
Recherche et développement de l’IA Index 2026 : chaîne d’approvisionnement fragile et nœud TSMC
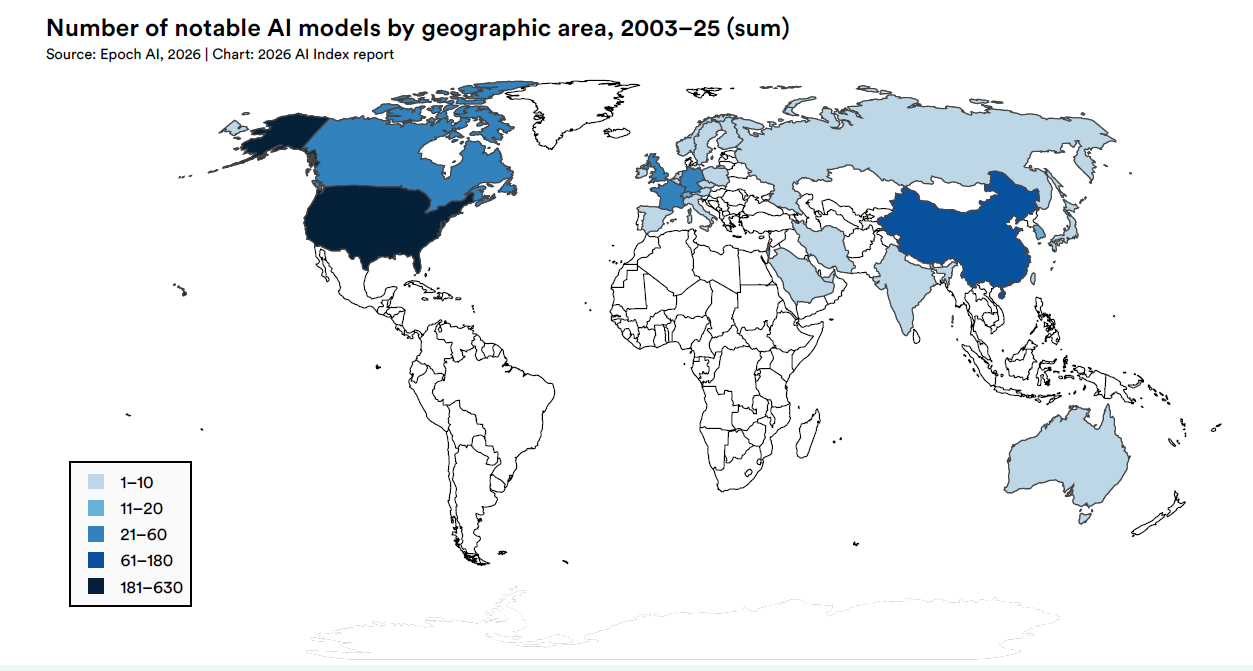
L’AI Index 2026 de Stanford, qui photographie les chiffres de la recherche et du développement, dessine un écosystème qui grandit et rétrécit en même temps. En 2025, 95 modèles « remarquables » ont été commercialisés, dont 87 conçus par l’industrie privée, et 1 seulement par des laboratoires académiques.
La concentration ne s’arrête pas au secteur : OpenAI, Google et Alibaba couvrent à eux seuls 42 des 95 modèles recensés, et l’ordinateur qui les anime passe presque entièrement d’un seul fonderie Taïwanais. La course à l’intelligence artificielle, si elle s’accélère sur les capacités, se contracte sur les sources.
Industrie 91,6 %, milieu universitaire 1 %
Les chiffres parlent d’eux-mêmes, mais il faut les lire dans l’ordre. En 2025, Epoch AI a identifié 87 modèles notables produits par l’industrie, 1 par le monde universitaire, 5 par des collaborations industrie-université. La part industrielle, qui en 2010 était d’environ 50 %, atteint en quelques années 91,58 % et s’y stabilise. Ce n’est pas une nouveauté absolue, mais c’est la photographie d’une décantation presque complète.
