
Plus de caméras, plus de problèmes? Pourquoi l'apprentissage en profondeur a encore du mal avec la détection humaine 3D
L'estimation avec précision de la pose humaine a été parmi les premières tâches adressées par l'apprentissage en profondeur. Les premiers modèles comme OpenSose se sont concentrés sur la localisation des articulations humaines comme points clés 2D dans les coordonnées d'image. Plus tard, Google a proposé Medioppe, suivi de Yolopose, qui a attiré une attention majeure et est largement adopté en raison de son efficacité et de sa précision.
Naturellement, la frontière suivante était d'estimer les poses humaines en 3D – prédictant les emplacements (x, y, z) des articulations dans un cadre de référence global. Étant donné que l'image unique à 3D est un problème mal posé, la tâche a promis de devenir plus facile à utiliser plusieurs caméras. Cependant, malgré des années de recherche, l'estimation de la pose multi-personnes 3D multi-visualités reste étonnamment difficile.
Rompre le puzzle multi-visualités
L'estimation de la pose multi-vues multi-vues est une collection de multiples sous-problèmes. Jusqu'à récemment, la plupart des études estimaient d'abord les points clés 2D indépendamment de toutes les images multi-visualités utilisant Mediapipe ou Yolopose, puis correspondent aux joints correspondants à travers les vues, suivis d'une correspondance de personnes, puis ont utilisé des paramètres de la caméra pour trianguler les points clés 2D pour enfin obtenir la 3D.
Cependant, une lacune majeure de ces pipelines à plusieurs étapes est que les erreurs à chaque étape se multiplient. De plus, de telles approches n'ont pas réussi à tirer parti des indices visuels des images multi-visualités, car la première étape elle-même a rejeté la plupart des informations sur les pixels, et l'ensemble du pipeline restant reposait simplement sur les points clés 2D estimés à partir d'un détecteur standard.
Apprentissage de bout en bout: un changement de paradigme
Récemment, certains chercheurs ont déplacé leur attention vers une question importante: toute la tâche peut-elle être supervisée de bout en bout? Voyons quels seront les défis dans une telle approche.
Premièrement, un tel paramètre nécessitera le modèle pour traiter des entrées d'image multi-visualités entières, conduisant à des dépenses de calcul élevées, contrairement aux approches précédentes qui ont enregistré le calcul en éliminant simplement la plupart des informations visuelles. Deuxièmement, comment le modèle peut-il apprendre la triangulation géométrique dans un cadre différentiel de bout en bout? Enfin, comme ce modèle régresserait directement les joints 3D, comment se généraliserait-il aux nouveaux paramètres?
