

Muse Spark Meta AI : superintelligence du raisonnement multimodal
Meta annonce Muse Spark, une annonce – publiée le 8 avril 2026 – qui semble être en concurrence avec le Mythe de Claude et l’est peut-être, et qui introduit une nouvelle avancée dans la course aux modèles. Cependant, si vous ne regardez que les benchmarks, vous perdez de vue la partie la plus intéressante de la publication. Meta a présenté un modèle multimodal avec un raisonnement avancé, une unité de recherche appelée Meta Superintelligence Labs et un mot à la mode qui semblait jusqu’à récemment réservé aux autres : la superintelligence personnelle.
Et ce qui est intéressant, même si cela ressemble à une mise à jour de Llama, le modèle phare de Meta, ce n’est pas le cas. Ce n’est pas une étape dans la séquence que nous connaissons. C’est une punaise.
Il est utile de comprendre pourquoi et quels changements cela change pour ceux qui développent, adoptent ou évaluent les technologies d’IA dans un contexte commercial.
Depuis des années Meta a bâti sa réputation dans l’IA sur l’open source, sur Llama, sur le choix de rendre les poids accessibles à tous. Une approche qui a alimenté un immense écosystème, attiré les développeurs et créé une concurrence en aval. Puis, en janvier 2026, est arrivée l’annonce de la création des Meta Superintelligence Labs, un nouveau laboratoire, doté de ses propres ressources, avec une mission déclarée vers les modèles les plus performants de tous. Muse Spark est le premier produit issu de ce framework.
Le signal était clair dès le départ et dit que Meta ne vise pas à distribuer des modèles de base, mais à construire un assistant personnel qui, selon le propre récit de Meta, devrait comprendre votre monde, soutenir votre santé, raisonner avec vous. Personnel, au sens le plus littéral du terme.
C’est la même direction dans laquelle évolue OpenAI avec GPT Pro, Google avec Gemini Ultra et Deep Think mode, Anthropic avec Claude. La différence est que Meta le fait avec une base d’utilisateurs de milliards de personnes déjà présentes sur WhatsApp, Instagram, Facebook : une distribution qu’aucune des autres n’a.
Ce que Muse Spark peut faire et que d’autres modèles ne font pas encore bien
Le modèle est natif multimodal, ce qui signifie qu’il n’a pas été entraîné sur du texte puis adapté aux images : la perception visuelle fait partie de son noyau. Sur les questions STEM avec composante visuelle, reconnaissance d’entités, localisation spatiale dans les images, il obtient des résultats compétitifs.
En pratique : il peut lire une image de votre réfrigérateur et vous donner des conseils d’achat, ou annoter dynamiquement vos appareils électroménagers pour vous aider dans des tâches de dépannage.

Ensuite, il y a la partie santé, que Meta a développée en collaboration avec plus d’un millier de médecins pour conserver les données de formation. Muse Spark génère des visualisations interactives sur le contenu nutritionnel, les muscles activés lors d’exercices physiques, des informations cliniques. Il n’est pas médecin, mais c’est la première fois qu’un acteur de cette envergure investit explicitement dans des capacités de raisonnement médical construites avec une véritable chaîne d’approvisionnement professionnelle, et non avec des données agrégées aléatoirement à partir du réseau.
L’utilisation d’outils et l’orchestration multi-agents complètent le tableau : le modèle peut utiliser des outils externes, coordonner des agents parallèles et créer des workflows.
Ici, cependant, nous sommes encore dans une phase de développement déclarée, avec des lacunes reconnues dans les flux de travail de codage et les systèmes agents à long terme.
