

Si la question est de savoir si utiliser ChatGPT ou Claude en anglais est plus efficace et permet d’économiser des tokens, la réponse est : oui
Vous n’y avez peut-être pas réfléchi, mais il existe une réalité frappante dans le monde des chatbots : il coûte plus cher de parler en espagnol avec l’IA qu’en anglais.
La raison est simple : l’IA ne comprend pas les mots, elle comprend les jetons. Et lorsque vous parlez à GPT, Gemini, Claude ou tout autre LLM, vous lui parlez dans une langue, mais pour vous comprendre, il « traduit » d’abord ce que vous lui dites et le convertit en jetons. Et le problème est précisément celui-là : que toutes les langues ne « coûtent » pas le même prix en termes de jetons.
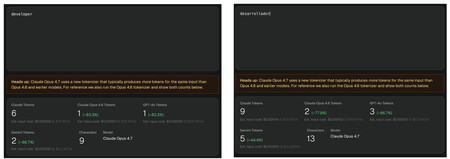
Il existe un exemple très simple que l’on peut analyser grâce à des outils comme ClaudeTokenizer : le mot « developer », qui en anglais est « developer » coûte peu ou plusieurs tokens selon la langue dans laquelle on l’écrit et aussi (surtout) la version du modèle d’IA utilisée. Sur l’image, cela se voit clairement, mais juste au cas où, nous résumons :
- Pour ChatGPT (GPT-4o et GPT-5), le mot « développeur » comporte trois jetons (des-developer-ador), mais le mot « développeur » n’en coûte qu’un.
- Pour Claude (Opus 4.7) le mot « développeur » ne coûte pas moins de 9 jetons (2 dans l’Opus 4.6), mais « développeur » n’en coûte « que » 6 (1 dans l’Opus 4.6).
Que se passe-t-il ici ?
Eh bien, chaque modèle de langage utilise son propre « tokenizer », son « traducteur » d’un langage conventionnel vers le langage à jetons que le modèle de langage comprend. Et ces tokenizers privilégient précisément les langages dans lesquels ces modèles sont créés.

C’est ainsi que l’IA comprend notre façon de parler. Chaque mot est divisé en jetons et l’anglais est bien mieux compris. « développeur » ne coûte qu’un jeton dans GPT-5, mais « développeur » se décompose en trois. Mauvaise nouvelle pour les hispanophones.
En fait, l’anglais est devenu la langue officielle de l’intelligence artificielle, qu’on le veuille ou non. La raison n’est pas culturelle, mais architecturale : 95% des données d’entraînement des modèles frontières (GPT-5, Gemini 3.1, Claude Opus/Sonnet 4.7…) sont dans cette langue.
Cela fait du reste des langues des « langues étrangères », et cela oblige à payer un supplément, un tribut presque invisible lors de leur utilisation, à chaque interaction. En termes pratiques, ce qui se passe lorsque nous utilisons l’espagnol pour parler à un modèle d’IA est simple : nous utilisons plus de jetons, et donc utiliser l’espagnol est tout simplement plus coûteux que d’utiliser l’anglais lorsque nous travaillons avec un grand modèle linguistique.
Si vous souhaitez enregistrer des jetons, utilisez mieux l’anglais
La question, bien sûr, est de savoir combien cela nous coûte plus cher de parler en espagnol qu’en anglais avec ChatGPT (GPT 5.x) ou avec Claude Opus 4.7 ?
C’est difficile à dire car chaque mot et chaque phrase est différent, mais la vérité est que l’anglais est presque toujours le plus « économique ». Nous avons utilisé l’une des premières phrases de cet article pour comparer cette consommation de jetons, et en traduisant la phrase dans différentes langues et en interrogeant cette consommation de jetons pour différents modèles, les données sont claires.