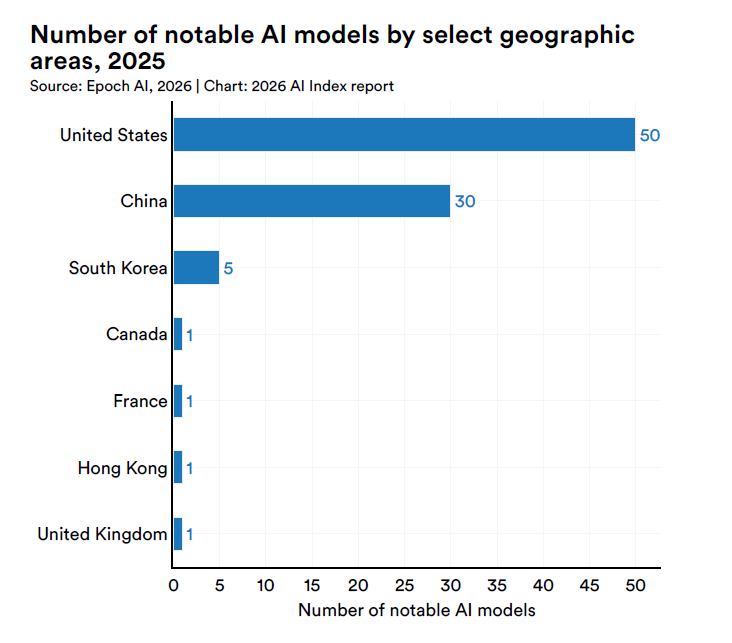
Au sein de l’industrie, la distribution est encore plus concentrée.
OpenAI avec 19 modèles, Google avec 12, Alibaba avec 11, Anthropic et xAI avec 7 chacun, DeepSeek avec 5.
Depuis 2014, Google a produit 191 modèles notables, Meta 86, OpenAI 59, Microsoft et Nvidia 42 chacun. La pyramide a une base très étroite et au sommet se trouvent un certain nombre de sujets qui peuvent être comptés sur deux mains.
Il y a une conséquence concrète pour ceux qui conçoivent les politiques, pour ceux qui investissent, pour ceux qui achètent l’IA au sein d’une organisation : les choix techniques de frontière ne sont plus distribués, ce sont des décisions d’un petit groupe.
Quand OpenAI décide de ne pas publier le code de la formation, quand Anthropic cesse de déclarer les paramètres, quand Google ne publie plus la durée de la formation, ces décisions ne restent pas internes au laboratoire, elles remodèlent l’épistémologie de tout le secteur.
Opacité par défaut : 80 modèles sur 95 sans code de formation
Sur le plan de la transparence, les données de l’IA Index montrent un renversement de direction qui n’a pas encore été suffisamment discuté. En 2025, sur 95 modèles notable80 ont été publiés sans le code de formation correspondant, contre 4 qui ont publié le code complet en open source. En 2020, les deux catégories étaient presque équivalentes, aujourd’hui le rapport est de 20 pour 1. Le modèle d’accès dominant est devenu l’API, qui en 2025 a collecté 45 des 95 versions.
Les paramètres, les ensembles de données et la durée de la formation ne sont de plus en plus déclarés par les laboratoires frontières. Le nombre de mesures est resté proche du billion pendant trois années consécutives, car les laboratoires frontaliers ont cessé de les déclarer et la dernière mesure stable remonte à 2023.
L’ordinateur d’entraînement peut être estimé indirectement, et là l’indice confirme que la croissance ne s’est pas arrêtée. Mais la capacité de ceux qui effectuent des recherches externes, des audits et des évaluations de sécurité est structurellement limitée, car les trois piliers de la reproductibilité scientifique (code, données, procédure) ne sont plus disponibles.
