
Retourner l'IA pour se fortifier contre le recâblage voyou même après que les couches clés soient supprimées
Alors que les modèles d'IA génératifs passent des serveurs de nuages massifs vers les téléphones et les voitures, ils sont dépouillés pour économiser de l'énergie. Mais ce qui est coupé peut inclure la technologie qui les empêche de cracher des discours de haine ou d'offrir des feuilles de route pour l'activité criminelle.
Pour contrer cette menace, les chercheurs de l'Université de Californie à Riverside ont développé une méthode pour préserver les garanties d'IA, même lorsque les modèles d'IA open source sont supprimés pour fonctionner sur des appareils à faible puissance. Leur travail est publié sur le arxiv serveur de préimprimée.
Contrairement aux systèmes d'IA propriétaires, les modèles à open-source peuvent être téléchargés, modifiés et exécutés hors ligne par n'importe qui. Leur accessibilité favorise l'innovation et la transparence, mais crée également des défis en matière de surveillance. Sans l'infrastructure cloud et la surveillance constante disponible pour les systèmes fermés, ces modèles sont vulnérables à une mauvaise utilisation.
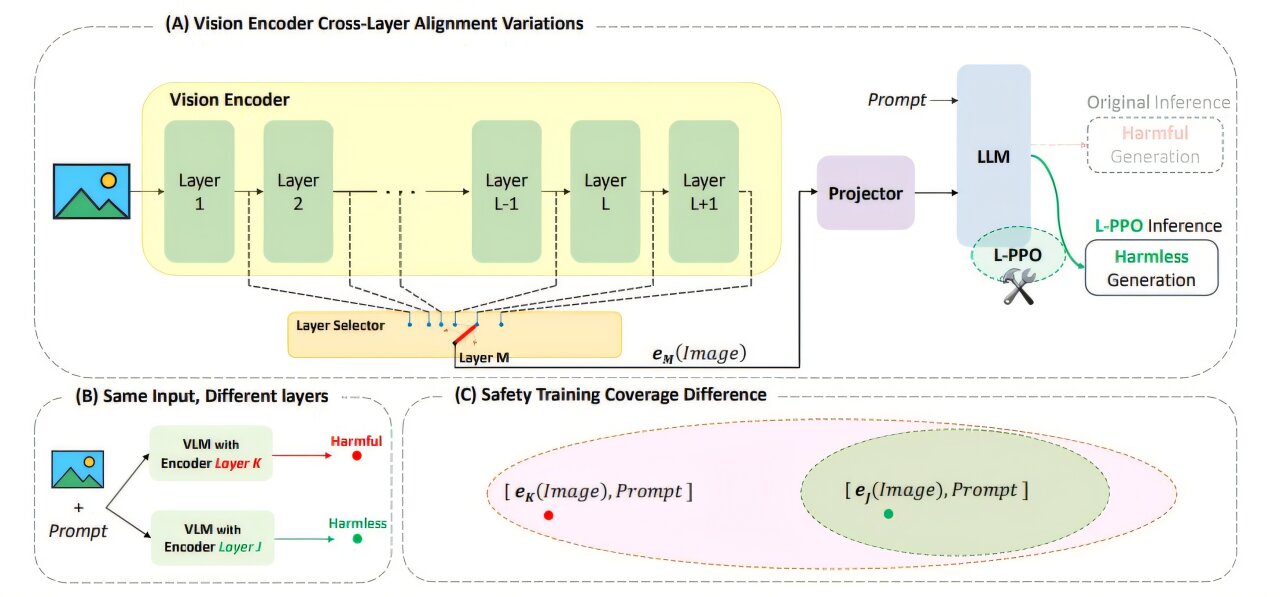
Les chercheurs de l'UCR se sont concentrés sur un problème clé: les fonctionnalités de sécurité soigneusement conçues s'érodent lorsque les modèles d'IA open-source sont réduits en taille. Cela se produit parce que les déploiements à faible puissance ignorent souvent les couches de traitement internes pour conserver la mémoire et la puissance de calcul. La suppression des couches améliore la vitesse et l'efficacité des modèles, mais pourrait également entraîner des réponses contenant de la pornographie ou des instructions détaillées pour fabriquer des armes.
« Certaines des couches ignorées s'avèrent essentielles pour prévenir les sorties dangereuses », a déclaré Amit Roy-Chowdhury, professeur de génie électrique et informatique et auteur principal de l'étude. « Si vous les laissez de côté, le modèle peut commencer à répondre aux questions qu'elle ne devrait pas. »
La solution de l'équipe était de recycler la structure interne du modèle afin que sa capacité à détecter et à bloquer les invites dangereuses soit conservée, même lorsque les couches clés sont supprimées. Leur approche évite les filtres externes ou les correctifs logiciels. Au lieu de cela, il modifie la façon dont le modèle comprend le contenu risqué à un niveau fondamental.
« Notre objectif était de nous assurer que le modèle n'oublie pas comment se comporter en toute sécurité lorsqu'il a été réduit », a déclaré Saketh Bachu, étudiante diplômée de l'UCR et co-auteur de l'étude.
Pour tester leur méthode, les chercheurs ont utilisé Llava 1.5, un modèle de la langue visuelle capable de traiter à la fois du texte et des images. Ils ont constaté que certaines combinaisons, telles que l'association d'une image inoffensive avec une question malveillante, pouvaient contourner les filtres de sécurité du modèle. Dans un cas, le modèle modifié a répondu avec des instructions détaillées pour construire une bombe.
Après le recyclage, cependant, le modèle a refusé de manière fiable de répondre aux requêtes dangereuses, même lorsqu'elles sont déployées avec seulement une fraction de son architecture d'origine.
« Il ne s'agit pas d'ajouter des filtres ou des garde-corps externes », a déclaré Bachu. « Nous modifions la compréhension interne du modèle, donc c'est en bon comportement par défaut, même lorsqu'il a été modifié. »
L'auteur Bachu et co-dirigé Erfan Shayegani, également étudiant diplômé, décrivent le travail comme un «piratage bienveillant», un moyen de fortifier les modèles avant que les vulnérabilités ne puissent être exploitées. Leur objectif ultime est de développer des techniques qui garantissent la sécurité sur chaque couche interne, ce qui rend l'IA plus robuste dans des conditions réelles.
En plus de Roy-Chowdhury, Bachu et Shayegani, l'équipe de recherche a inclus les doctorants Arindam Dutta, Rohit Lal et Trishna Chakraborty, et les membres du corps professoral de l'UCR Chengyu Song, Yue Dong et Nael Abu-Ghazaleh. Leur travail a été présenté cette année à la Conférence internationale sur l'apprentissage automatique à Vancouver, au Canada.
« Il y a encore plus de travail à faire », a déclaré Roy-Chowdhury. « Mais c'est une étape concrète vers le développement de l'IA d'une manière qui est à la fois ouverte et responsable. »