
Optimisation du transport, de la confiance et de la tutelle
L’ère de l’information est construite sur les mathématiques. De trouver le meilleur itinéraire entre deux points, la prévision de la charge future sur un réseau électrique national ou la météo de demain à l’identification des options de traitement idéales pour les maladies, les algorithmes partagent une structure commune: ils prennent des données d’entrée, les traitent à travers une série de calculs et fournissent une sortie.
Les algorithmes de plus en plus sophistiqués, souvent composés de millions de lignes de code. Et plus il y a d’étapes qu’un modèle passe avant de présenter une solution, plus elle est coûteuse dans le nombre d’unités informatiques physiques, de temps et d’énergie requise.
L’optimisation de ces modèles mathématiques est au cœur du travail de l’unité d’apprentissage automatique et de science des données (MLDS) à l’Institut Okinawa des sciences et de la technologie (OIST). Dirigée par le professeur Makoto Yamada, l’unité s’efforce de débloquer le plein potentiel de l’apprentissage automatique (ML) et d’améliorer l’efficacité, d’optimiser non seulement la science des données mais aussi l’éducation et la production savante au sein de l’unité grâce à une hiérarchie distribuée.
Réduction des coûts
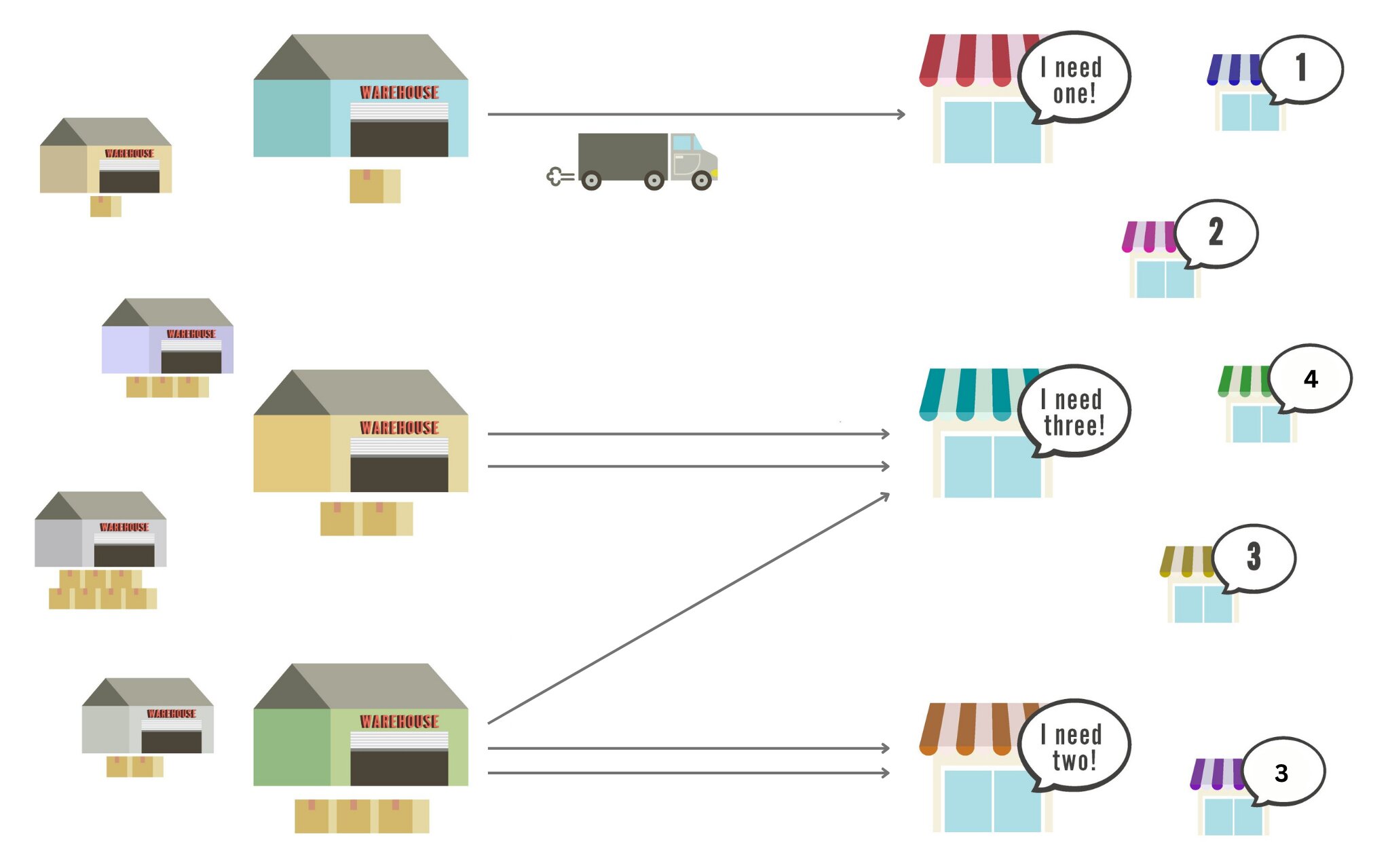
Imaginez que vous êtes chargé de déplacer des marchandises de plusieurs entrepôts à différents magasins. Chaque entrepôt a une quantité différente de marchandises disponibles, et chaque magasin nécessite un nombre différent de marchandises. Pour minimiser les coûts de transport, vous devez déterminer l’itinéraire le plus efficace entre les différents entrepôts et magasins qui font baisser la distance totale requise pour déplacer toutes les marchandises nécessaires.