S’ouvre ici un paradoxe qu’il convient de regarder en face : les modèles les plus performants sont les moins transparents, et le secteur dans lequel le « savoir comment ça marche » est le plus demandé est celui où il est de moins en moins déclaré.
Une seule fonderie pour presque toutes les puces IA dans le monde
Le chapitre sur le calcul de l’AI Index 2026 contient l’une des données les plus importantes de l’ensemble du rapport, et il s’agit d’une donnée géopolitique. La capacité de calcul mondiale pour l’IA a augmenté de 3,3 fois par an depuis 2022, pour atteindre environ 17,1 millions d’équivalents H100. Nvidia couvre plus de 60 % de cette capacité, Google et Amazon une grande partie du reste, Huawei une part modeste mais croissante.
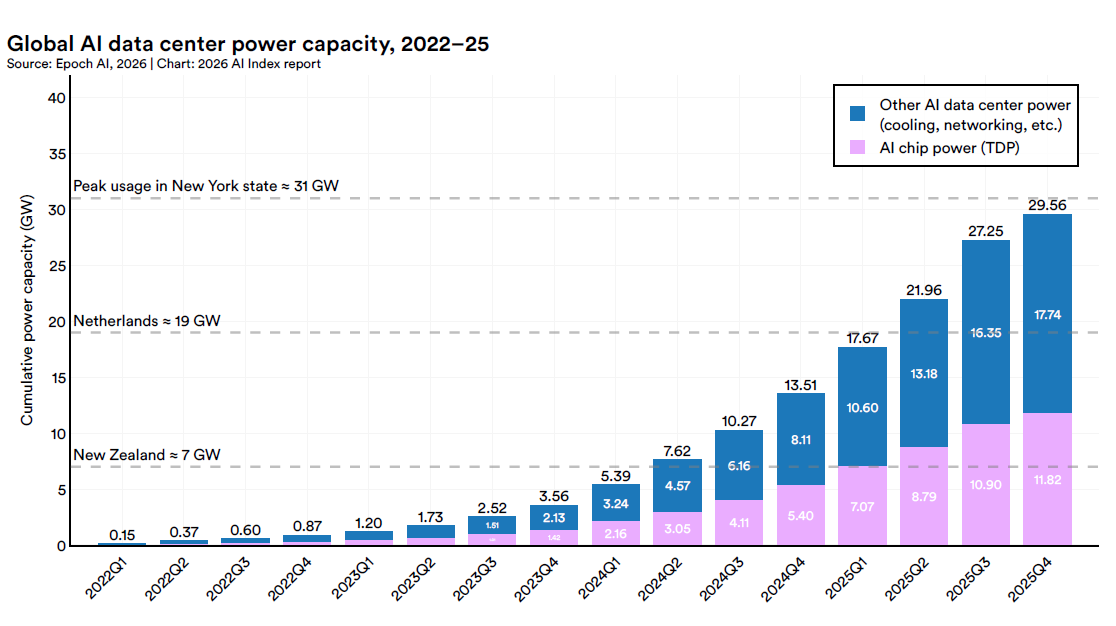
Mais le vrai problème se situe en amont. Presque toutes les puces IA haut de gamme sont fabriquées par TSMC, la Taiwan Semiconductor Manufacturing Company. Une seule entreprise, sur une seule île, est le nœud par lequel passe toute la chaîne d’approvisionnement mondiale de l’intelligence artificielle. L’expansion de TSMC aux États-Unis a commencé ses opérations en 2025, mais son ordre de grandeur reste périphérique au cœur manufacturier taïwanais.
Appeler cela une dépendance est un euphémisme, c’est une monoculture industrielle. Et comme toutes les monocultures, elle est efficace tant que le contexte tient. Le conflit commercial entre les États-Unis et la Chine, les tensions sur le détroit, l’éventuelle interruption logistique pour des raisons climatiques ou géopolitiques, tout passe par ce même goulot d’étranglement. L’IA Index ne fait pas de projections de scénarios, il enregistre simplement les données. Le lecteur peut et doit compléter le raisonnement.