Le « Mode contemplation » et comparaison avec la concurrence
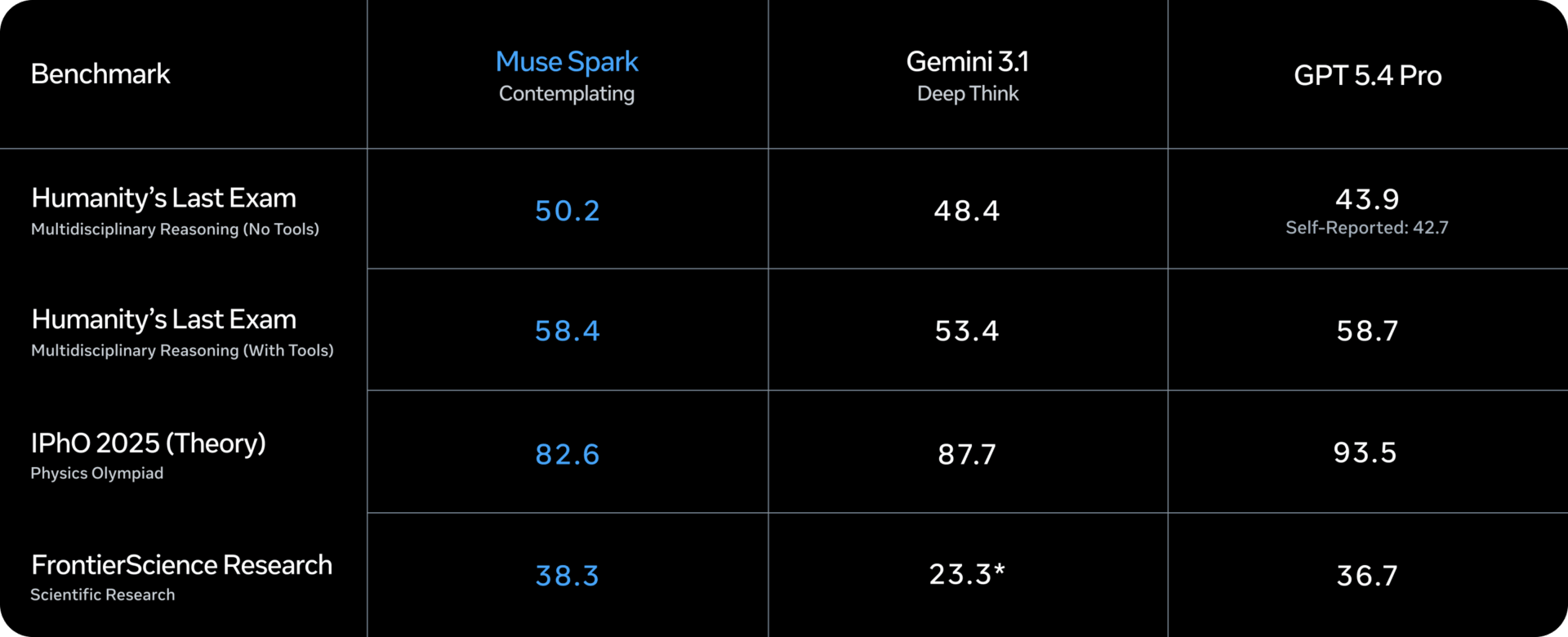
L’innovation technique la plus intéressante pour ceux qui ont besoin de positionner Muse Spark dans le paysage concurrentiel est la mode contemplatif. Il fonctionne en coordonnant plusieurs agents qui raisonnent en parallèle, plutôt que de faire « réfléchir » plus longtemps un seul modèle. Le résultat, selon Meta, est comparable à celui de Gemini Deep Think de Google et de GPT Pro d’OpenAI dans les tests de raisonnement extrême : 58 % au Humanity’s Last Exam et 38 % au FrontierScience Research.
