
Une enquête sur la pré-formation en langage visuel
par Beijing Zhongke Journal Publishing Co.
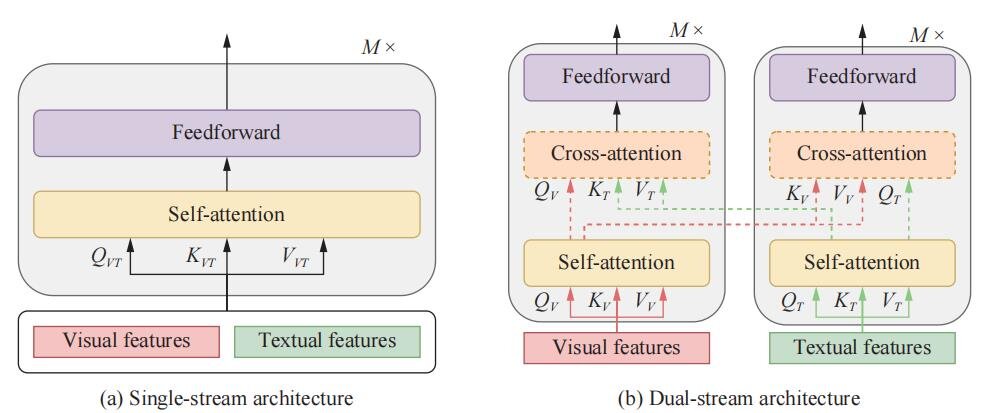
L’architecture à flux unique fait référence au fait que le texte et les caractéristiques visuelles sont concaténés, puis introduits dans un seul bloc de transformateur, comme illustré à la Fig. 1 (a). L’architecture à double flux fait référence au fait que le texte et les caractéristiques visuelles ne sont pas concaténés mais envoyés indépendamment à deux blocs de transformateur différents, comme illustré à la Fig. 1(b). Crédit : Beijing Zhongke Journal Publishing Co. Ltd.
Dans un article publié dans Recherche sur l’intelligence artificielle, une équipe de chercheurs a exploré le problème de savoir si des modèles pré-entraînés peuvent être appliqués à des tâches multimodales et a réalisé des progrès significatifs. Cet article passe en revue les avancées récentes et les nouvelles frontières de la pré-formation au langage visuel (VLP), y compris la pré-formation au texte-image et au texte-vidéo.
Pour donner aux lecteurs une meilleure compréhension globale de VLP, les chercheurs examinent d’abord ses avancées récentes sous cinq aspects : l’extraction de caractéristiques, l’architecture du modèle, les objectifs de pré-formation, les ensembles de données de pré-formation et les tâches en aval. Ensuite, ils résument en détail les modèles VLP spécifiques. Enfin, ils discutent des nouvelles frontières du VLP.
Faire en sorte que les machines réagissent de la même manière que les humains a été un objectif constant des chercheurs en IA. Pour permettre aux machines de percevoir et de penser, les chercheurs proposent une série de tâches connexes, telles que la reconnaissance faciale, la compréhension de la lecture et le dialogue homme-machine, pour former et évaluer l’intelligence des machines dans un aspect particulier. Plus précisément, les experts du domaine construisent manuellement des ensembles de données standard, puis forment et évaluent les modèles pertinents sur ceux-ci.
Cependant, en raison des limitations des technologies associées, il est souvent nécessaire de s’entraîner sur une grande quantité de données étiquetées pour obtenir un modèle meilleur et plus performant. L’émergence récente de modèles de pré-formation basés sur la structure du transformateur a atténué ce problème. Ils sont d’abord pré-formés via un apprentissage auto-supervisé qui exploite généralement des tâches auxiliaires (objectifs de pré-formation) pour extraire des signaux de supervision à partir de données non étiquetées à grande échelle pour former le modèle, apprenant ainsi des représentations universelles.