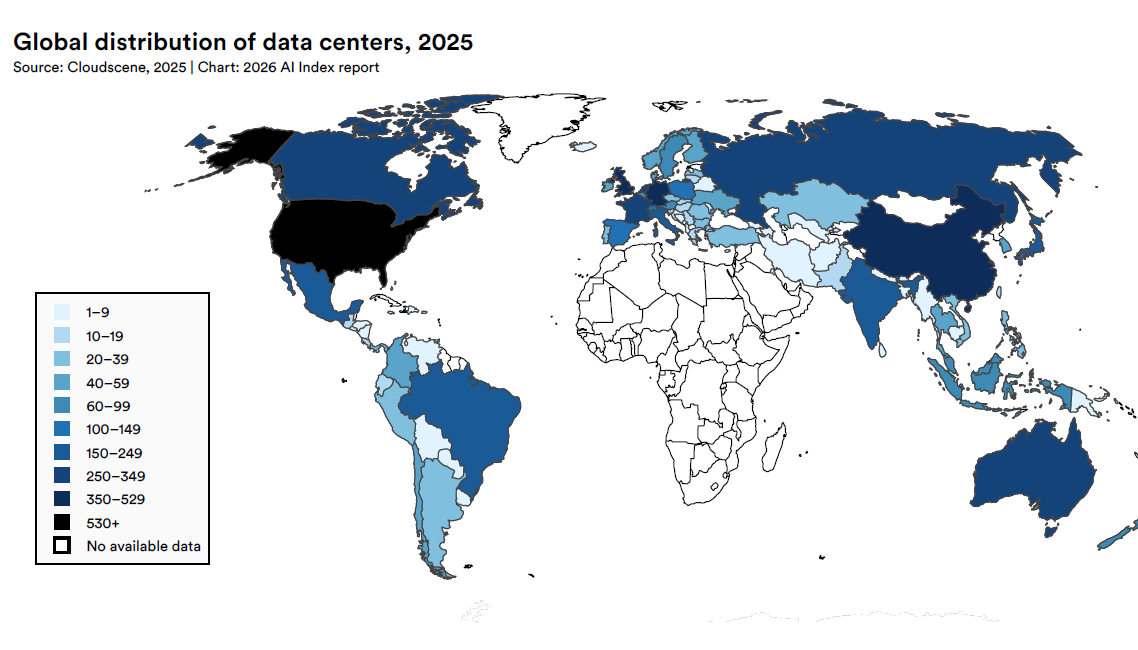
Data center de 29,6 GW : une infrastructure invisible qui consomme comme un État
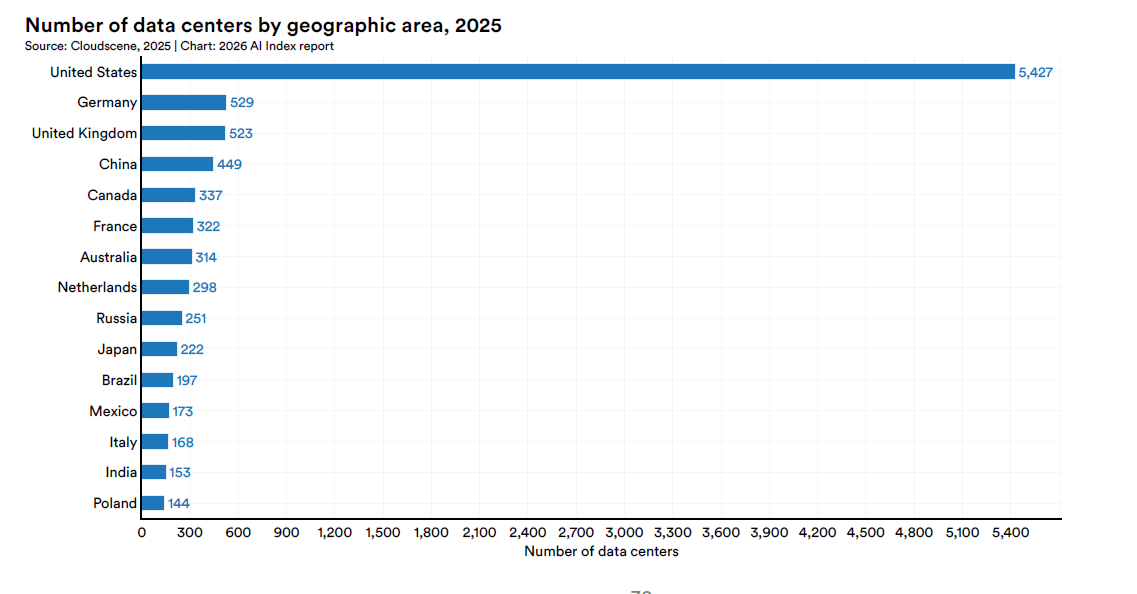
Même si les modèles et les critères de référence ont été discutés, l’infrastructure physique qui les soutient a pris des dimensions comparables à celles des systèmes étatiques. Les États-Unis abritent 5 427 centres de données, soit plus de dix fois n’importe quel autre pays au monde.
La capacité électrique des centres de données IA a atteint 29,6 GW au quatrième trimestre 2025, comparable à la consommation de l’État de New York aux heures de pointe et supérieure aux besoins des Pays-Bas.
Les données sur les émissions en sont le corollaire inévitable. La formation Grok 4, lancée par xAI en 2025, a produit environ 72 816 tonnes d’équivalent CO2. Pour donner une échelle : cela représente plus de 13 mille ans de vie humaine moyenne, soit plus que la somme des émissions durée de vie d’un millier de voitures. En 2012, la formation AlexNet a produit 0,01. En treize ans, l’ordre de grandeur a progressé de sept zéros.
Il existe une exception qui mérite attention, quoique isolée. DeepSeek v3, modèle chinois comparable en taille aux autres frontièrea produit environ 597 tonnes, ce qui est bien inférieur à celui des modèles de taille similaire. La raison réside dans le mix énergétique, l’efficacité du matériel, la durée et l’architecture de la formation. Toutes les échelles ne produisent pas le même impact, et c’est un des leviers sur lesquels le secteur peut encore intervenir avant de normaliser les numéros de préfixes géologiques.
