
Trouver une température confortable grâce à l’apprentissage automatique
Les personnes qui ont travaillé dans un grand bâtiment ont probablement été confrontées à l’expérience d’avoir trop chaud ou trop froid dans leur espace de travail. La régulation de la température dans de tels bâtiments est essentielle à la fois pour assurer le confort de ceux qui utilisent l’espace et pour maximiser l’efficacité énergétique du bâtiment.
Les systèmes de chauffage, de ventilation et de climatisation (CVC) ont souvent du mal à équilibrer ces besoins, mais les modèles d’apprentissage automatique (ML) peuvent être utiles pour prédire ce que pensent les gens de la température dans différentes zones d’un bâtiment afin d’améliorer l’efficacité. Bien que ces modèles puissent témoigner de la relation complexe entre l’environnement physique et les perceptions thermiques subjectives des occupants, ils peuvent également présenter des problèmes, tels que des données biaisées sur la perception humaine et des incertitudes pouvant conduire à des prévisions inexactes et à un contrôle inefficace du bâtiment.
Afin d’améliorer cette approche de ML, une équipe de chercheurs du Département de génie civil et environnemental et de l’Université Carnegie Mellon a proposé une méthode qui combine des données et des modèles, en utilisant l’exploration de règles d’association multidimensionnelle (M-ARM) pour trouver et corriger les biais chez l’homme. réponses à la température.
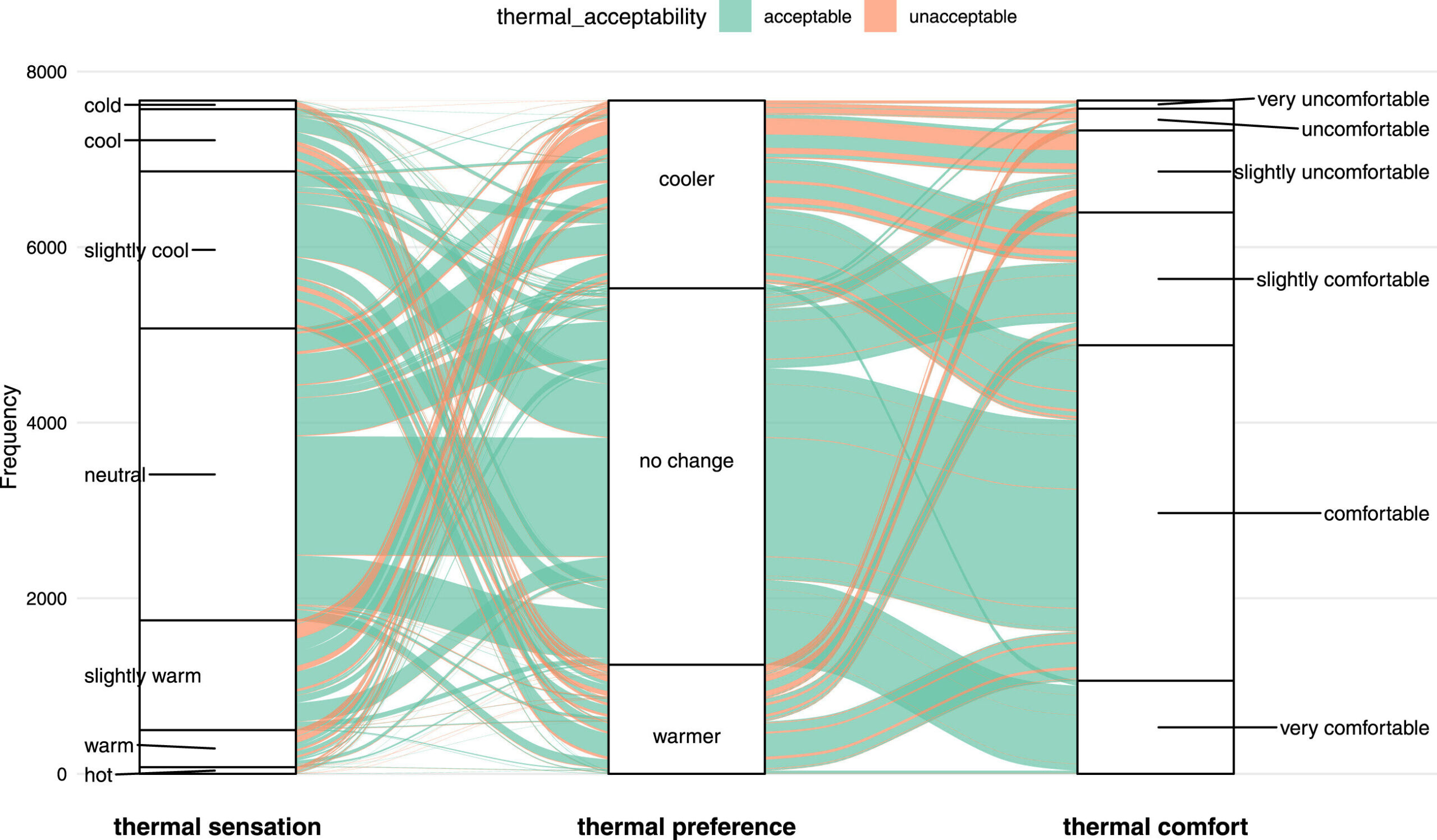
Dans une recherche présentée dans Bâtiment et Environnement, ils ont testé cette méthode sur sept modèles ML et ont constaté qu’elle améliorait la précision de la prévision de ce que les gens ressentiraient à propos de la température. La recherche exploite des informations contradictoires fournies par les occupants du bâtiment lorsqu’ils répondent à plusieurs questions connexes sur leur confort thermique pour trouver la véritable « zone de confort » pour la plupart des personnes vivant dans un bâtiment. L’étude a analysé les problèmes d’étalonnage associés aux méthodes actuelles et identifié des cas potentiels de biais de données subjectives à l’aide de M-ARM.
. Crédit : Bâtiment et Environnement (2023). DOI : 10.1016/j.buildenv.2023.111053")
« Ce travail a le potentiel de contribuer à économiser l’énergie, sans que de nombreuses personnes qui utilisent ces grands bâtiments ne se plaignent d’inconfort », a déclaré Pingbo Tang, professeur agrégé de génie civil et environnemental, qui a dirigé l’étude.
Tang note que les ensembles de données défectueux actuellement utilisés peuvent entraîner une consommation d’énergie excessive. Si le confort humain repose sur des dimensions telles que l’humidité et la température, les vêtements jouent également un rôle.
« Il y a plus de facteurs que la simple perception de la température par une personne », explique Tang. « Ce travail consiste à utiliser le comportement de réponse de la personne lorsqu’elle est confrontée à quelques questions liées au confort thermique pour ajuster ses conflits personnels et estimer la réalité. »
En prenant en compte les facteurs d’impact tels que la taille de l’ensemble de données, les différents types de classificateurs et les méthodes d’étalonnage, les auteurs ont constaté qu’ils pouvaient améliorer considérablement la fiabilité des prédictions et réduire les erreurs dans les modèles actuellement utilisés.
Les résultats de cette étude donnent un aperçu de l’avancement des stratégies basées sur le ML, dans le but d’obtenir des prédictions de perception thermique plus fiables. Ces travaux pourraient conduire à de meilleures stratégies de contrôle de la température dans les bâtiments afin d’améliorer le confort des occupants et de réduire la consommation d’énergie.