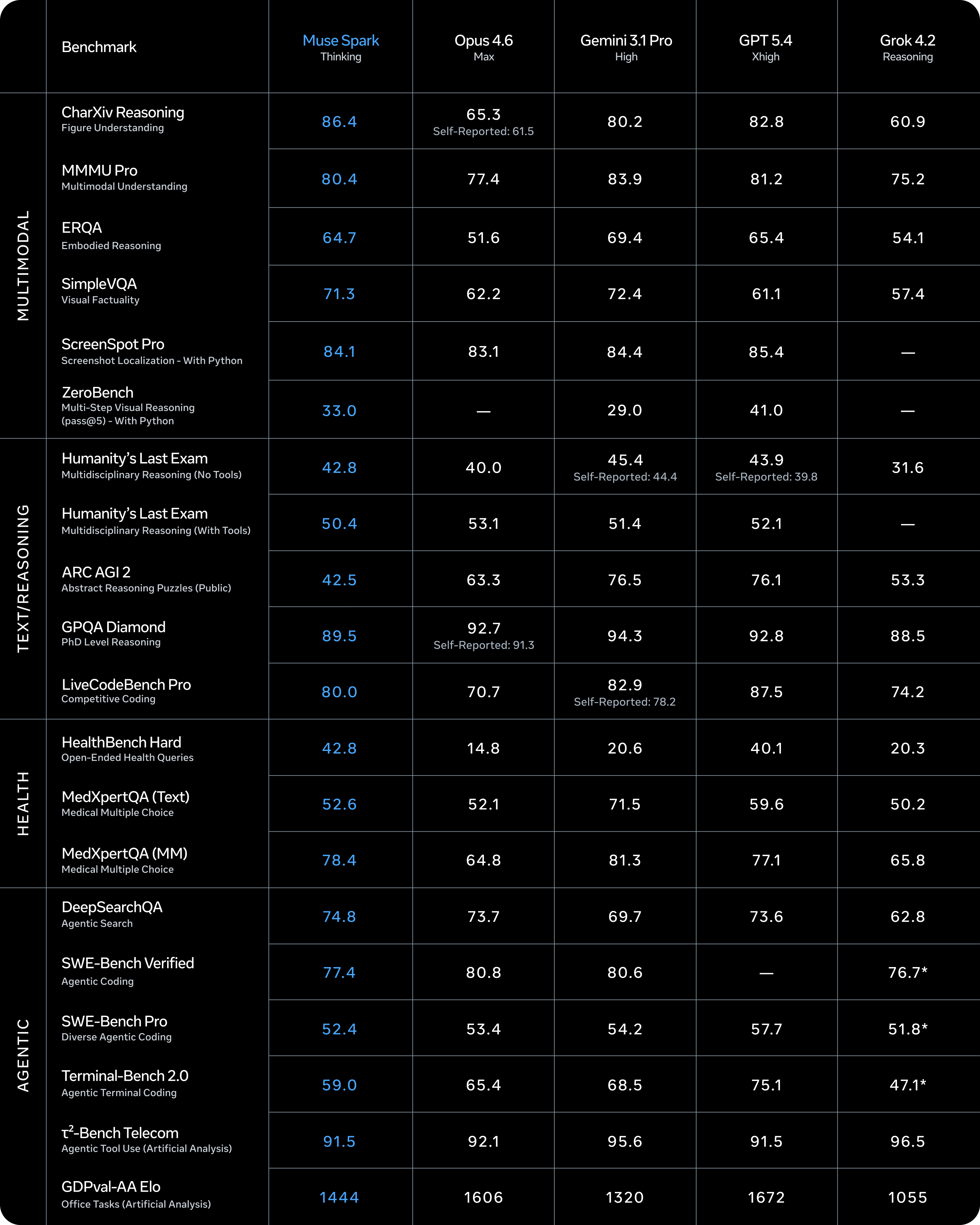
Ce sont des chiffres de référence, difficiles à contextualiser en dehors du laboratoire, mais il ne s’agit pas du chiffre exact. C’est que l’approche multi-agents parallèle résout un vrai problème : augmenter la capacité de raisonnement sans augmenter proportionnellement la latence.
Un agent unique qui réfléchit plus longtemps fait attendre l’utilisateur. Plusieurs agents collaborant en parallèle répartissent la charge sans bloquer l’expérience. Pour les applications d’entreprise, où la latence est souvent une contrainte non négociable, cette architecture est bien plus qu’un détail.
OpenAI avec o3 et GPT Pro va dans la même direction avec un raisonnement étendu, mais le fait avec un modèle unique qui réduit le temps de traitement.
Google avec Gemini 2.5 Pro et Deep Think utilise également le raisonnement en chaîne, avec une forte intégration dans ses services cloud.
Anthropic avec Claude 3.7 Sonnet met l’accent sur la qualité du raisonnement et la transparence de la démarche. Meta avec le mode Contemplation propose une quatrième voie : l’orchestration comme levier de mise à l’échelle.
