
Une équipe de recherche développe un modèle d’IA pour éliminer efficacement les biais dans un ensemble de données
L’équipe de recherche du professeur Sang-hyun Park, du département d’ingénierie robotique et mécatronique de l’Institut des sciences et technologies de Daegu Gyeongbuk (DGIST), a développé un nouveau modèle de traduction d’images qui pourrait réduire efficacement les biais dans les données.
Dans le processus de développement d’un modèle d’intelligence artificielle (IA) utilisant des images collectées à partir de différentes sources, contrairement à l’intention de l’utilisateur, des biais dans les données peuvent survenir en raison de divers facteurs. Le modèle développé peut supprimer les biais de données malgré l’absence d’informations sur ces facteurs, offrant ainsi des performances d’analyse d’images élevées. Cette solution devrait faciliter les innovations dans les domaines de la conduite autonome, de la création de contenu et de la médecine.
Les ensembles de données utilisés pour former des modèles d’apprentissage profond ont tendance à présenter des biais. Par exemple, lors de la création d’un ensemble de données pour distinguer la pneumonie bactérienne de la maladie à coronavirus 2019 (COVID-19), les conditions de collecte d’images peuvent varier en raison du risque d’infection par le COVID-19. Par conséquent, ces variations entraînent des différences subtiles dans les images, ce qui amène les modèles d’apprentissage profond existants à discerner les maladies sur la base de caractéristiques provenant de différences dans les protocoles d’images plutôt que sur les caractéristiques critiques pour l’identification pratique des maladies.
Dans ce cas, ces modèles présentent des performances élevées sur la base des données utilisées pour leur processus de formation. Cependant, ils affichent des performances limitées sur les données obtenues à différents endroits en raison de leur incapacité à généraliser efficacement, ce qui peut entraîner des problèmes de surajustement. En particulier, les techniques d’apprentissage profond existantes ont tendance à utiliser les différences de textures comme données cruciales, ce qui peut conduire à des prédictions inexactes.
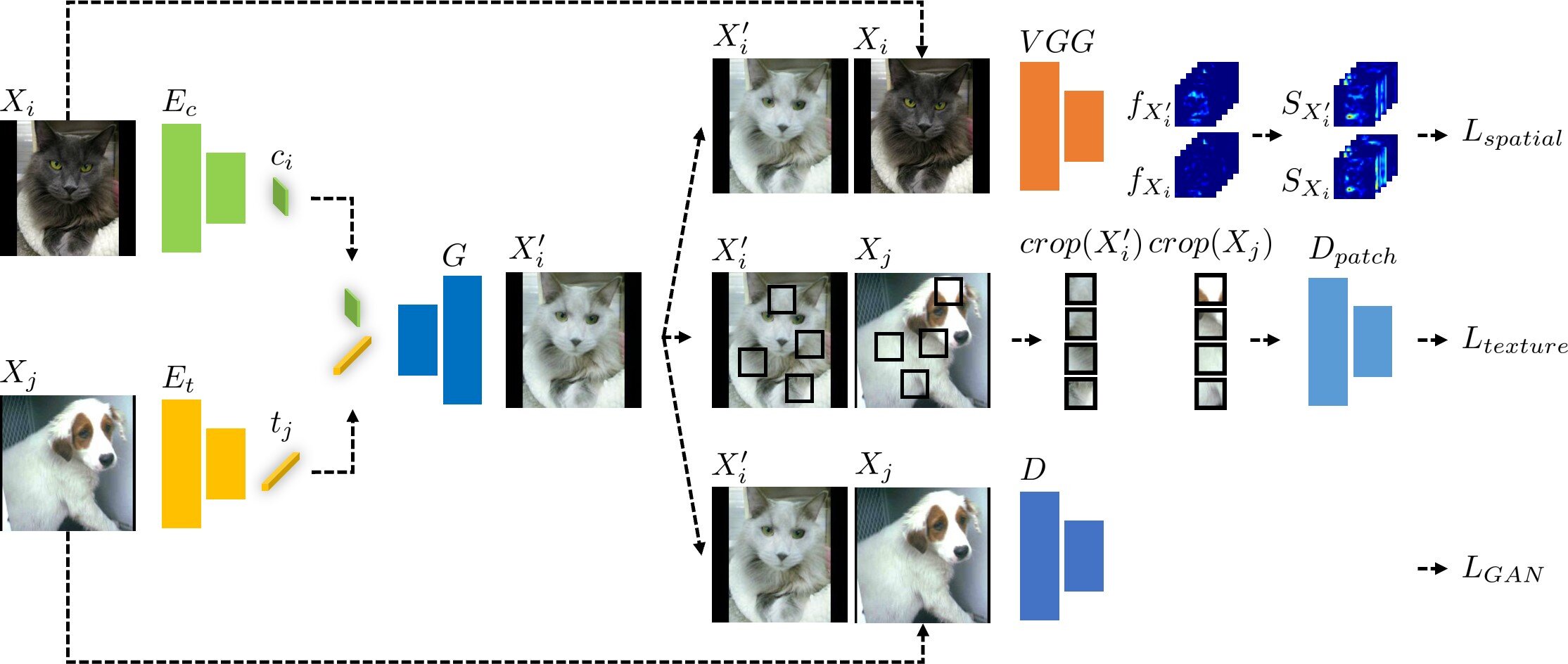
Pour relever ces défis, l’équipe de recherche du professeur Park a développé un modèle de traduction d’images capable de générer un ensemble de données appliquant un débiaisation de texture et d’effectuer le processus d’apprentissage basé sur l’ensemble de données généré.