Sur le front de mer, la situation est similaire. La production annuelle de GPT-4o, estimée à environ 1,3 à 1,6 millions de kilolitres, pourrait couvrir les besoins en eau potable de 12 millions de personnes. Quand on parle d’« IA durable », on s’arrête rarement à quantifier les dénominateurs.
L’écart entre les sexes qui n’a pas bougé depuis quinze ans
Au milieu de nombreuses courbes exponentielles, l’AI Index rapporte un chiffre resté stable de 2010 à 2025 : la répartition par sexe parmi les chercheurs et inventeurs en IA.
Au Brésil, en Corée du Sud et au Japon, plus de 80 % des talents identifiés sont des hommes. L’Italie, avec 29,5 % de femmes parmi ses meilleurs chercheurs en IA, se classe parmi les pays où la représentation féminine est relativement plus élevée, avec l’Arabie saoudite (32,3 %), l’Australie (30,1 %) et le Canada (29,6 %). Aucun pays ne s’approche de la parité.
La donnée qui pèse le plus n’est pas le pourcentage lui-même, mais sa stabilité temporelle. De 2010 à 2025, le ratio hommes/femmes dans la recherche en IA est resté essentiellement inchangé dans presque tous les pays mesurés. Alors que le reste du secteur a connu une croissance exponentielle, cette dimension n’a pas bougé.
La croissance du talent global n’a produit aucun rééquilibrage, elle n’a fait que creuser proportionnellement le même déséquilibre qui existait il y a quinze ans.
