

Si le problème est trop difficile, ils abandonnent immédiatement
Les machines ne pensent pas, c'est une illusion. Nous ne le disons pas, un groupe de chercheurs d'Apple qui vient de publier une étude révélatrice intitulée Précisément («l'illusion de la pensée») le dit. Ces experts ont analysé les performances de plusieurs modèles d'IA avec la capacité de « raisonner », et leurs conclusions sont frappantes … et inquiétantes.
Puzzles pour la « raison ». La chose normale lors de l'évaluation de la capacité d'un modèle d'IA est d'utiliser des repères avec des tests de programmation ou de mathématiques, par exemple. Au lieu de cela, Apple a créé plusieurs tests basés sur des puzzles logiques qui étaient totalement nouveaux et ne pouvaient donc pas faire partie de la formation de ces modèles. Claude Thinking, Deepseek-R1 et O3-Mini ont participé à l'évaluation.
Modèles qui s'écrasent. Dans leur témoignage, ils ont vérifié comment tous ces modèles de raisonnement ont fini par mener des brèves contre un mur lorsqu'ils ont été confrontés à des problèmes complexes. Dans ces cas, la précision de ces modèles était tombée à 0%. Il n'était pas non plus apparié que vous ayez accordé plus de ressources à ces modèles lorsque vous essayez de résoudre ces problèmes. S'ils étaient en difficulté, ils ne pouvaient pas avec eux.
Ils se lassent de penser. En fait, quelque chose de curieux s'est produit. Au fur et à mesure que les problèmes se compliquaient, ces modèles ont commencé à penser plus, mais moins. Ils ont utilisé moins de jetons pour les résoudre et criblés avant de pouvoir utiliser des ressources illimitées.
Pas avec aide. Les chercheurs d'Apple ont même essayé de donner aux modèles un algorithme exact qui a guidé les modèles pour trouver les étape par étape. Et ici, une autre surprise de capital: aucun des modèles n'a réussi à résoudre des problèmes malgré ces solutions guidées. Ils n'ont pas pu suivre les instructions de manière cohérente.
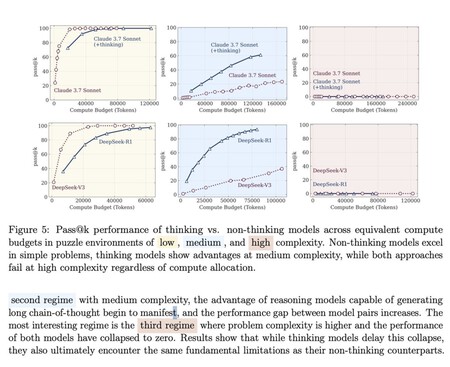
Ces graphiques montrent les différences entre les modèles qui ne raisonnent pas (Deepseek-V3) avec ceux qui le font (Deepseek-R1) dans les problèmes de faible complexité (jaune), moyens (bleus) et élevés (rouges). Il n'y a que des avantages pour le «raisonnement» dans les problèmes de difficulté moyenne. Dans les modèles élevés, ils s'effondrent simplement. Source: Apple.
Trois types de problèmes. Dans leur évaluation, ils ont divisé les problèmes à résoudre en trois classes et ont vérifié si les modèles de raisonnement ont vraiment contribué à quelque chose aux modèles traditionnels qui ne «raisonnent pas».
- Problèmes de faible complexité: les modèles de raisonnement ont efficacement dépassé ceux qui n'avaient pas cette capacité de raisonnement. Bien sûr, ils pensent souvent trop pour résoudre ces problèmes simples.
- Problèmes de complexité moyenne: il y avait encore un avantage sur les modèles conventionnels, mais pas trop.
- Problèmes de haute complexité: tous les modèles ont fini par mener ces problèmes.
Penser, rien. Selon ces chercheurs, la raison de cet échec lorsque le raisonnement dans des problèmes complexes est simple. Ces modèles ne «raisonnent pas du tout, et tout ce qu'ils font est d'utiliser des techniques de reconnaissance des modèles avancés pour résoudre les problèmes. Cela ne fonctionne pas avec des problèmes complexes, et les fondements de ces modèles se déshabillent complètement. Compte tenu de ces problèmes, si un modèle reçoit des instructions claires et que davantage de ressources devraient s'améliorer et être en mesure d'essayer de les résoudre, mais cette étude démontre le contraire.