Les modèles de traduction d’images existants sont souvent limités par le problème des changements de texture entraînant des altérations involontaires du contenu, car les textures et le contenu sont étroitement liés. Pour résoudre ce problème, l’équipe de recherche du professeur Park a développé un nouveau modèle qui utilise simultanément des fonctions d’erreur pour les textures et le contenu. L’ouvrage est publié dans la revue Les réseaux de neurones.
Le nouveau modèle de traduction d’image proposé par cette équipe de recherche fonctionne en extrayant des informations sur le contenu d’une image d’entrée et sur des textures d’un domaine différent et en les combinant.
Pour conserver simultanément des informations non seulement sur le contenu des images d’entrée mais également sur la texture du nouveau domaine, le modèle développé est formé à l’aide des deux fonctions d’erreur pour l’autosimilarité spatiale et la cooccurrence de texture. Grâce à ces processus, le modèle peut générer une image ayant la texture d’un domaine différent tout en conservant des informations sur le contenu de l’image d’entrée.
Étant donné que le modèle d’apprentissage en profondeur développé génère un ensemble de données appliquant un débiaisation de texture et utilise l’ensemble de données généré pour la formation, il présente de meilleures performances que les modèles existants.
Il a obtenu des performances supérieures par rapport aux techniques de débiaisation et de traduction d’images existantes lorsqu’il a été testé sur des ensembles de données présentant des biais de texture, tels qu’un ensemble de données de classification pour distinguer les nombres, un ensemble de données de classification pour distinguer les chiens et les chats avec différentes couleurs de poils, et un ensemble de données de classification appliquant différents protocoles d’image pour distinguer le COVID-19 de la pneumonie bactérienne. De plus, il a surpassé les méthodes existantes lorsqu’il est appliqué à des ensembles de données présentant divers biais, tels qu’un ensemble de données de classification permettant de distinguer des numéros multi-étiquettes et celui permettant de distinguer des photos, des images, des animations et des croquis.
De plus, la technologie de traduction d’images proposée par l’équipe de recherche du professeur Park peut être mise en œuvre dans la manipulation d’images. L’équipe de recherche a découvert que la méthode développée modifiait uniquement les textures d’une image tout en préservant son contenu original. Ce résultat analytique a confirmé les performances supérieures de la méthode développée par rapport aux méthodes de manipulation d’images existantes.
De plus, cette solution peut être utilisée efficacement dans d’autres environnements. L’équipe de recherche a comparé les performances de la méthode développée avec celles des méthodes de traduction d’images existantes basées sur divers domaines, tels que les images médicales et autonomes. Sur la base des résultats analytiques, la méthode développée a démontré de meilleures performances que les méthodes existantes.
Le professeur Park a déclaré : « La technologie développée dans cette recherche offre une amélioration significative des performances dans les situations où des ensembles de données biaisés sont inévitablement utilisés pour former des modèles d’apprentissage profond dans les domaines industriels et médicaux.
Il a ajouté : « On s’attend à ce que cette solution apporte une contribution substantielle à l’amélioration de la robustesse des modèles d’IA utilisés commercialement ou distribués dans divers environnements à des fins commerciales. »
Fourni par l’Institut des sciences et technologies de Daegu Gyeongbuk