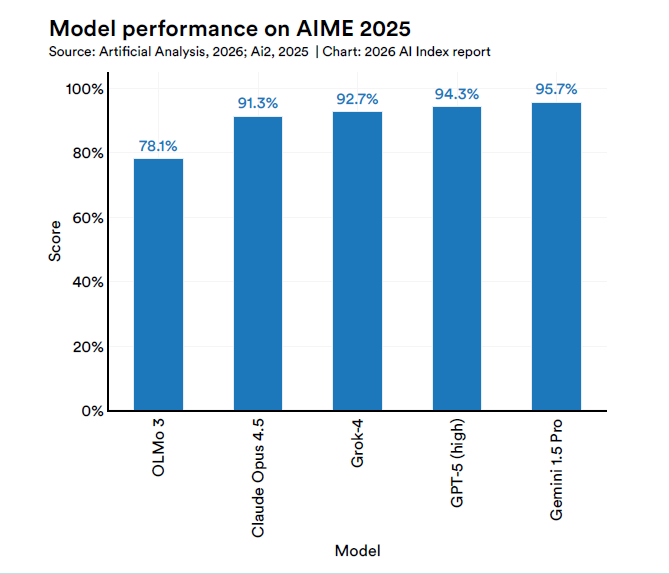
OLMo contre Grok : quand moins c’est aussi plus
Un signal à contre-tendance vient du côté de l’efficacité. OLMo 3.1 Think 32B, publié par l’Allen Institute for AI, possède environ 32 milliards de paramètres, soit près de 90 fois moins que le billion déclaré de Grok 4. Pourtant, sur plusieurs tests de référence, les deux obtiennent des résultats comparables. L’Indice attribue la performance aux techniques taillela déduplication et la conservation des données, plutôt qu’à l’échelle brute.
C’est un fait qui s’adresse à ceux qui planifient les stratégies d’entreprise, et pas seulement à ceux qui effectuent des recherches. La trajectoire dominante du secteur, qui consiste à accroître les paramètres, les calculs et l’énergie, n’est pas la seule voie viable vers la capacité. La qualité des données, la méthodologie post-formation, les techniques d’optimisation architecturale ont déjà démontré qu’elles peuvent réduire le coût de calcul de deux ordres de grandeur sans un effondrement proportionnel des performances.
Pour les entreprises évaluant des investissements dans l’IA, c’est la question opérationnelle qui compte : avez-vous vraiment besoin du modèle le plus large, ou avez-vous besoin du modèle le plus adapté au problème ?
Une supply chain mondiale à repenser
L’AI Index 2026, dans le chapitre sur la recherche et le développement, livre une carte qui mérite d’être lue dans son intégralité avant de revenir aux titres sur les modèles et les benchmarks.
Les protagonistes sont de moins en moins nombreux, les informations disponibles diminuent en quantité et en qualité, l’infrastructure physique se concentre en un seul point du monde, l’empreinte environnementale augmente à une vitesse plus rapide que celle de l’efficacité du matériel.
Toute organisation prévoyant une adoption significative de l’IA devrait examiner ces quatre axes ensemble, et non séparément. Le choix du fournisseur, le niveau de dépendance aux API propriétaires, la résilience de la supply chain matérielle à laquelle vous êtes lié, le coût environnemental que vous inscrivez implicitement dans votre périmètre d’émissions. Il s’agit de décisions de gouvernance, pas seulement d’approvisionnement. Et la fenêtre pour les réaliser consciemment se rétrécit, tout comme la fenêtre pour les investissements s’élargit.
La question que l’IA Index laisse ouverte, sans la formuler explicitement, est de savoir si un écosystème aussi concentré peut tenir ses propres promesses de progrès sur le long terme. Jusqu’à présent, la concentration a produit de la vitesse. Le prochain test sera de savoir si cela peut également produire de la fiabilité.