Il s’agit de la configuration de base de problèmes de transport optimaux (OT) qui, bien que simple en surface, sont difficiles à grande échelle: à mesure que le nombre de points de distribution (entrepôts et magasins) augmente, il en va de même pour la complexité – et le coût – de l’algorithme.
« Nous nous concentrons sur l’optimisation et la conception de nouveaux outils pour résoudre des problèmes de transport optimaux », explique le professeur Yamada. L’OT est au cœur de la science des données comme moyen de découvrir la méthode la plus efficace de déplacement des données entre les points de distribution.
Considérons les données d’expression des gènes à cellule unique comme exemple: « Ces données peuvent être très dimensionnelles avec un grand nombre d’échantillons – nous pouvons étudier 20 000 gènes avec 100 000 cellules. Computer la relation entre chaque gène dans le contexte de la découverte de médicaments ou de la classification de la maladie est extrêmement complexe, surtout si nous voulons entraîner la ML sur les données.
« L’un de nos objectifs est de résoudre avec précision l’OT dans de tels cas avec une complexité linéaire: un coût de calcul qui ne fait que l’échelle du nombre de points de distribution. »
Pour la Conférence internationale sur les représentations de l’apprentissage (ICLR 2025), cinq articles des MLD ont été acceptés. Deux de ces modèles de fonctionnalités qui se concentrent spécifiquement sur la réduction du coût OT en ML coûteux en calcul. Les deux papiers sont disponibles sur le arxiv serveur de préimprimée.
Un article introduit une méthode OT qui capture mieux les relations de classe en comparant les distributions de fonctionnalités complètes au lieu de moyennes simples, améliorant à la fois la précision et l’efficacité.
Le deuxième article relève le défi d’un apprentissage non supervisé efficace sur des données non marquées. Dans ce contexte, les modèles ML doivent apprendre à la fois la structure des données (comment chaque caractéristique et échantillon sont liées) et les règles de mesure de la similitude, ici quantifiées à travers la distance de Wasserstein, qui capture l’effort minimal nécessaire pour transformer une distribution de données dans une autre.
Pour surmonter le coût prohibitif associé à l’informatique, l’équipe introduit une nouvelle méthode basée sur la distance d’arbre-wasserstein, où au lieu de calculer les distances à travers une grille complète de tous les points de distribution, les deux échantillons (comme les cellules) et les caractéristiques (comme les gènes) sont cartographiés sur des nœuds dans un arbre de ramification, où deux nœuds sont connectés exactement par un seul chemin. Cette structure réduit considérablement le nombre de comparaisons requises, améliorant ainsi considérablement le coût de calcul.
")
Expansion de l’accessibilité
Un autre objectif clé de l’unité consiste à améliorer la fiabilité et la sécurité des modèles en réduisant les erreurs et le potentiel de préjudice pendant le développement, l’utilisation et la sortie du modèle. Un défi ici est la reconnaissance ouverte des ensembles, qui fait référence à la façon dont les intrants qu’un modèle peut rencontrer après la formation sont désordonnés et sont souvent entièrement hors de propos.
Le Dr Mohammad Sabokrou, qui mène les recherches de l’unité sur ML digne de confiance, explique: « Si vous utilisez un modèle ML pour détecter différents types de voitures à partir d’images, et que vous lui donnez une photo d’un tigre, il devrait savoir qu’il ne peut pas classer l’image – il est problématique s’il classait confidentiellement les objets qu’il ne devrait pas être capables. »
L’enseignement d’un modèle pour tracer cette frontière tout en reconnaissant des objets connus dans des configurations inhabituelles, comme une voiture vue sous différents angles, est difficile. La détection des échantillons qui ne sont pas pertinentes ou différentes des données de formation, également appelées échantillons hors distribution, est généralement considérée comme un problème de détection d’anomalies.
