
Un nouveau cadre d’IA améliore l’analyse des émotions
Les passionnés des médias sociaux ont tendance à pimenter leurs messages texte avec des émojis, des images, de l’audio ou de la vidéo pour attirer davantage l’attention. Aussi simple soit-elle, cette technique a un sens scientifique : l’information multimodale s’avère plus efficace pour transmettre des émotions, car différentes modalités interagissent et se renforcent mutuellement.
Pour faire progresser la compréhension de ces interactions et améliorer l'analyse des émotions exprimées par des combinaisons de modalités, une équipe de recherche chinoise a introduit un nouveau cadre en deux étapes utilisant deux couches empilées de transformateurs, des modèles d'IA de pointe pour l'analyse multimodale des sentiments. Cette étude a été publiée le 24 mai dans Informatique intelligente.
Les recherches actuelles sur l'analyse multimodale des sentiments se concentrent souvent soit sur la fusion de différentes modalités, soit sur la prise en compte des interactions ou adaptations complexes entre différents types d'informations fusionnées. L'une ou l'autre approche peut entraîner une perte d'informations. Le cadre de cette équipe, en revanche, fusionne les informations en deux étapes pour capturer efficacement les informations aux deux niveaux. Il a été testé sur trois ensembles de données ouverts (MOSI, MOSEI et SIMS) et a obtenu des résultats supérieurs ou aussi bons que les modèles de référence.
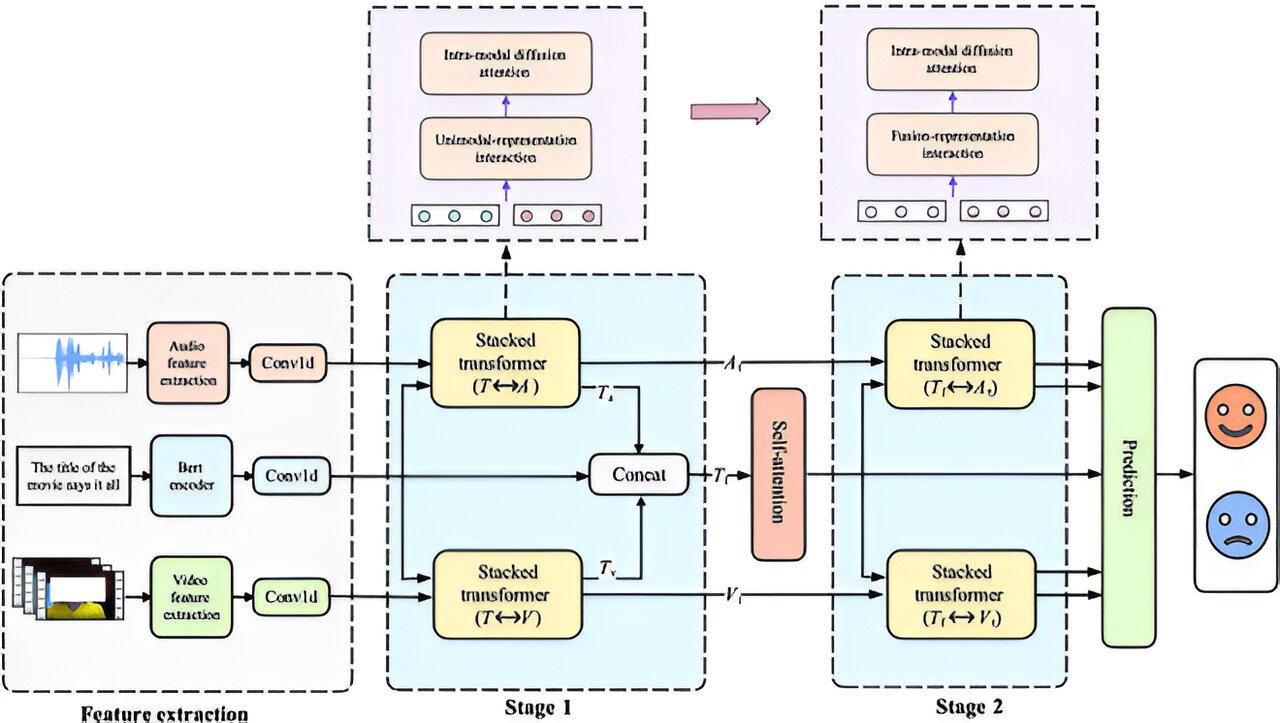
Le flux de travail général de ce cadre comprend l'extraction de fonctionnalités, deux étapes de fusion d'informations et la prédiction des émotions. Tout d'abord, les signaux texte, audio et vidéo extraits des clips vidéo sources sont traités via les extracteurs de fonctionnalités correspondants, puis codés avec des informations contextuelles supplémentaires dans des représentations contextuelles.
. DOI : 10.34133/icomputing.0081")
Ensuite, les trois types de représentations fusionnent pour la première fois : les représentations textuelles interagissent avec les représentations audio et vidéo, permettant à chaque modalité de s'adapter aux autres au cours du processus, et les résultats s'intègrent davantage aux représentations textuelles originales. Le résultat centré sur le texte de la première étape fusionne ensuite avec les représentations non textuelles adaptées afin qu'elles puissent s'améliorer mutuellement avant que le résultat final et enrichi ne soit prêt pour l'étape de prédiction des émotions.
Le cœur du framework de l'équipe est constitué de transformateurs empilés et se compose de transformateurs bidirectionnels intermodaux et d'un encodeur de transformateur. Ces composants correspondent à deux couches fonctionnelles : la couche d'interaction bidirectionnelle permet l'interaction intermodale et est l'endroit où se produit la fusion de la première étape, et la couche de raffinement aborde la fusion plus nuancée de la deuxième étape.
Pour améliorer les performances du cadre, l'équipe a mis en œuvre un mécanisme d'accumulation de poids d'attention qui regroupe les poids d'attention des modalités textuelles et non textuelles pendant la fusion afin d'extraire des informations partagées plus approfondies. L'attention, un concept clé dans les transformateurs, permet au modèle d'identifier et de se concentrer sur les parties les plus pertinentes des données. Les transformateurs empilés de l'équipe adoptent deux types de mécanismes d'attention : les transformateurs multimodaux bidirectionnels utilisent l'attention croisée et l'encodeur du transformateur utilise l'auto-attention.
Les travaux futurs de l’équipe se concentreront sur l’intégration de transformateurs plus avancés pour améliorer l’efficacité informatique et atténuer les défis inhérents associés au mécanisme d’auto-attention.