Il est important de souligner que ces résultats ne sont pas concluants, mais ils montrent clairement la tendance : l’anglais est la langue la plus efficace en termes de consommation symbolique, mais attention, car l’espagnol n’est pas si mauvais et est généralement la deuxième langue la plus efficace. C’est encore plus efficace que l’anglais en Gémeaux, du moins selon l’outil consulté.
Mais en moyenne, il est normal qu’il y ait un surcoût important lors de l’utilisation de différents modèles. Une conversation avec Claude Opus 4.7 est déjà « chère » car c’est l’un des modèles les plus chers actuellement, mais en espagnol il est près de 30 % plus cher, sans oublier qu’en arabe, 76,3 % plus cher.
En fait, selon cet exemple, la différence entre Claude ou GPT-4o en termes d’efficacité est claire : le tokenizer OpenAI est « moins cher », et bien qu’il puisse y avoir des différences avec GPT-5.x, ce qui semble clair c’est qu’Anthropic a préféré « dépenser plus » pour obtenir de meilleurs résultats (ou c’est l’objectif). Les Gémeaux sont encore plus économes selon ces tests, et cela peut aussi avoir beaucoup à voir avec la qualité des réponses, même si cette question concerne un autre sujet.
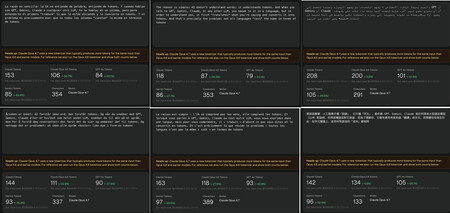
Nous avons utilisé l’un des paragraphes de cet article en espagnol et l’avons traduit avec Deepl en anglais, arabe, norvégien, français et chinois pour savoir combien de jetons l’expression « coûte » dans chaque langue. L’anglais est sans aucun doute le plus efficace
Les tokenizers avancent et évoluent. Parfois, ils le font pour nous économiser des jetons, comme cela s’est produit avec le tokenizer GPT-4o : à cette époque, OpenAI expliquait comment cet outil utilisait 1,1 fois moins de jetons lorsqu’on lui parlait en espagnol mais jusqu’à 2,9 fois moins en hindi ou 3,5 fois moins en telugu. Avec Claude Opus 4.7, c’est tout le contraire qui s’est produit : le tokenizer a été repensé et consomme plus de tokens (jusqu’à 1,35 fois plus, admettent-ils) dans le but de mieux traiter et comprendre le texte.
Votre chatbot pense (et programme) en anglais
Ici, nous devons également souligner quelque chose d’important : même si nous pouvons parler à notre chatbot préféré dans n’importe quelle langue et qu’il nous répondra dans cette langue (sauf demande contraire de notre part), les modèles d’IA « pensent en anglais ».
C’est-à-dire : lorsque vous leur parlez, ils traduisent ce que vous leur dites, puis raisonnent en anglais et enfin ils traduisent leur réponse dans la langue dans laquelle vous leur parliez. Cela consomme des jetons de raisonnement supplémentaires, mais a également un certain impact sur la latence (combien de temps il faut pour commencer à réfléchir ou à répondre au modèle). Dans des tâches complexes, cela peut clairement influencer les temps de réponse pour la simple raison que le modèle d’IA ne cesse de traduire de « sa langue officielle » (l’anglais) vers notre langue.
Cette préférence pour l’anglais est également perceptible dans les benchmarks : dans le Humanity’s Last Exam, dans lequel les modèles se voient poser toutes sortes de questions de culture générale avec plusieurs options de réponse, il est raisonnable de penser que les modèles répondent mieux en anglais car cet examen est conçu dans cette langue.

Dans les tâches de programmation, cette utilisation de l’anglais favorise également les résultats. Il existe des études spécifiques qui abordent le sujet et indiquent clairement que si vous utilisez l’IA pour programmer, ce n’est pas une mauvaise idée de lui « parler » directement en anglais. La raison reste la même que celle que nous avions évoquée : la grande majorité des données de formation à la programmation sont justement en anglais car c’était déjà de facto la « langue officielle » des programmeurs avant l’apparition de l’IA.
Il existe également diverses études qui confirment depuis des années que l’anglais est la langue la plus efficace pour converser avec des modèles d’IA, mais elles ont également souligné comment une meilleure prise en charge de plusieurs langues peut aider à rendre l’utilisation multilingue non seulement réalisable, mais efficace.