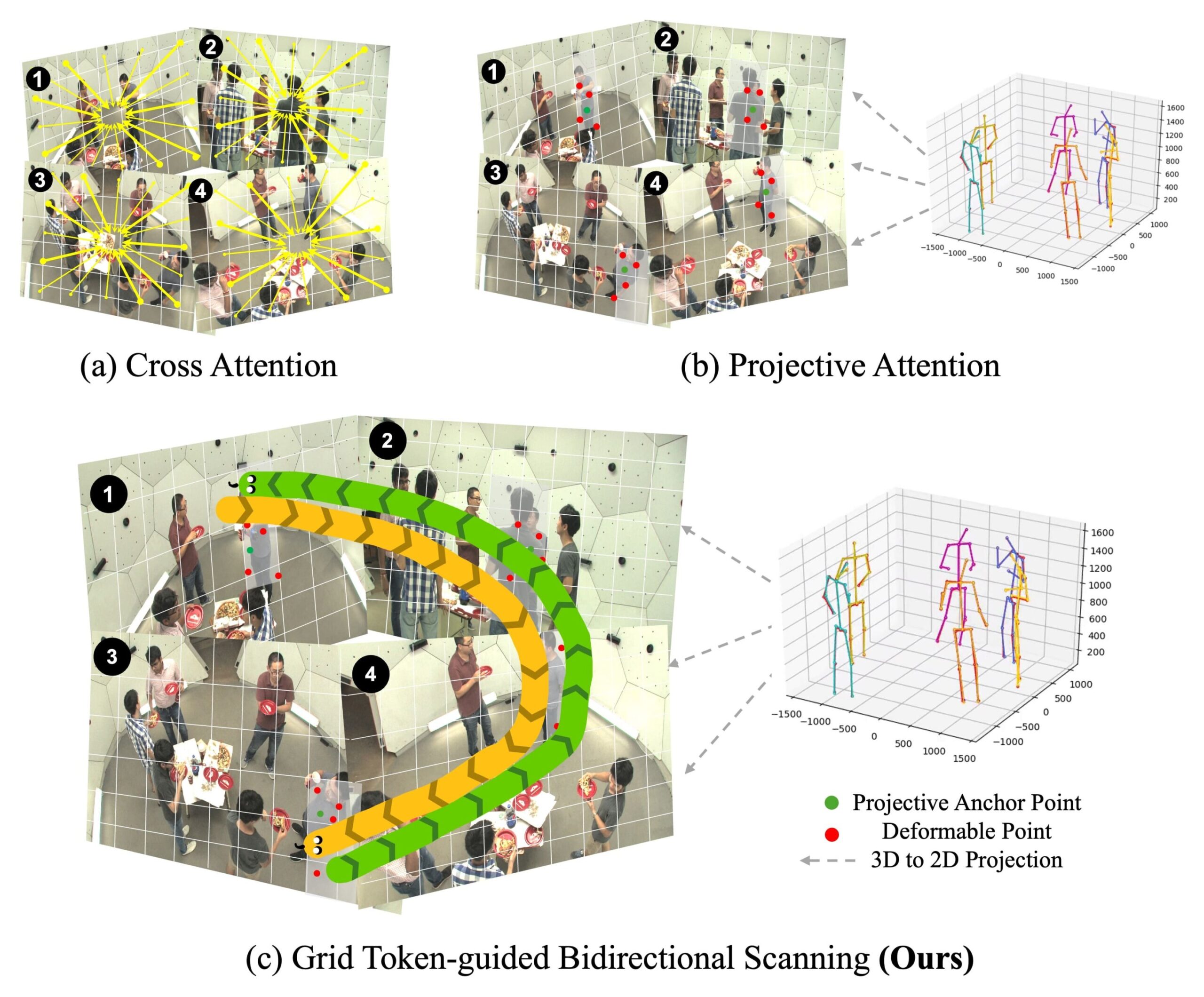
. Ces blocs exploitent l'attention projective et la modélisation de l'espace d'état pour affiner progressivement les points clés, avec des points clés 3D finaux estimés via une triangulation géométrique. Crédit: les auteurs")
Quelques études récentes, dont la triangulation apprenable, le MVP et le MVGFORMER, ont exploré ce problème. La triangulation apprenable a proposé deux approches de triangulation – une algébrique et un volumétrique. Surtout, les deux approches sont différenciables de bout en bout, ce qui permet une optimisation directe de la métrique cible.
MVP a utilisé cette méthode et a directement régressé les poses humaines 3D multi-visualités sans s'appuyer sur des tâches intermédiaires. Plus précisément, MVP représente les articulations squelettes comme des incorporations de requête apprenables et les permet de s'occuper progressivement et de raisonner sur les informations multi-visualités des images d'entrée pour régresser directement les emplacements articulaires 3D réels. Une contribution clé est le mécanisme d'attention géométriquement guidé, appelé attention projective, pour fusionner plus précisément les informations de la vision de la vision pour chaque joint.
Récemment, MVGFORMER a soulevé une préoccupation importante concernant les modèles de régression comme MVP – qu'ils ont une très faible généralisation.
Exposé: la crise de la généralisation
MVGFORMER a démontré que les modèles antérieurs surdimensionnés sur les ensembles de données de formation, c'est-à-dire, si le nombre de caméras est réduit ou augmenté pendant les tests, les scores AP25 ont montré une grande baisse, indiquant que même un gain d'informations visuelles ne pouvait pas être utilisé efficacement par ces modèles. Deuxièmement, à mesure que les positions ou les orientations de la caméra sont modifiées, ou lorsque ces modèles sont évalués sur des données transversales, elles montrent également un sur-ajustement élevé.
MVGFORMER a abordé ceci en utilisant des transformateurs qui combinaient la triangulation géométrique dans un paramètre basé sur l'apprentissage, avec ses modules d'apparence efficacement en utilisant efficacement les informations visuelles qui ont été rejetées dans des pipelines multi-étages antérieurs.