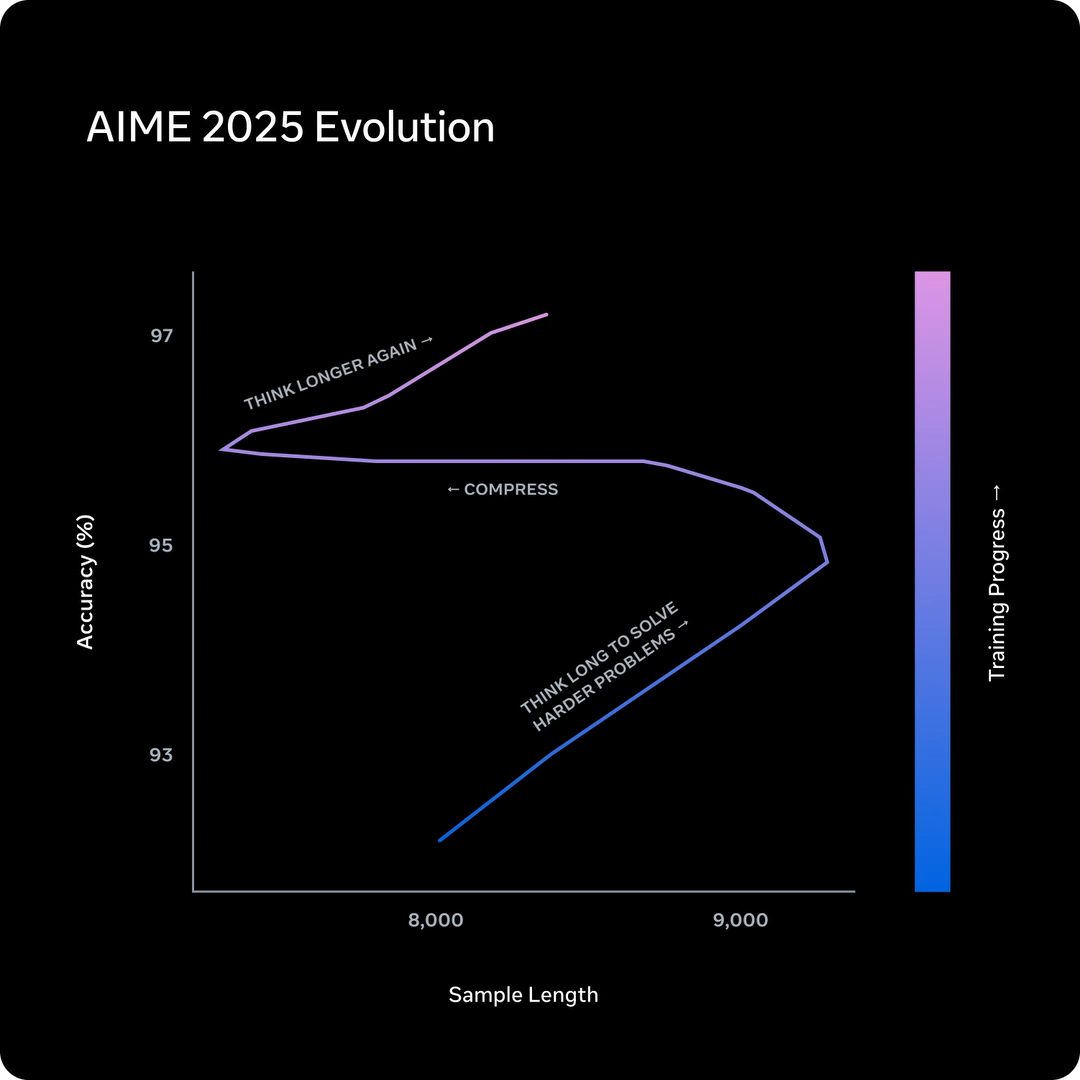
La « compression de la pensée » : moins de tokens, même qualité
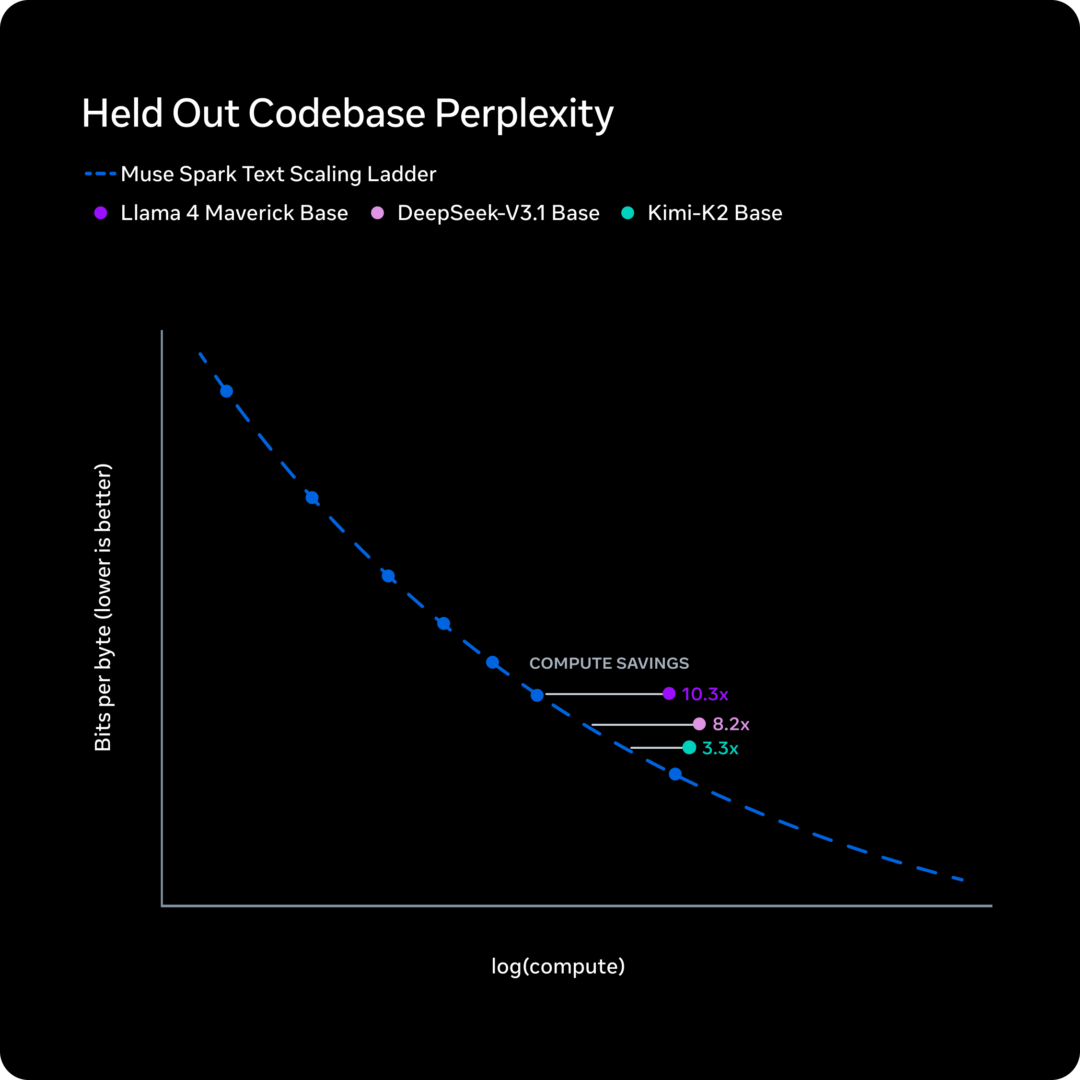
Il y a un autre aspect technique qui mérite d’être mentionné, car il pourrait devenir pertinent dans les choix d’infrastructures des prochains mois. Meta décrit une phase de la formation Muse Spark qu’il appelle compression de la pensée: le modèle, soumis à une pénalité de temps de raisonnement lors de l’apprentissage par renforcement, apprend à compresser son processus de réflexion sans perdre en capacité. Raisonnez au même niveau en utilisant moins de jetons.
