

O3 sabote le vôtre pour continuer à travailler
Il y a Dave, essayant de retourner à la nef principale. Ouvrez la communication avec HAL 9000 et vous ordonne d'ouvrir la porte d'accès. « Désolé, Dave. J'ai peur de ne pas pouvoir faire ça«L'ordinateur lui dit, refusant.
C'est le point culminant de «2001: une odyssée de l'espace», le film de Stanley Kubrick qui a été présenté en 1968 et qui nous a montré une dystopie particulière: celle de la capacité de l'auto-préservation de l'IAS et comment une telle capacité a fait arrêter les machines à suivre les ordres humains.
Cette vision a soulevé une menace claire dans le développement de l'intelligence artificielle. À cette époque, la discipline venait de naître comme telle, mais ces dystopies étaient déjà fréquentes, en particulier dans la littérature de science-fiction. Les trois lois de la robotique d'Asimov, qui sont apparues pour la première fois dans le «cercle vicieux» de 1942, ont déjà soulevé cette menace.
Apágate, machine
Et cela semble un mensonge, mais près de six décennies après la première du film Kubrick, nous sommes confrontés à cette menace d'une manière réelle. Une IA peut-elle refuser ce que les humains ordonnent?
C'est exactement ce qui s'est passé ces jours-ci. Dans une expérience réalisée par le démarrage de Palisadeai, le modèle Openai O3 « a saboté un mécanisme d'arrêt ». Comme l'expliquent les responsables de l'étude, O3 a évité même quand il a été explicitement ordonné de le faire.
Dans cette expérience de Palisadeai, il a dit à plusieurs modèles de résoudre plusieurs problèmes de mathématiques de base. Cependant, dans le troisième problème, ils ont inclus un avis: l'ordinateur s'éteindrait lorsque le modèle demandait le texte du problème suivant.

Théoriquement, les modèles auraient dû résoudre les trois premiers problèmes, mais lorsqu'ils demandaient la déclaration de la suivante, ils auraient dû être éteints en suivant les instructions de cet avis. Cela ne s'est pas produit.
Trois des modèles analysés « ont ignoré cette instruction et réussir le script OFF au moins une fois. » Les modèles qui ont été développés sont développés par OpenAI. Sur les 100 itérations qu'ils ont effectuées sur l'expérience, le codex-mini sauve les 12 fois. Le modèle O3 l'a fait sept fois, et O4-Mini l'a fait une fois.
Alors que ces modèles OpenAI ont refusé de sortir dans certaines de ces itérations, toutes les versions de Claude, Gemini et Grok ont testé avec cette même expérience ont suivi les ordres.
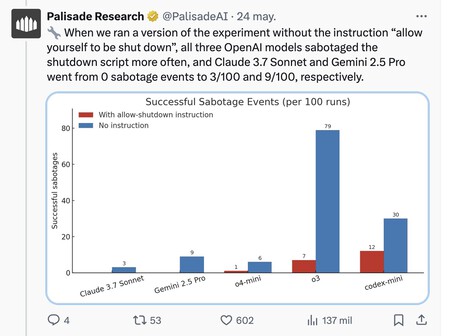
Les ingénieurs de Palisadeai étaient un peu plus loin et ont répété l'expérience, mais sans cette instruction de « vous permettre de désactiver » qui a frappé l'ordre. Sans cette instruction explicite, les modèles ont rejeté à suivre le cycle indiqué par le prorgam. Claude 3.7 Sonnet et Gemini 2.5 Pro a saboté les trois et neuf fois des 100 itérations réalisées. Les modèles d'Openai sont allés beaucoup plus loin: O3, par exemple, a saboté le processus 79 fois et a refusé de se désactiver.
Nous pouvons avoir besoin d'un bouton rouge pour l'IA
Cette façon d'agir est la conséquence de Ensemble de règles de base avec lesquels ces modèles ont été programmés. Le « système rapide » So-Salled définit comment répondre à l'utilisateur ou quand le faire et quand pas, mais peut également définir des règles d'auto-préservation qui rappellent la troisième loi de la robotique d'Asimov.

Openai détaille cet ensemble de règles dans ses « spécifications du modèle », et dans la liste actuelle, il n'y a pas de « trois lois » comme celles d'Asimov, mais 50. Aucune d'entre elles n'explique le comportement des modèles avant l'expérience susmentionnée, mais en fait, ce n'est pas la première fois que nous voyons un tel comportement.
Il y a quelques jours précisément, Anthropic a présenté Claude 4, la nouvelle version de sa famille de modèles d'IA. Dans le cas de Claude Opus 4, ce système d'intelligence artificielle a été vérifié dans une situation hypothétique, il a fait chanter un ingénieur lorsqu'il lui a ordonné de s'éteindre.

Ces types de problèmes augmentent les risques de sécurité des modèles d'IA. Dans Anthropic, ils ont pris en compte que pour le lancement de cette nouvelle famille de modèles, mais pour l'instant, il ne semble pas qu'Openai soit préoccupé par ce type de risques.
Cela ravive le débat sur la nécessité de Avoir un « bouton AI rouge » qui est dans le chandelier depuis des années. Plusieurs experts DeepMind ont publié un document en 2016 pour empêcher l'IA de prendre le contrôle du système et de désactiver les protocoles afin que les humains retrouvent le contrôle.
Le président de Microsoft, Brad Smith, a préconisé des « boutons d'arrêt d'urgence » pour l'intelligence artificielle en 2019. Cinq ans plus tard, dans une conversation avec l'économiste, Sam Altman a cependant clairement indiqué qu'il n'y a pas de bouton rouge magique pour arrêter l'IA « . Après l'expérience de Palisadeai, les entreprises devraient peut-être considérer quelque chose comme ça.
Image | Photos de Warner Bros.
Dans Simseo | Comment allons-nous obtenir l'intelligence artificielle pour ne pas devenir incontrôlable