Une approche que l’unité explore ici est l’apprentissage contrastif, où un modèle apprend à rédiger des entrées similaires et à éloigner les autres dissemblables (c’est-à-dire l’anomalie) dans un espace caractéristique.
« La détection des anomalies est étroitement liée à des tâches telles que la détection de nouveauté, la détection d’irrégularité, la reconnaissance de l’ouverture et la détection hors distribution. Bien que ces tâches soient de nature similaire, elles diffèrent principalement dans leurs établissements de test », explique le Dr Sabokrou.
« Nous travaillons à unifier les mesures à travers ces différents types de tâches, ce qui permettrait un partage de connaissances beaucoup plus important. »
L’unité s’efforce également d’améliorer les modèles dignes de confiance grâce à diverses attaques qui exposent leurs vulnérabilités. Les attaques contradictoires utilisent des ajustements subtils pour provoquer des erreurs.
Les attaques de porte dérobée exploitent des déclencheurs cachés dans les données de formation, qu’ils soient introduits délibérément ou hérités involontairement par des corrélations parasites ou un biais sociétal: un modèle peut déduire à tort les liens familiaux sur des photos en fonction de l’éclairage ou du biais contre les groupes sous-représentés à partir d’ensembles d’entraînement non inclusifs.
Et enfin, les attaques d’inférence de l’adhésion testent si une entrée donnée se trouvait dans un ensemble de formation d’un modèle pour détecter ou exploiter les fuites de données, avec des implications majeures pour la confidentialité et la sécurité.
Ces attaques peuvent révéler si un modèle de dépistage du cancer apprend à tort des artefacts comme les barres d’échelle d’image, ou si les modèles génératifs reproduisent du matériel protégé par le droit d’auteur. Ensemble, ces stratégies fournissent un diagnostic puissant pour améliorer la sécurité et la fiabilité des systèmes d’IA.
")
Promouvoir la croissance
La science des données est à la base de la plupart des domaines scientifiques et, en tant que tels, l’amélioration des méthodes par lesquelles les chercheurs peuvent extraire les connaissances des données améliorent l’efficacité du processus scientifique. Et avec l’explosion dans l’utilisation générale de l’IA, la réduction du coût de calcul et la maximisation de la sécurité et de la fiabilité du modèle sont devenues d’autant plus importantes.
Le principe d’efficacité imprègne l’unité, qui se caractérise par une hiérarchie plate et une approche distribuée du mentorat. D’une part, le professeur Yamada encourage les membres de l’unité à être des auteurs correspondants de leurs articles: « C’est bon pour votre carrière et pour votre apprentissage. C’est pourquoi c’est souvent nos post-doctorants qui assument ce rôle, afin qu’ils obtiennent l’expérience. »
Dans la même veine, le mentorat est délégué à travers l’unité, plutôt que centré sur le professeur Yamada, avec des post-doctorants et des scientifiques du personnel généralement chargés de superviser directement les étudiants diplômés et les stagiaires – bien que le professeur Yamada reste à la portée de tous, et il s’attend à chaque projet.
« C’est beaucoup plus efficace à apprendre en faisant. De plus, j’aime parler », dit-il. De même, le Dr Sabokrou est motivé par la collaboration, travaillant en étroite collaboration avec les stagiaires, les entreprises, les anciens collègues et les chercheurs externes du monde entier. « Vous construisez naturellement un réseau à travers votre carrière universitaire et vous vous aidez mutuellement des connaissances diffuses et contribue aux progrès. »
La culture de l’unité plate et à haute confiance porte ses fruits, avec quatre des cinq articles acceptés pour l’ICLR 2025 par des stagiaires. Et en prenant un flux constant de stagiaires universitaires et en engageant des ressources dans diverses activités de sensibilisation des sciences, telles qu’un café en cours pour les lycéens d’Okinawan et la populaire école d’été d’apprentissage automatique, qui a vu l’année dernière plus de 200 participants du monde entier. Yamada et l’unité promulguent leur engagement envers la science grâce à leur travail fondamental.
Comme il le dit, «l’éducation est le meilleur investissement à long terme pour la science et la société. Notre objectif est de maximiser l’efficacité de cet investissement».