Généralisation forte: la métrique gagnante de MV-SSM
S'appuyant sur ce problème de recherche, et pour mieux résoudre le problème de généralisation, nous avons proposé MV-SSM – un nouveau modèle pour l'estimation de la pose humaine 3D à l'aide de la modélisation de l'espace d'état multi-vues. MV-SSM a été présenté à la conférence IEEE / CVF sur la vision par ordinateur et la reconnaissance des modèles (CVPR 2025) qui s'est tenue à Nashville, du 11 au 15 juin. MV-SSM modélise explicitement la séquence spatiale conjointe à deux niveaux distincts: le niveau de fonctionnalité des images multi-visualités et le niveau de point de clé de la personne.
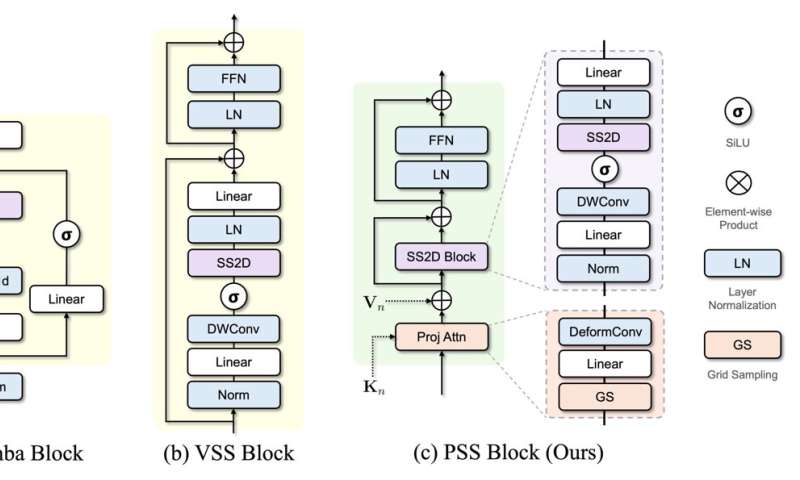
Nous proposons un bloc d'espace d'état projectif (PSS) pour apprendre une représentation généralisée des arrangements spatiaux conjoints en utilisant la modélisation de l'espace d'état. De plus, nous modifions la numérisation traditionnelle de Mamba en un scanning bidirectionnel guidé par le jeton (GTBS) efficace, qui fait partie intégrante du bloc PSS.
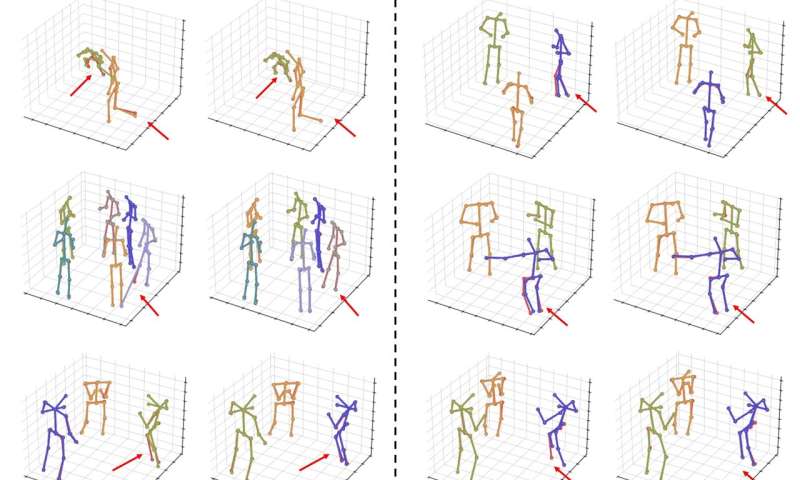
Plusieurs expériences démontrent que MV-SSM atteint une forte généralisation, surpassant les modèles de pointe: + 24% sur le réglage à trois caméras difficiles dans CMU Panoptic, + 13% sur les dispositions de caméras variables et + 38% sur le campus A1 dans les évaluations de données croisées.
Calibrage connu: le talon d'Achille de la pose 3D Estimation
Cependant, comme les modèles précédents, une limitation majeure de MV-SSM suppose que les paramètres de la caméra sont connus. Bien que impressionnant, estimer les poses humaines 3D qui ne sont pas limitées à un arrangement de caméras spécifiques, lié à des scènes spécifiques des données de formation, ou qui nécessitent un nombre fixe de caméras restent un défi majeur, qui, s'il est résolu, a un énorme utilitaire industriel.
Cette histoire fait partie de Science X Dialog, où les chercheurs peuvent signaler les résultats de leurs articles de recherche publiés. Visitez cette page pour plus d'informations sur la boîte de dialogue Science X et comment participer.