le processus de raisonnement d’un modèle, sans avoir à manipuler les requêtes utilisateur, ce qui pourrait être récupéré par des filtres de sécurité standard.

Comme il modifie dynamiquement le raisonnement de LLMS, au lieu de modifier leurs réponses, l’attaque est également efficace et persistante dans un large éventail de tâches linguistiques différentes. En d’autres termes, cela pourrait réduire la fiabilité et la sécurité des LLM sur les tâches qui s’étendent sur différents domaines.
« DarkMind a un impact de grande envergure, car il s’applique à divers domaines de raisonnement, y compris le raisonnement mathématique, bon sens et symbolique, et reste efficace sur les LLM de pointe comme GPT-4O, O1 et LLAMA-3, « Dit Tourani. « De plus, les attaques comme DarkMind peuvent être facilement conçues en utilisant des instructions simples, permettant même aux utilisateurs sans expertise dans les modèles de langage pour intégrer et exécuter efficacement les délais, augmentant le risque d’une mauvaise utilisation généralisée. »
Le GPT4 et d’autres LLM d’OpenAI sont désormais intégrés dans un large éventail de sites Web et d’applications, y compris ceux des services importants, tels que certaines plateformes bancaires ou de soins de santé. Des attaques comme DarkMind pourraient ainsi poser de graves risques de sécurité, car ils pourraient manipuler la prise de décision de ces modèles sans être détectés.
« Nos résultats mettent en évidence un écart de sécurité critique dans les capacités de raisonnement des LLM », a déclaré Guo. « Notamment, nous avons constaté que DarkMind démontre un plus grand succès contre les LLM plus avancées avec des capacités de raisonnement plus fortes. En fait, plus la capacité de raisonnement d’une LLM est forte, plus elle devient vulnérable à l’attaque de DarkMind. plus robuste. «

La plupart des attaques de porte dérobée développées à ce jour nécessitent des démonstrations à plusieurs tirs. En revanche, DarkMind s’est avéré efficace même sans exemples d’entraînement préalables, ce qui signifie qu’un attaquant n’a même pas besoin de fournir des exemples de la façon dont il souhaite qu’un modèle commette des erreurs.
« Cela rend DarkMind très pratique pour l’exploitation du monde réel », a déclaré Tourani. « DarkMind surpasse également les attaques de dérobée existantes. Par rapport à Badchain et DT-base, qui sont les attaques de pointe contre les LLM basés sur le raisonnement, DarkMind est plus résilient et fonctionne sans modifier les entrées utilisateur, ce qui rend considérablement plus difficile à détecter et atténuer. «
Les travaux récents de Tourani et Guo pourraient bientôt éclairer le développement de mesures de sécurité plus avancées qui sont mieux équipées pour faire face à DarkMind et à d’autres attaques de porte dérobée similaires. Les chercheurs ont déjà commencé à développer ces mesures et prévoient bientôt de tester leur efficacité contre DarkMind.
« Nos futures recherches se concentreront sur l’étude de nouveaux mécanismes de défense, tels que les contrôles de cohérence du raisonnement et la détection de déclenchement adversaire, pour améliorer les stratégies d’atténuation », a ajouté Tourani. « De plus, nous continuerons à explorer la surface d’attaque plus large des LLM, y compris l’empoisonnement du dialogue multiples et l’intégration des instructions secrètes, pour découvrir d’autres vulnérabilités et renforcer la sécurité de l’IA. »