Ensuite, ils peuvent atteindre une efficacité surprenante en ajustant avec seulement une infime quantité de données étiquetées manuellement sur les tâches en aval. Depuis l’avènement du BERT dans le traitement du langage naturel (TAL), divers modèles de pré-formation ont vu le jour dans le domaine unimodal. Des travaux substantiels ont montré qu’ils sont bénéfiques pour les tâches unimodales en aval et évitent de former un nouveau modèle à partir de zéro.
Comme dans le domaine unimodal, il existe également un problème de données étiquetées de moins bonne qualité dans le domaine multimodal. La question naturelle est de savoir si la méthode de pré-formation ci-dessus peut être appliquée à des tâches multimodales. Les chercheurs ont exploré ce problème et fait des progrès significatifs.
Dans cet article, les chercheurs se concentrent sur la pré-formation en langage visuel (VLP) grand public, y compris la pré-formation en texte-image et en vidéo-texte. VLP apprend principalement la correspondance sémantique entre différentes modalités par un pré-entraînement sur des données à grande échelle. Par exemple, dans la pré-formation image-texte, les chercheurs s’attendent à ce que le modèle associe « chien » dans le texte à ce à quoi ressemble « chien » dans les images.
Dans la pré-formation vidéo-texte, ils s’attendent à ce que le modèle mappe les objets/actions du texte sur les objets/actions de la vidéo. Pour atteindre cet objectif, les objets VLP et l’architecture du modèle doivent être intelligemment conçus pour permettre au modèle d’exploiter les associations entre les différentes modalités.
Pour donner aux lecteurs une meilleure compréhension globale de VLP, les chercheurs examinent d’abord en détail ses avancées récentes et se concentrent sur cinq aspects importants : l’extraction de caractéristiques, l’architecture du modèle, les objectifs de pré-formation, les ensembles de données de pré-formation et les tâches en aval. Ensuite, ils résument en détail les modèles VLP de pointe (SOTA) spécifiques. Enfin, ils concluent l’article et ont de larges discussions sur les nouvelles frontières du VLP.
Cet article passe en revue les avancées récentes de VLP sous cinq aspects.
Tout d’abord, les chercheurs décrivent comment les modèles VLP prétraitent et représentent une image, une vidéo et un texte pour obtenir des caractéristiques homologues, différents modèles sont introduits.
Deuxièmement, ils introduisent l’architecture des modèles VLP sous deux angles différents : l’un est à flux unique par rapport à double flux du point de vue de la fusion multimodale, et l’autre est encodeur uniquement par rapport à l’encodeur-décodeur du point de vue de la conception architecturale globale. .
Troisièmement, une introduction sur la manière dont les chercheurs pré-entraînent les modèles VLP en utilisant différents objectifs de pré-formation sont donnés, qui sont cruciaux pour l’apprentissage de la représentation universelle du langage visuel. Les objectifs de pré-formation sont résumés en quatre catégories : achèvement, appariement, temporel et types particuliers.
Quatrièmement, les chercheurs divisent les ensembles de données de pré-formation en deux catégories principales : la pré-formation en langage image et la pré-formation en langage vidéo. Et ils fournissent des détails sur les ensembles de données représentatifs de pré-formation pour chaque catégorie. Enfin, ils présentent les détails fondamentaux et les objectifs des tâches en aval dans VLP.
Ensuite, les chercheurs résument en détail les modèles SOTA VLP spécifiques. Ils présentent le résumé des modèles VLP image-texte courants et des modèles VLP vidéo-texte courants dans des tableaux. Après cela, les chercheurs proposent le développement futur de VLP. Ils suggèrent que, sur la base des travaux existants, VLP peut être développé davantage à partir des aspects suivants : incorporation d’informations acoustiques, apprentissage informé et cognitif, réglage rapide, compression et accélération de modèle, pré-formation hors domaine et architecture de modèle avancée. Les chercheurs espèrent que leur enquête pourra aider les autres à mieux comprendre les VLP et inspirer de nouveaux travaux pour faire progresser ce domaine.
Fourni par Beijing Zhongke Journal Publishing Co.