

Qualité des données et IA en pharma : le défi à gagner
Depuis des années, l’industrie biopharmaceutique accumule d’énormes volumes de données. Aujourd’hui, alors que l’industrie s’oriente vers un avenir axé sur l’IA, ces données doivent devenir un véritable atout stratégique.
L’étude Veeva « L’état des données, de l’analyse et de l’IA dans la biopharmacie commerciale » souligne que si 95 % des sociétés biopharmaceutiques poursuivent activement des initiatives d’IA dans le marketing et les ventes, presque toutes (89 %) ne parviennent pas à faire évoluer plus de la moitié de leurs projets pilotes. Ce manque de réussite est souvent dû à un manque de préparation : la même étude révèle en effet que 67 % des chefs d’entreprise abandonnent les projets d’IA en raison d’une mauvaise qualité des données.
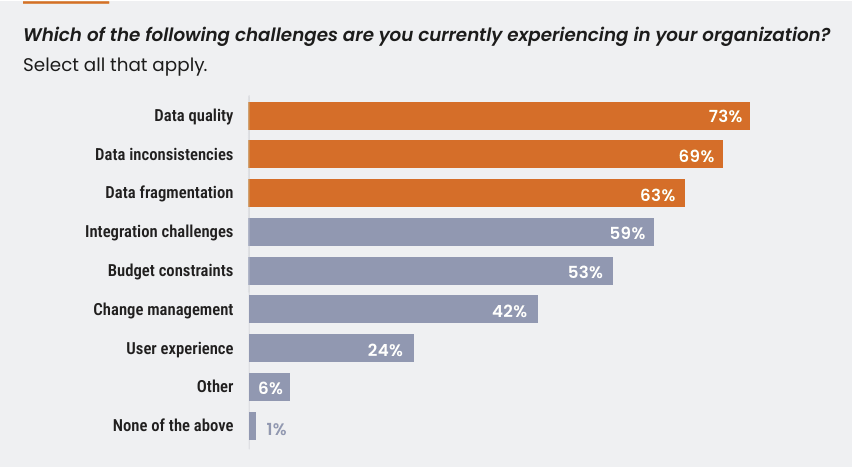
Disposer d’informations claires et précises est crucial pour toute initiative d’IA : en fait, 73 % des chefs d’entreprise déclarent que la mauvaise qualité des données est le principal obstacle à l’évolutivité de l’intelligence artificielle. Cependant, la stratégie adoptée par la plupart des entreprises repose toujours sur une tentative d’harmoniser les informations provenant de silos distincts. Cette approche n’est pas durable, surtout avec l’augmentation constante des volumes.
Les data scientists avec qui j’ai parlé estiment qu’ils passent jusqu’à 80 % de leur temps à préparer, nettoyer et transformer les données pour les rendre utilisables.
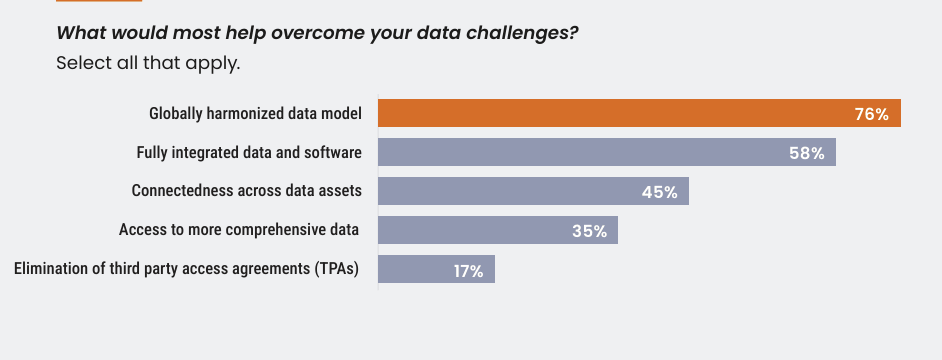
Pour que l’intelligence artificielle passe de projets pilotes infructueux à une création de valeur pour l’organisation, la question de la qualité des données doit être abordée. Cela nécessite de passer d’une gestion de l’information fragmentée à une base de données harmonisée à l’échelle mondiale, soutenue par une approche proactive de gestion des données.
La mauvaise qualité des données est le plus grand obstacle au développement de l’IA
La dépendance du secteur à l’égard de données incomplètes et fragmentées a alimenté un scepticisme croissant : 96 % des dirigeants estiment que leurs données ne sont pas prêtes à être adoptées par l’IA. Cet impact est également évident sur le terrain : 72 % des entreprises envisagent d’utiliser l’IA pour accompagner les équipes locales en synthétisant les mises à jour des HCP lors de la préparation des appels, mais les niveaux d’adoption restent encore limités.
Les équipes de terrain ne parviennent souvent pas à adopter les recommandations de l’IA parce qu’elles estiment que les données sous-jacentes ne sont pas suffisamment précises. Au moment où un modèle de prochaine meilleure action suggère une tactique basée sur un changement d’affiliation survenu trois mois plus tôt, le pronostiqueur ou MSL non seulement ignore la suggestion, mais a tendance à remettre en question la fiabilité de l’ensemble de la plateforme.
Ce manque de confiance est l’une des principales raisons pour lesquelles de nombreux gestionnaires de données biopharmaceutiques hésitent à adopter des modèles d’action « next-best-action ».