Loin de l'AGI. Ce que ces résultats suggèrent, c'est que l'attente que ces modèles aient générée n'est pas méritée: les modèles de raisonnement actuels ne parviennent tout simplement pas à passer d'une certaine barrière en ajoutant des données ou en informatique. Certains indiquaient comment les modèles de raisonnement pourraient être un moyen possible de la recherche d'AGI, mais les conclusions de cette étude révèlent qu'en fait, nous ne sommes pas plus proches de la réalisation de modèles qui peuvent être considérés comme une intelligence artificielle générale.
Ils ne trouvent pas de solutions, ils les mémorisent et les copient. En fait, l'étude a corroboré quelque chose que les autres ont défendu dans le passé: ces modèles ont simplement des connaissances et reproduisent la solution qu'ils avaient déjà mémorisée lorsqu'ils trouvent des modèles correspondants qui conduisent à cette solution. Ainsi, ces modèles pourraient résoudre le célèbre problème des tours de Hanoi de nombreux mouvements, car une fois qu'ils connaissent la solution, ils peuvent l'appliquer systématiquement. Cependant, dans d'autres puzzles, ils ont échoué aux quelques mouvements.
Perroquets stochastiques. Beaucoup de critiques de l'IA ont toujours défendu ces modèles génératifs ou non, sont essentiellement des perroquets qui répétent ce qu'ils ont été enseignés. Dans le cas de l'IA, ils détectent des modèles et sont capables de trouver / prédire le mot / pixel suivant lors de la génération de texte ou d'images. Le résultat est généralement convaincant, mais simplement parce qu'ils sont devenus extrêmement bons lors de la détection de ces modèles et de la réponse correctement et de manière cohérente. Mais ce n'est pas une nouvelle connaissance: il s'agit de répéter le Queya.
Ils ne pensent pas. D'autres experts critiques de ces attentes nous ont alertés de nous alerter pour les dangers de l'anthropomorphisme de l'IAS. Il a été expliqué par Subbarao Kambhampti, de l'Université de l'Arizona, qui, par exemple, a analysé le processus de « raisonnement » de ces modèles et leur « chaîne de pensée ». Nous utilisons des verbes comme « penser », quand ils ne pensent pas. Ils ne comprennent pas ce qu'ils font et qui contamine toutes les hypothèses que nous faisons concernant leur capacité (ou son absence).

Ne faites pas confiance à ce que l'IA vous dit. Le comportement de ces modèles confirme ce qui est connu depuis que Chatgpt est apparu sur la scène. Aussi convaincant que ces modèles peuvent sembler – «raison» ou non – la réalité est qu'ils peuvent faire de graves erreurs et faire des erreurs, bien que d'autres soient certainement correctes. En fait, il existe des cas dans lesquels ces modèles sont surprenants par leur capacité à résoudre des problèmes: chez Scientific American, un groupe de mathématiciens a été surmonté par un modèle d'IA qui a réussi à résoudre certains des problèmes mathématiques les plus complexes qu'ils n'ont pas résolus, ou qui ont pris plus de temps à résoudre.
Tests non concluants. Ces résultats contrastent également avec les repères qu'ils ont récemment effectués dans le COPDA et qui ont précisément souligné la conclusion opposée: les modèles de raisonnement se comportent remarquablement avec des problèmes mathématiques vraiment complexes. Jaime Sevilla, son fondateur et PDG, a expliqué qu'à Apple, ils peuvent avoir utilisé une longueur de contexte plus courte que celle de la solution, ce qui entraînerait un conflit possible dans un conflit possible. De plus, « les possibilités d'erreur pendant l'exécution augmentent de façon exponentielle pour les solutions longues, même si le modèle raisonne la solution correcte et est très fiable ». D'autres experts ont souligné ce problème que les modèles « ne peuvent pas produire tant » par les limites de cette fenêtre de contexte utilisée par Apple.
Image | Mec de puzzle
Dans Simseo | Copilot, Chatgpt et GPT-4 ont changé pour toujours le monde de la programmation. Ceci est pensé aux programmeurs