Dans cette étude de juin 2025 réalisée par des chercheurs de Microsoft, les auteurs ont déclaré simplement que : « les invites multilingues peuvent réduire l’utilisation des jetons de 20 à 40 % sans compromettre la précision, fournissant une stratégie simple et efficace pour améliorer l’efficacité de l’inférence sans avoir besoin de recyclage. »
Dans cette étude, des modèles comme Qwen ou DeepSeek ont été utilisés pour indiquer que raisonner en espagnol ou en chinois pourrait être plus efficace, mais attention, car nous insistons : chaque modèle est un monde et logiquement les modèles développés aux États-Unis ont une préférence absolue pour l’anglais en termes de données d’entraînement.
Mais alors, est-ce que j’utilise l’anglais ou puis-je continuer en espagnol ?
Si l’on regarde ces données, la conclusion semble claire : si nous le pouvons, nous devrions parler directement à l’IA en anglais. La réalité est quelque peu différente.
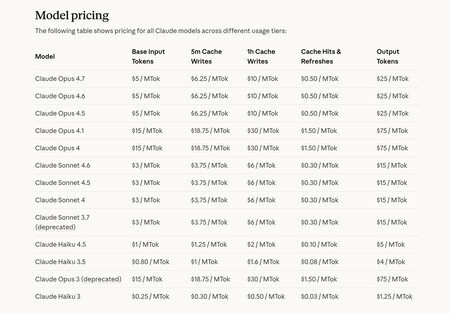
Lorsque vous utilisez des modèles d’IA via des API (vous payez ce que vous utilisez), ce n’est peut-être pas une mauvaise idée d’essayer d’utiliser l’anglais pour parler à ces modèles. Dans l’image, les prix des différents modèles Anthropic.
Surtout parce que les prix d’utilisation de l’IA ne cessent de baisser, ce qui rend le surcoût lié à l’utilisation des jetons utilisés pour parler espagnol sans importance pour un usage domestique. Ce n’est pas tout : la plupart des utilisateurs profitent de forfaits mensuels comme ChatGPT Plus ou Claude Pro (par exemple), et dans ces forfaits nous avons une sorte de « pseudo-forfait ».
Ces forfaits ne sont bien sûr pas illimités, et si nous les utilisons de manière intensive, nous rencontrerons le redoutable « désolé, vous devrez attendre jusqu’à cinq heures pour continuer à utiliser ce modèle ». Cependant, atteindre ces limites est compliqué pour une utilisation modérée, et ici l’utilisation des modèles en anglais ou en espagnol n’est pas trop importante.
Il est vrai que dans certains domaines, utiliser l’anglais présente des avantages, non seulement en termes d’efficacité (les jetons « durent » plus longtemps), mais également en termes de précision. Cela peut se produire dans des tâches plus complexes telles que la programmation, et l’utilisation d’invites en anglais peut aider à obtenir des résultats que nous ne pouvons peut-être pas obtenir en espagnol ou dans d’autres langues.

Les choses changent un peu si l’on utilise des modèles d’IA via les API de ces plateformes. Il n’y a pas de pseudo-tarifs forfaitaires ici, et vous payez pour ce que vous utilisez, donc économiser sur les jetons peut être important, surtout si nous sommes des utilisateurs intensifs (et si nous utilisons des API, c’est généralement parce que les modèles sont utilisés de manière particulièrement intensive). Là il peut être intéressant d’utiliser les modèles directement en anglais, car on le remarquera clairement dans notre poche.
À Simseo | L’« économie symbolique » est brisée : les frais forfaitaires de programmation d’IA sont mathématiquement insoutenables