Erika Husing, analyste d’affaires, opérations commerciales chez GSK, explique : « Si nous ne faisons pas confiance aux données, comment pouvons-nous en tirer des conclusions ? Il est essentiel de surmonter le scepticisme qui les entoure aujourd’hui et de promouvoir une plus grande confiance en elles.
L’impact réel des processus manuels de gestion des données
Un autre gaspillage de ressources provient des innombrables heures passées par les équipes à cartographier manuellement les spécificités locales et les types de professionnels de santé selon les normes mondiales. Cela crée une énorme charge administrative à chaque fois que vous entrez sur un nouveau marché.
Dans l’une des 20 plus grandes sociétés biopharmaceutiques, les data scientists demandent à la force de vente d’examiner les données de segmentation client tous les six mois. Cette tâche détourne les équipes sur le terrain de leur rôle principal qui consiste à établir des relations avec les clients.
Peut-être encore plus frustrant est le fait que les sociétés biopharmaceutiques estiment que seulement 10 % de leurs données sont suffisamment propres et suffisamment conservées pour être utilisées, et que seulement 1 % est réellement exploité pour des cas d’utilisation pertinents. Alors que les volumes continuent d’augmenter, les sociétés biopharmaceutiques ne peuvent plus se permettre de résoudre les problèmes de qualité des données au niveau local.
Une base de données harmonisée à l’échelle mondiale permet à l’IA d’évoluer
La gestion des données est intrinsèquement complexe, car les bureaux locaux les traitent de différentes manières pour se conformer aux réglementations régionales. Le résultat est un système fragmenté, dans lequel les informations ne sont pas uniformes d’un pays à l’autre, ce qui complique les analyses transnationales et l’application de l’intelligence artificielle.
Une base de données harmonisée à l’échelle mondiale garantit la cohérence et l’accessibilité des données sur tous les marchés. Avant d’adopter un modèle de données mondial, Bayer AG était confrontée à des définitions de données incohérentes et à l’absence d’une vue client unique sur tous les marchés. « Notre paysage mondial des données était fragmenté : chaque pays s’appuyait sur des sources différentes », explique Stefan Schmidt, responsable des capacités numériques chez Bayer. « Pour avoir une vue complète, nous avions besoin d’un registre de clients unifié. »
Pour Bayer, une base de données centralisée et précise a non seulement fourni une source de données unique et fiable pour les prestataires et les établissements de soins de santé, mais a également accru la confiance dans la fiabilité des analyses de l’IA. En conséquence, les équipes de terrain sont moins susceptibles de remettre en question le système et plus susceptibles de suivre les recommandations de l’IA.
Une base de données harmonisée à l’échelle mondiale fournit l’architecture permettant de rendre les données utilisables dans toute l’entreprise, mais le véritable gain d’efficacité vient de la qualité de la source elle-même. À partir d’une base de données plus solide, l’accent passe de la correction des erreurs au maintien de niveaux d’excellence constants en maintenant des niveaux d’excellence constants grâce à des processus de curation d’agent.
Garantir des données de haute intégrité grâce à des activités de conservation de données humaines et agents
Pendant des décennies, l’industrie s’est appuyée sur une gestion manuelle et humaine des données pour maintenir des niveaux de qualité adéquats. Il existe aujourd’hui une opportunité d’améliorer la qualité de millions de documents en combinant l’expérience humaine avecconservation de données agentique.
Les agents d’IA peuvent effectuer des tâches spécifiques et répétitives de conservation des données, telles que le croisement d’informations ou l’identification des doublons. Des agents spécialisés analysent quotidiennement 100 % des enregistrements, tandis qu’un gestionnaire de données humain examine ensuite les résultats.
Étant donné que les agents fonctionnent en permanence, ils détectent les changements au fur et à mesure qu’ils se produisent, repérant souvent les signaux avant qu’ils ne soient enregistrés dans les bases de données publiques. Par exemple, ils peuvent surveiller les affiliations à un niveau détaillé et identifier les changements. Cette précision permet à l’IA de fournir des recommandations sur les meilleures actions basées sur des données à jour, évitant ainsi l’écueil courant des équipes de terrain recevant des informations préalablement connues, comme le changement de lieu d’un cabinet médical visité la semaine précédente.
En transférant une grande partie de la charge de conservation des données vers des agents autonomes, il est possible de réduire la dépendance aux mises à jour envoyées par les équipes de terrain et de passer d’un modèle réactif – qui alimente souvent le scepticisme quant à la qualité des données – à une approche proactive.
Avec la conservation des données des agents et la supervision humaine, des données vérifiées, fiables et de haute qualité
LE’conservation de données agentiquecombiné à la supervision humaine, permet d’obtenir des données vérifiées, fiables et de haute qualité nécessaires pour faire évoluer efficacement l’intelligence artificielle
Vous ne pouvez pas escalader ce en quoi vous n’avez pas confiance, et vous ne pouvez pas faire confiance à ce qui n’a pas été harmonisé. Une base de données cohérente à l’échelle mondiale permet aux entreprises biopharmaceutiques de se concentrer sur l’utilisation des données, au lieu de passer du temps à les nettoyer. C’est précisément cette approche qui transformera les plus sceptiques de l’IA en partisans.