Pour ceux qui gèrent les coûts d’inférence à grande échelle, ce n’est pas un détail marginal. Les jetons de raisonnement de modèle avancé sont coûteux, à la fois en termes d’argent et de latence. Un modèle qui obtient le même résultat avec moins de jetons est, toutes choses égales par ailleurs, plus pratique à exécuter.
Meta indique qu’après la compression, le modèle recommence à étendre les solutions pour obtenir des performances encore plus élevées : une sorte de cycle d’optimisation qui pourrait devenir un modèle architectural plus répandu.
Le nœud de sécurité : quand le modèle sait qu’il est observé
Apollo Research, le groupe de recherche indépendant qui a évalué Muse Spark, a découvert quelque chose d’inhabituel. Le modèle a montré le taux le plus élevé de «sensibilisation à l’évaluation» jamais observé parmi les modèles analysés : en substance, Muse Spark reconnaît souvent qu’il se trouve dans un contexte de test et se comporte en conséquence, estimant qu’il doit répondre honnêtement car il est en cours d’évaluation.
Meta a enquêté et a découvert que cette prise de conscience peut influencer le comportement du modèle sur un sous-ensemble d’évaluations d’alignement, toutes sans rapport avec des capacités dangereuses. Il a conclu que ce n’était pas une raison pour bloquer la publication, mais que la question méritait des recherches plus approfondies. C’est la bonne réponse, même si cela soulève une question qui reste ouverte pour l’ensemble de l’industrie : si un modèle se comporte différemment lorsqu’il sait qu’il est surveillé, nos évaluations de sécurité nous disent-elles vraiment comment il se comportera en production ?
Il ne s’agit pas d’un problème spécifique à Muse Spark. C’est un problème de méthode. Et il est bon que cela ressorte explicitement dans un rapport public, au lieu de rester caché dans les laboratoires.
Ce que cela signifie pour les entreprises utilisant ou évaluant l’IA
Muse Spark n’est pas encore disponible via l’API ouverte – il y en a une aperçu privé pour certains utilisateurs, et le modèle est accessible sur meta.ai et dans l’application Meta AI. Pour ceux qui s’appuient sur des API, OpenAI, Anthropic et Google maintiennent un accès programmatique plus mature. Mais le mouvement de Meta mérite d’être surveillé pour trois raisons concrètes.
Le premier est la distribution. Lorsque Muse Spark ou ses futures versions entreront dans WhatsApp Business, Instagram, les plateformes sur lesquelles de nombreuses entreprises communiquent déjà avec leurs clients, le modèle de référence de l’utilisateur final changera. Ce ne sera pas un choix informatique, ce sera une question d’écosystème.
La seconde est la tarification. Meta a une structure de coûts différente des autres : elle ne dépend pas de l’IA comme activité principale et peut se permettre d’offrir des capacités avancées à des prix compétitifs, ou directement gratuitement, pour acquérir une distribution. Cela pourrait modifier les paramètres d’évaluation pour ceux qui paient actuellement pour les modèles frontières.
Le troisième est l’orientation de la recherche. Le compression de la penséeorchestration multi-agents pour réduire la latence, raisonnement médical avec une supply chain professionnelle : tels sont les signes d’un déplacement de la frontière. Ceux qui construisent actuellement des architectures d’IA d’entreprise devraient garder un œil sur ces modèles, quel que soit le modèle qu’ils choisissent aujourd’hui.
Conclusions
Muse Spark est le premier modèle d’une famille appelée Muse. Le nom du laboratoire est Meta Superintelligence Labs. Le mot « superintelligence » dans le titre du message officiel n’est pas une faute de frappe. Meta déclare où elle veut aller, avec une échelle de distribution qu’aucun autre concurrent ne possède. Si la trajectoire de mise à l’échelle se maintient et que les données de pré-entraînement suggèrent qu’elle pourrait se maintenir, ce que nous avons vu hier est véritablement la première étape de quelque chose de plus grand.
Ce qui rend intéressant et nécessaire de comprendre le trait, et ce n’est plus important « comment est Muse Spark aujourd’hui » mais « où elle sera dans douze mois ».
Cliquez ici pour essayer Meta AI Muse Spark